यह जानने के तरीके खोज रहे हैं कि गुणात्मक डेटा का विश्लेषण कैसे करें एक्सेल . में ? तो यह आपके लिए सही लेख है। जब डेटा गिना नहीं जा सकता है और संख्यात्मक मानों का उपयोग करके व्याख्या करना कठिन है, फिर डेटा गुणात्मक है . हम इसे गुणात्मक इकट्ठा कर सकते हैं डेटा फ़ोकस समूह चर्चाओं, गहन साक्षात्कारों, वाक्यों की पूर्णता, शब्द संघों, आकस्मिक वार्तालापों आदि से।
Excel में गुणात्मक डेटा का विश्लेषण करने के लिए 8 चरण
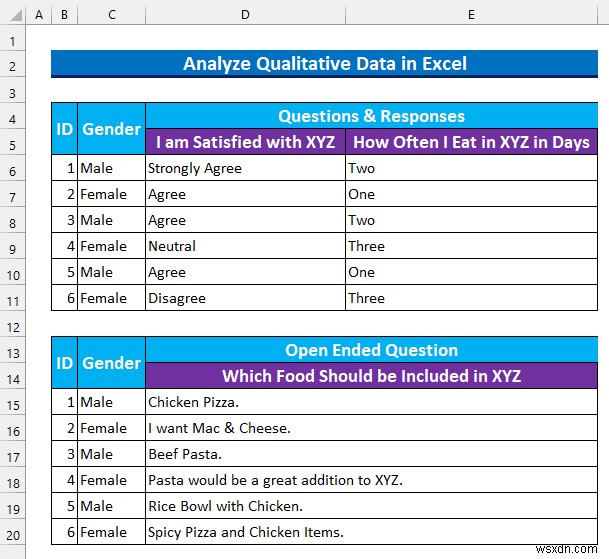
हमने अपने दृष्टिकोणों को प्रदर्शित करने के लिए एक सर्वेक्षण प्रश्नावली से तीन उत्तर लिए हैं। यहां, XYZ एक कैफे . है एक शहर के अंत में और छात्र कभी-कभी वहां घूमते हैं। तीन प्रश्न इस प्रकार हैं:
- सबसे पहले, एक लिकर्ट स्केल प्रश्न "मैं XYZ से संतुष्ट हूं " इस प्रश्न का उत्तर देने के लिए 5 स्तर हैं।
- अगला, एक बहुविकल्पीय प्रश्न "मैं कितनी बार खाता हूं XYZ दिनों में"। प्रतिभागी 3 . में से किसी एक को चुन सकते हैं विकल्प।
- अंत में, एक खुला प्रश्न:" XYZ में कौन सा भोजन शामिल किया जाना चाहिए? " पाठ की कोई भी लंबाई यहां स्वीकार्य थी।
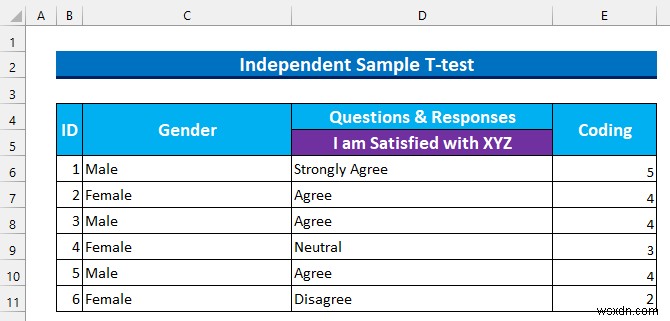
आम तौर पर, हमारे डेटासेट में 3 . होता है कॉलम:“आईडी ”, “लिंग ”, और “प्रश्न & प्रतिक्रियाएं " इसके अलावा, नीचे दिए गए स्नैपशॉट में, तीन प्रश्नों को एक कॉम्पैक्ट संरचना में दिखाया गया है। हम चर्चा करेंगे कि प्रत्येक प्रकार से जानकारी कैसे प्राप्त करें।
चरण 1:एक्सेल में विश्लेषण करने के लिए गुणात्मक डेटा को कोड और सॉर्ट करें
हम गुणात्मक डेटा को रूपांतरित करेंगे कोड का उपयोग करके संख्यात्मक मानों में। फिर, हम डेटा . को सॉर्ट करेंगे अगले चरण की तैयारी के लिए। हमारा लिकर्ट स्केल है 5 स्तर, इसलिए मान इस तरह होंगे:
- पूरी तरह से सहमत -> 5 ।
- सहमत -> 4 ।
- तटस्थ -> 3 ।
- असहमत -> 2 ।
- पूरी तरह असहमत -> 1 ।
- इसलिए, हम इसका उपयोग सेल श्रेणी में मान इनपुट करने के लिए करते हैं E6:E11 ।
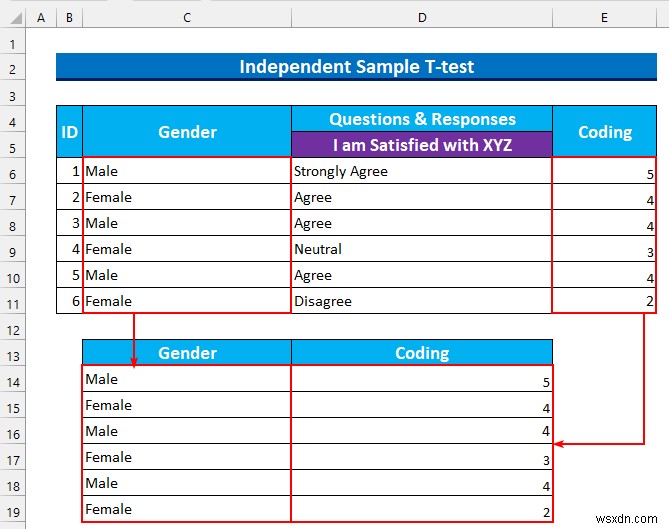
- फिर, हम “लिंग . को अलग करते हैं ” और “कोडिंग विभिन्न सेल श्रेणियों में कॉलम।
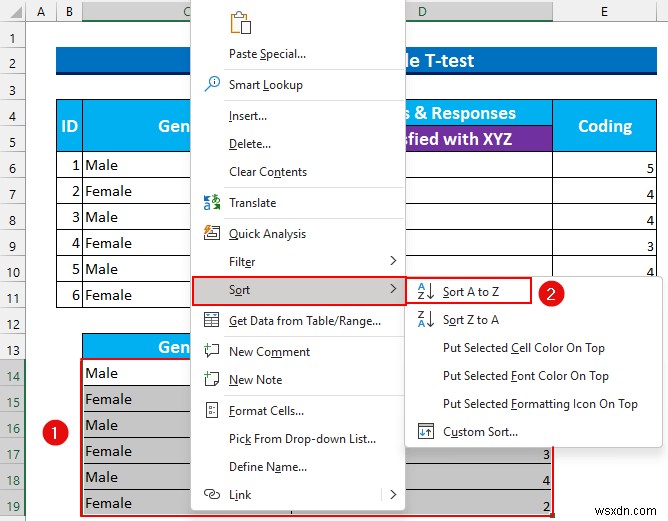
- बाद में, सेल श्रेणी चुनें C14:D19 और संदर्भ मेनू लाने के लिए राइट-क्लिक करें ।
- अगला, क्रमबद्ध करें . से >>> चुनें “A से Z तक क्रमित करें "।
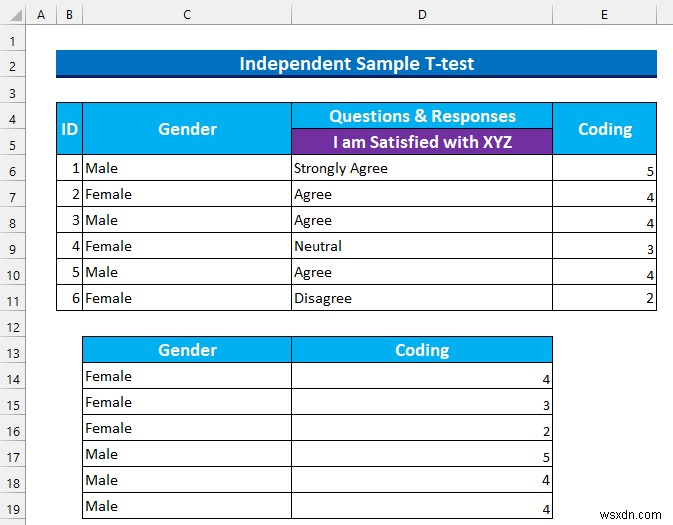
- इसलिए, समान लिंग के लिए हमारे मूल्य एक साथ रहेंगे।
और पढ़ें:Excel में विश्लेषण डेटा का उपयोग कैसे करें (5 आसान तरीके)
चरण 2:विश्लेषण टूलपैक सक्षम करें
हमें डेटा विश्लेषण को सक्षम करने की आवश्यकता है एक्सेल . में सुविधा कोई भी सांख्यिकीय परीक्षण करने से पहले।
- शुरू करने के लिए, ALT press दबाएं , एफ , फिर टी एक्सेल विकल्प लाने के लिए खिड़की।
- फिर, ऐड-इन्स . से >>> चुनें “जाओ… "।
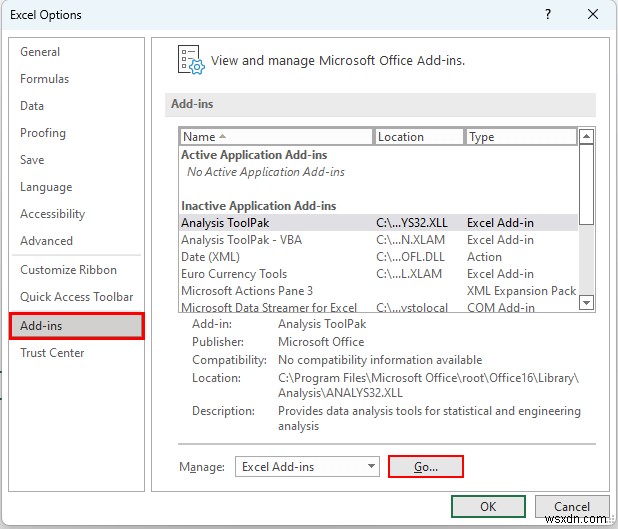
- तो, ऐड-इन संवाद बॉक्स पॉप अप होगा।
- बाद में, “विश्लेषण टूलपैक . चुनें ” और ठीक press दबाएं ।
- अंत में, हम देखेंगे डेटा विश्लेषण डेटा . के अंदर कमांड करें टैब।
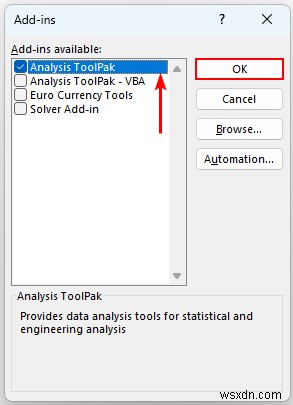
और पढ़ें:[फिक्स्ड:] डेटा विश्लेषण एक्सेल में नहीं दिख रहा है (2 प्रभावी समाधान)
चरण 3:गुणात्मक डेटा के साथ साधनों की तुलना करने के लिए टी-परीक्षण
हम “दो-नमूना टी-परीक्षण . का उपयोग करेंगे ”, जिसे “स्वतंत्र नमूना टी-परीक्षण . के रूप में भी जाना जाता है ” गुणात्मक डेटा का विश्लेषण करने के लिए . हमारे पास दो परिकल्पनाएं या धारणाएं हैं:
शून्य परिकल्पना एच <उप>0 : “दो समूह XYZ . से समान रूप से संतुष्ट हैं .
वैकल्पिक परिकल्पना एच <उप>ए : “दो समूह XYZ . से समान रूप से संतुष्ट नहीं हैं .
यदि हम अपना p-मान . पाते हैं 0.05 . से कम तब हम शून्य परिकल्पना को अस्वीकार करने में विफल होंगे . अन्यथा, हम शून्य परिकल्पना को अस्वीकार कर देंगे ।
- अंतिम चरण में, हमने विश्लेषण टूलपैक . को सक्षम किया . यह विश्लेषण . के अंतर्गत दिखाई देगा अनुभाग।
- फिर, “डेटा विश्लेषण . पर क्लिक करें "।
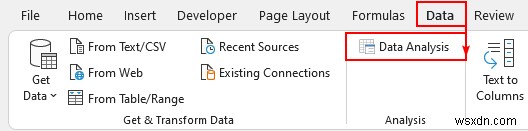
- अगला, "t-test:दो-नमूना असमान भिन्न मानते हुए चुनें ” और ठीक press दबाएं ।
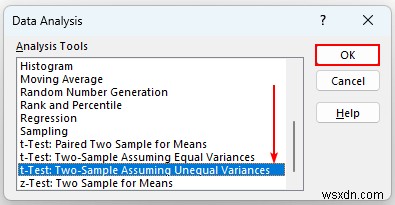
- बाद में, एक संवाद बॉक्स दिखाई देगा। इन विकल्पों को चुनें:
- चर 1 श्रेणी - D14:D16 ।
- चर 2 रेंज - D17:D19 ।
- हम इसे स्वैप भी कर सकते हैं, आउटपुट समान होगा।
- उसके बाद, “आउटपुट रेंज . चुनें ” और सेल C21 आउटपुट स्थान के रूप में।
- फिर, ठीकदबाएं ।
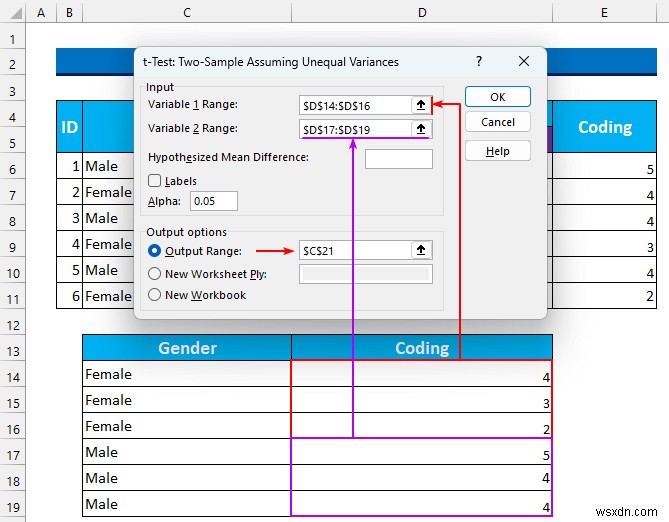
- तो, आउटपुट इस तरह होगा।
- अगला, हम देख सकते हैं कि माध्य 3 है और 4.33 . हम जाँच करेंगे कि यह अंतर महत्वपूर्ण है या नहीं p-value . का उपयोग करके . इसके अतिरिक्त, वेरिएंस 1 . हैं और 0.33 , इसलिए असमान प्रसरणों की हमारी धारणा सही थी। यदि यह मान लगभग समान है, तो आपको इसे "t-test:दो-नमूना समान भिन्न मानते हुए में बदलना होगा। "।
- इसलिए, हमें P(T<=t) टू-टेल पर ध्यान केंद्रित करने की आवश्यकता है केवल मूल्य। यह 0.05 . से कम होना चाहिए महत्वपूर्ण होना। जैसा है (0.14 अगर हम राउंड अप करें) 0.05 . से अधिक , इसलिए, हम शून्य परिकल्पना को अस्वीकार करते हैं ।
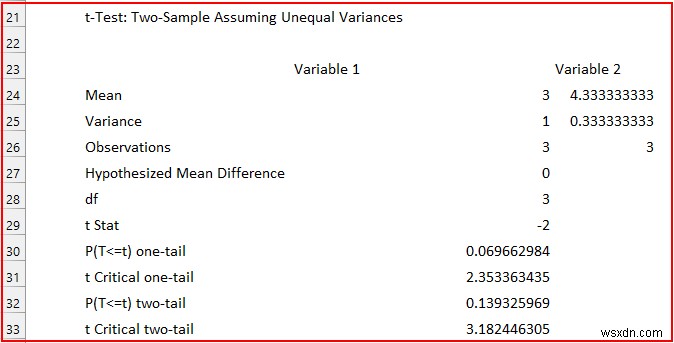
- इसलिए, विश्लेषण से, हम कह सकते हैं कि पुरुषों और महिलाओं की संतुष्टि के विभिन्न स्तर हैं कैफे XYZ , जो सांख्यिकीय दृष्टि से महत्वपूर्ण . है ।

चरण 4:ची-स्क्वायर टेस्ट के लिए श्रेणीबद्ध डेटासेट तैयार करें
हम SUM . का प्रयोग करेंगे और COUNTIFS इस चरण में कार्य करता है। अब हम दूसरे प्रश्न के विश्लेषण पर चर्चा करेंगे। हम ची-स्क्वायर . का उपयोग करते हैं परीक्षा दो श्रेणीबद्ध डेटा के बीच संबंध का पता लगाने के लिए। इसके अतिरिक्त, यह अपेक्षित और देखे गए मानों के बीच अंतर लौटा सकता है। हम यह पता लगाना चाहते हैं कि XYZ कैफ़े में लिंग और खाने के समय के बीच कोई संबंध है या नहीं ।
शून्य परिकल्पना एच <उप>0 : "XYZ . पर प्रति सप्ताह लिंग और खाने के बीच कोई संबंध नहीं है .
वैकल्पिक परिकल्पना एच <उप>ए : "XYZ . पर प्रति सप्ताह लिंग और खाने के बीच संबंध है .
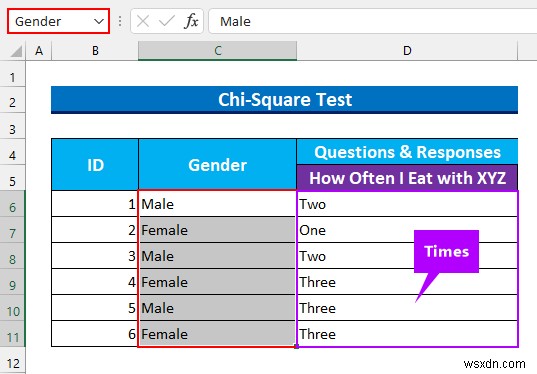
- सबसे पहले, हम श्रेणियों को नाम देंगे C6:C11 "लिंग . के रूप में ” और D6:D11 "समय . के रूप में "।
- अगला, हम ची-स्क्वायर . की गणना करने के लिए एक टेम्पलेट तैयार करेंगे मूल्य।
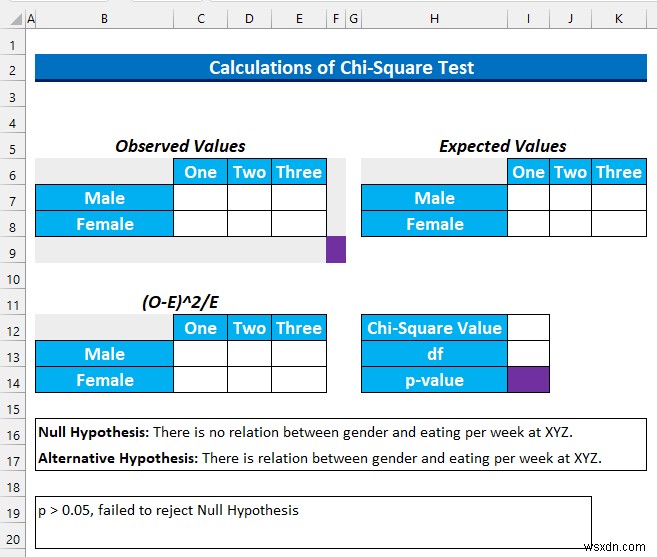
- फिर, हम सेल श्रेणी का चयन करेंगे C7:E7 और निम्न सूत्र टाइप करें।
=COUNTIFS(Gender,$B$7,Times,C6)
यह सूत्र पुरुषों और एक . वाले कक्षों की संख्या का पता लगाता है कैफे XYZ . में प्रति सप्ताह खाने का समय ।
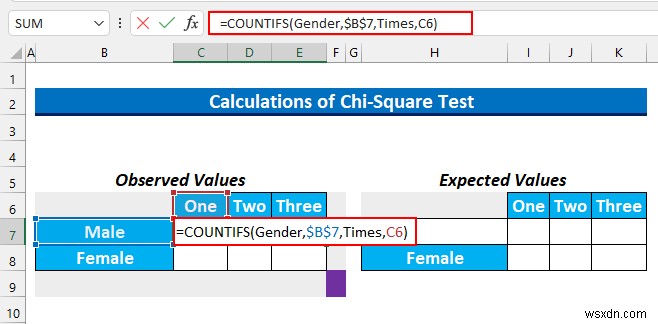
- अगला, CTRL+ENTER दबाएं . यह सूत्र को स्वतः भर देगा ।
- उसके बाद, हम सेल श्रेणी का चयन करेंगे C8:E8 और निम्न सूत्र टाइप करें।
=COUNTIFS(Gender,$B$8,Times,C6)
यह सूत्र महिलाओं और एक . वाले कक्षों की संख्या का पता लगाता है कैफे XYZ . में प्रति सप्ताह खाने का समय ।
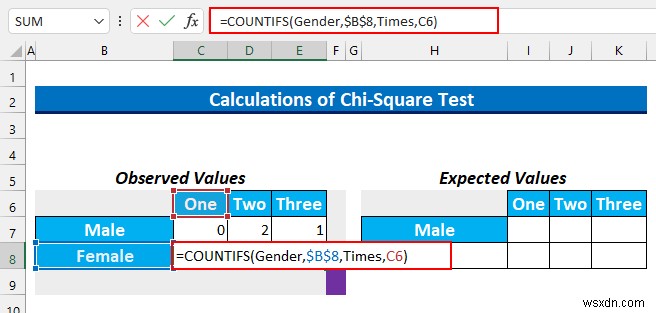
- फिर, CTRL+ENTERदबाएं ।
- बाद में, हम पंक्तियों और स्तंभों का योग करेंगे।
- सेल श्रेणी चुनें C9:E9 और यह सूत्र टाइप करें।
=SUM(C7:C8)
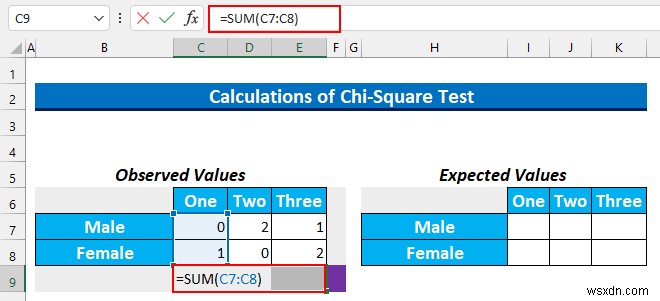
- प्रेस CTRL+ENTER ।
- फिर, सेल श्रेणी चुनें F7:F8 और यह सूत्र टाइप करें।
=SUM(C7:E7)
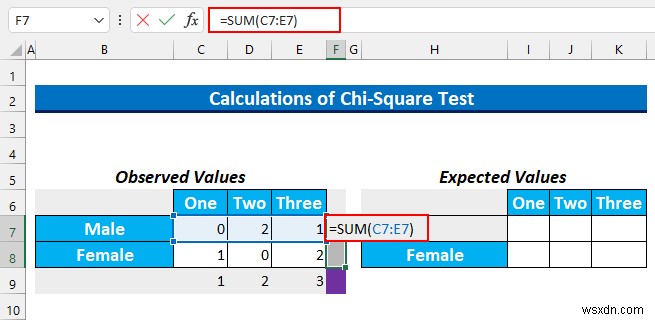
- प्रेस CTRL+ENTER ।
- फिर, हम 6 . टाइप करेंगे सेल में F9 चूंकि उत्तरदाताओं की संख्या 6 थी ।
- अब, हम अपेक्षित मान प्राप्त करेंगे। इसे खोजने के लिए, सूत्र है पंक्ति योग * कुल कॉलम/कुल ।
- उसके बाद, इस सूत्र को सेल श्रेणी में टाइप करें I7:K7 इसे पहले से चुनकर।
=$F$7*C9/$F$9
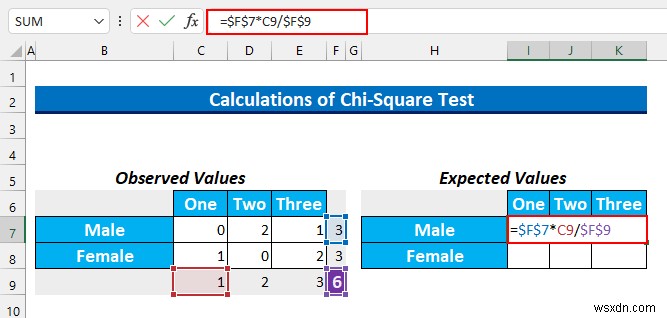
- प्रेस CTRL+ENTER ।
- फिर, सेल श्रेणी चुनें I8:K8 और यह सूत्र टाइप करें।
=$F$8*C9/$F$9
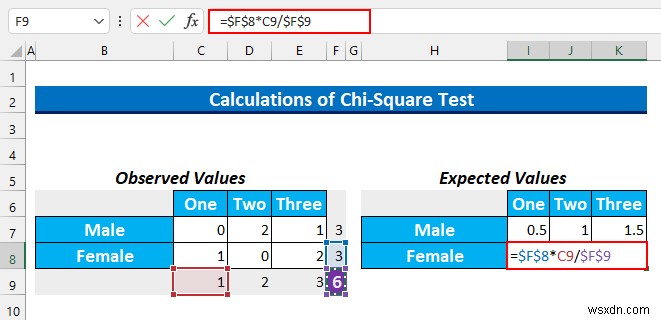
- उसके बाद, CTRL+ENTER दबाएं ।
- अब, हम ची-स्क्वायर . पाएंगे मूल्य।
- तो, सेल श्रेणी चुनें C13:E14 और निम्न सूत्र टाइप करें।
=(C7-I7)^2/I7
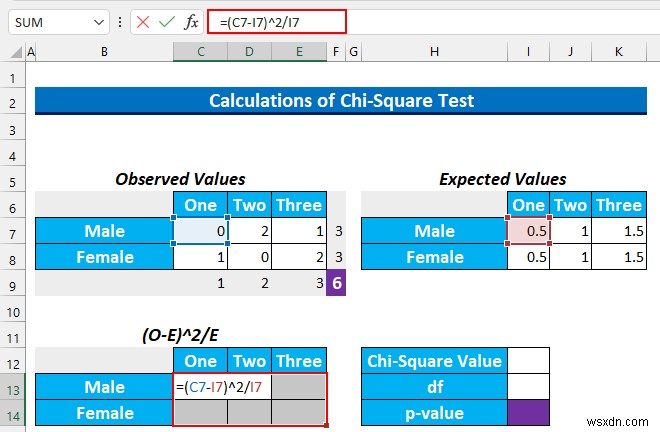
- उसके बाद, CTRL+ENTER दबाएं ।
- फिर, हम इन मानों को सेल में जोड़ देंगे I12 इस सूत्र को टाइप करके।
=SUM(C13:E14)
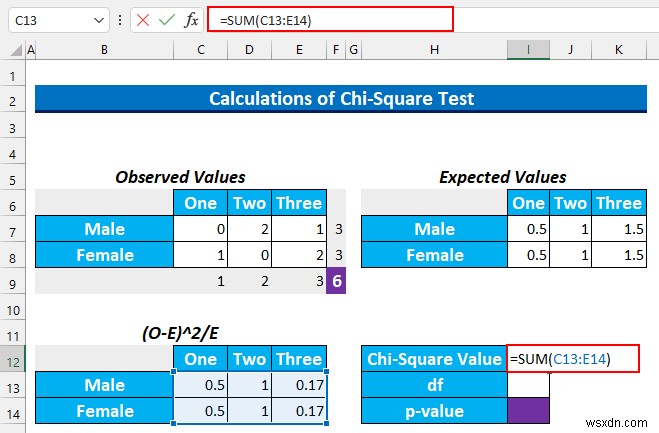
- बाद में, ENTERदबाएं ।
- अब, df मतलब स्वतंत्रता की डिग्री . इसे खोजने का सूत्र (कॉलम की संख्या -1) * (पंक्तियों की संख्या-1) का उपयोग करना है . हमारे पास 2 है पंक्तियाँ और 3 स्तंभ। इसलिए, हमारे df होगा (3-1)*(2-1) =2 ।
और पढ़ें:Excel में बड़े डेटा सेट का विश्लेषण कैसे करें (6 प्रभावी तरीके)
समान रीडिंग
- एक्सेल में बिक्री डेटा का विश्लेषण कैसे करें (10 आसान तरीके)
- पिवट टेबल (9 उपयुक्त उदाहरण) का उपयोग करके एक्सेल में डेटा का विश्लेषण करें
- एक्सेल में समय के हिसाब से डेटा का विश्लेषण कैसे करें (आसान चरणों के साथ)
चरण 5:ची-स्क्वायर टेस्ट के साथ एक्सेल में श्रेणीबद्ध गुणात्मक डेटा का विश्लेषण करें
हम CHISQ.DIST.RT . का उपयोग करेंगे पी-वैल्यू खोजने के लिए इस परीक्षण के लिए।
- तो, इस सूत्र को सेल में टाइप करें I14 ।
=CHISQ.DIST.RT(I12,I13)
यह फ़ंक्शन "ची-स्क्वेर्ड डिस्ट्रीब्यूशन की राइट-टेल्ड प्रायिकता" देता है।
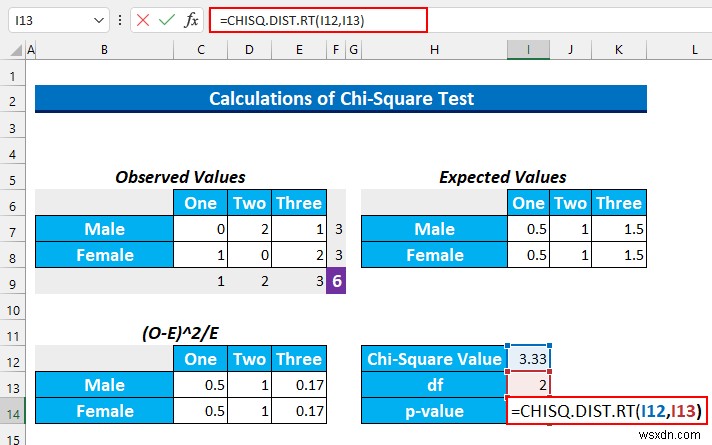
- उसके बाद, ENTER press दबाएं . हमें 0.2 . का मान मिलेगा जो 0.05 . से बड़ा है . इसलिए, हम शून्य परिकल्पना को अस्वीकार करने में विफल रहेंगे . सरल शब्दों में, हम कह सकते हैं कि दोनों श्रेणियों का कोई संबंध नहीं है।
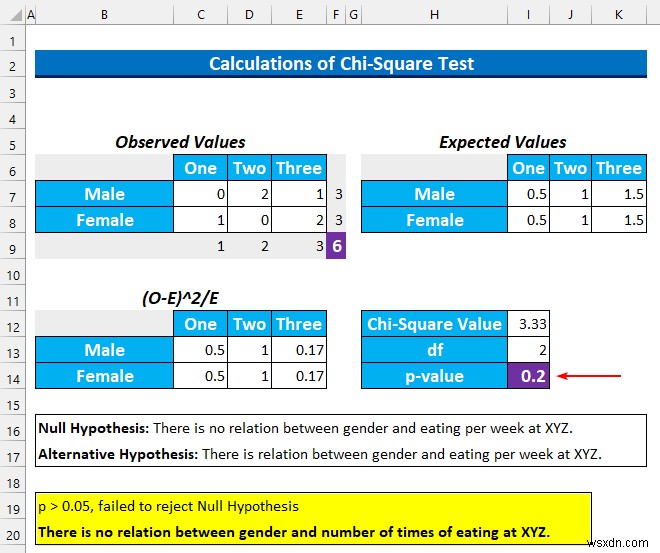
चरण 6:ओपन-एंडेड गुणात्मक डेटा के लिए सेंटीमेंट विश्लेषण
अब, हम अपने अंतिम प्रश्न और प्रतिक्रियाओं पर गौर करेंगे। हम प्रतिक्रियाओं के विषयों को खोजने की मैन्युअल प्रक्रिया का उपयोग करेंगे। हमने डेटासेट में दो कॉलम जोड़े हैं:“विषय1 ” और “विषय2 .

- फिर, हम प्रतिक्रियाओं को पढ़ेंगे और उन्हें खाद्य विषय संलग्न करेंगे। उदाहरण के लिए, “चिकन पिज्जा ” में 2 . है विषय:“चिकन ” और “पिज्जा ” और इसी तरह।
- उसके बाद, हमने अद्वितीय विषयों को केवल एक नई तालिका में जोड़ा।
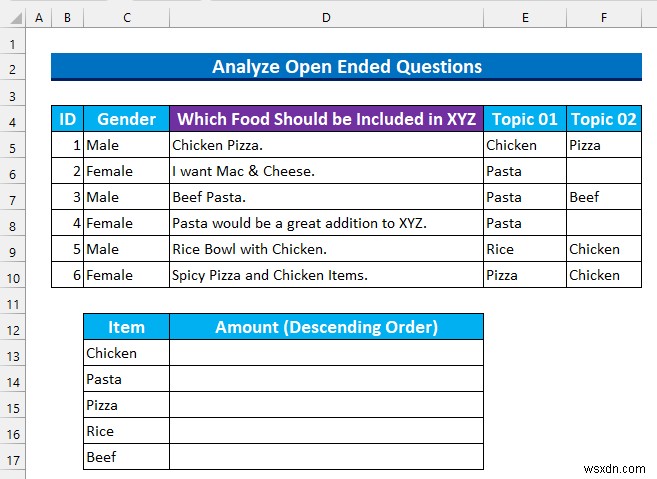
चरण 7:ओपन-एंडेड गुणात्मक डेटा का विश्लेषण करने के लिए COUNTIF फ़ंक्शन का उपयोग करें
हम COUNTIF फ़ंक्शन का उपयोग करेंगे आवृत्ति वितरण में अंतर्दृष्टि प्राप्त करने के लिए।
- सबसे पहले, सेल श्रेणी चुनें D13:D17 और निम्न सूत्र टाइप करें।
=COUNTIF($E$5:$F$10,C13)
यह सूत्र F5:F10 . श्रेणी में मानों की संख्या की गणना करता है जिसका सेल C13 . से मान है ।
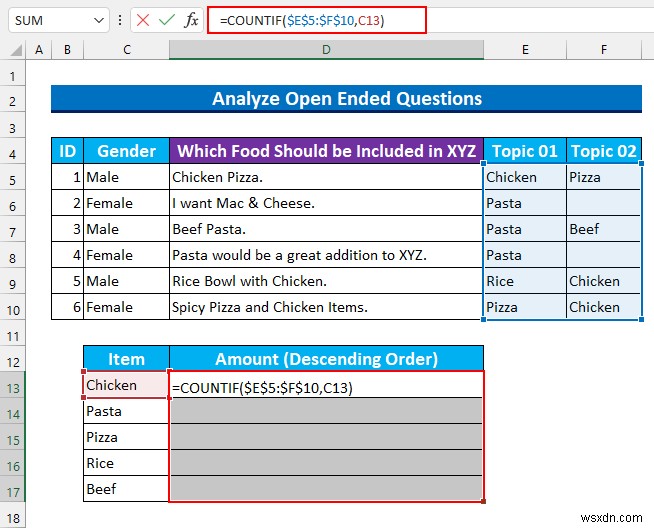
- बाद में, स्वतः भरण . करने के लिए सूत्र, CTRL+ENTERदबाएं ।
- अगला, हम एक चार्ट सम्मिलित करेंगे आवृत्ति वितरण की कल्पना करने के लिए।
चरण 8:ओपन-एंडेड क्वालिटेटिव डेटा को विज़ुअलाइज़ करने के लिए क्लस्टर्ड कॉलम चार्ट
इस चरण में, हम एक संकुल कॉलम चार्ट तैयार करेंगे गुणात्मक डेटा को समझने के लिए अधिक स्पष्ट रूप से।
- तो, सेल श्रेणी चुनें C12:D17 और सम्मिलित करें टैब से, अनुशंसित चार्ट select चुनें ।
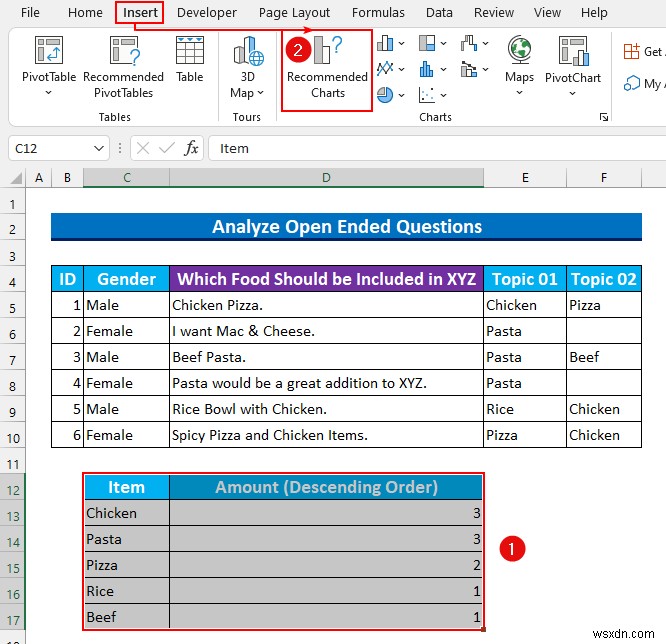
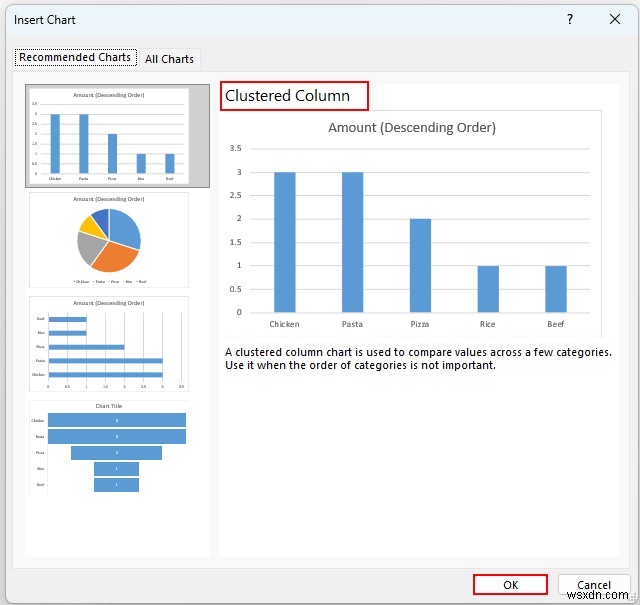
- फिर, चार्ट सम्मिलित करें संवाद बॉक्स दिखाई देगा और संकुलित स्तंभ डिफ़ॉल्ट रूप से चुना जाएगा। यदि नहीं तो इसे चुनें।
- उसके बाद, ठीकदबाएं ।
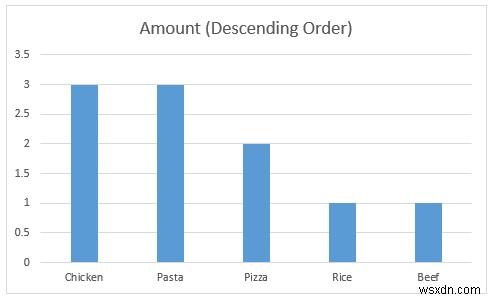
- फिर, हम देख सकते हैं कि ग्राहक चिकन want चाहते हैं , पास्ता, और पिज्जा शीर्ष के रूप में 3 XYZ कैफे में खाद्य पदार्थ . XYZ कैफे . का प्रबंधन अधिक आय उत्पन्न करने के लिए इनमें से अधिक उत्पादों की पेशकश करना चुन सकते हैं।
सारांश
- हम टी-टेस्ट . का उपयोग करते हैं जब हम साधनों की तुलना . करते हैं दो समूहों और ची-स्क्वायर टेस्ट . के बीच जब हम श्रेणीबद्ध मूल्यों . के साथ काम करते हैं ।
- हमारे डेटासेट के लिए, हमें ये परिणाम हमारे सर्वेक्षण प्रश्नावली के तीन प्रश्नों से प्राप्त होते हैं-
- पुरुषों और महिलाओं में कैफे XYZ . के साथ संतुष्टि के विभिन्न स्तर हैं ।
- लिंग और खाने की संख्या कैफ़े XYZ संबंधित नहीं है।
- छात्रों या ग्राहकों को चिकन चाहिए , पास्ता , और पिज्जा Cafe XYZ में शामिल करने के लिए शीर्ष तीन आइटम के रूप में ।
अभ्यास अनुभाग
हमने Excel . में प्रत्येक विधि के लिए एक अभ्यास डेटासेट जोड़ा है फ़ाइल। इसलिए, आप हमारे तरीकों को आसानी से अपना सकते हैं।
निष्कर्ष
हमने आपको दिखाया है 8 गुणात्मक डेटा का विश्लेषण करने . के चरण एक्सेल . में . यदि आपको इन विधियों के संबंध में कोई समस्या आती है या मेरे लिए कोई प्रतिक्रिया है, तो नीचे टिप्पणी करने में संकोच न करें। इसके अलावा, आप हमारी साइट पर जा सकते हैं ExcelDemy अधिक के लिए एक्सेल-संबंधित लेख। पढ़ने के लिए धन्यवाद, उत्कृष्ट बने रहें!
संबंधित लेख
- Excel में qPCR डेटा का विश्लेषण कैसे करें (2 आसान तरीके)
- एक्सेल डेटा विश्लेषण का उपयोग करके केस स्टडी निष्पादित करें
- Excel में टेक्स्ट डेटा का विश्लेषण कैसे करें (5 उपयुक्त तरीके)