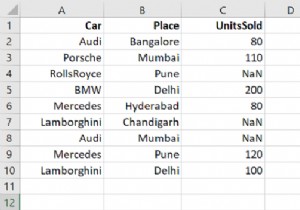
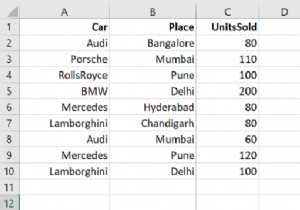
डेटाफ़्रेम से किसी स्तंभ का चयन करने के लिए, बस उसे वर्गाकार कोष्ठकों का उपयोग करके प्राप्त करें। कोष्ठक में चयन करने के लिए कॉलम का उल्लेख करें और वह है, उदाहरण के लिए
dataFrame[‘ColumnName’]
सबसे पहले, आवश्यक पुस्तकालय आयात करें -
import pandas as pd
अब, एक डेटाफ़्रेम बनाएँ। हमारे पास इसमें दो कॉलम हैं -
dataFrame = pd.DataFrame(
{
"Car": ['BMW', 'Lexus', 'Audi', 'Mustang', 'Bentley', 'Jaguar'],
"Units": [100, 150, 110, 80, 110, 90]
}
) केवल एक स्तंभ का चयन करने के लिए, नीचे दिखाए गए अनुसार वर्गाकार कोष्ठक का उपयोग करते हुए स्तंभ नाम का उल्लेख करें। यहाँ, हमारे कॉलम का नाम 'कार' है -
dataFrame ['Car']
उदाहरण
निम्नलिखित कोड है -
import pandas as pd
# Create DataFrame
dataFrame = pd.DataFrame(
{
"Car": ['BMW', 'Lexus', 'Audi', 'Mustang', 'Bentley', 'Jaguar'],
"Units": [100, 150, 110, 80, 110, 90]
}
)
print"DataFrame ...\n",dataFrame
# selecting a column
print"\nSelecting and displaying only a single column = \n",dataFrame ['Car'] आउटपुट
यह निम्नलिखित आउटपुट देगा -
DataFrame ... Car Units 0 BMW 100 1 Lexus 150 2 Audi 110 3 Mustang 80 4 Bentley 110 5 Jaguar 90 Selecting and displaying only a single column = 0 BMW 1 Lexus 2 Audi 3 Mustang 4 Bentley 5 Jaguar Name: Car, dtype: object