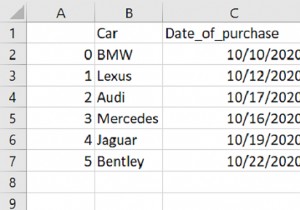
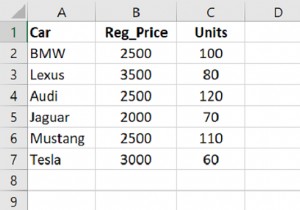
समूह के बाद सूचकांक को रीसेट करने के लिए, पहले समूह में समूह द्वारा () का उपयोग करके एक कॉलम के अनुसार। उसके बाद, रीसेट_इंडेक्स () का उपयोग करें।
सबसे पहले, आवश्यक पुस्तकालय आयात करें -
import pandas as pd
2 कॉलम के साथ डेटाफ़्रेम बनाएं -
dataFrame = pd.DataFrame(
{
"Car": ["Audi", "Lexus", "Audi", "Mercedes", "Audi", "Lexus", "Mercedes", "Lexus", "Mercedes"],
"Reg_Price": [1000, 1400, 1100, 900, 1700, 1800, 1300, 1150, 1350]
}
)
कार कॉलम के अनुसार समूह -
resDF = dataFrame.groupby("Car").mean() अब, समूहीकरण के बाद अनुक्रमणिका रीसेट करें -
resDF.reset_index()
उदाहरण
निम्नलिखित कोड है -
import pandas as pd
# creating a dataframe with two columns
dataFrame = pd.DataFrame(
{
"Car": ["Audi", "Lexus", "Audi", "Mercedes", "Audi", "Lexus", "Mercedes", "Lexus", "Mercedes"],
"Reg_Price": [1000, 1400, 1100, 900, 1700, 1800, 1300, 1150, 1350]
}
)
print"DataFrame...\n",dataFrame
# grouped according to Car
resDF = dataFrame.groupby("Car").mean()
print"\nDataFrame...\n", resDF
# resetting index after grouping
print"\nReset index after grouping...\n", resDF.reset_index()
आउटपुट
यह निम्नलिखित आउटपुट देगा -
DataFrame... Car Reg_Price 0 Audi 1000 1 Lexus 1400 2 Audi 1100 3 Mercedes 900 4 Audi 1700 5 Lexus 1800 6 Mercedes 1300 7 Lexus 1150 8 Mercedes 1350 DataFrame... Reg_Price Car Audi 1266.666667 Lexus 1450.000000 Mercedes 1183.333333 Reset index after grouping... Car Reg_Price 0 Audi 1266.666667 1 Lexus 1450.000000 2 Mercedes 1183.333333