डेटाफ़्रेम से कई पंक्तियों का चयन करने के लिए, :ऑपरेटर का उपयोग करके सीमा निर्धारित करें। सबसे पहले, आवश्यकता पांडा पुस्तकालय को उपनाम के साथ आयात करें -
import pandas as pd
अब, एक नया पांडा डेटाफ़्रेम बनाएं -
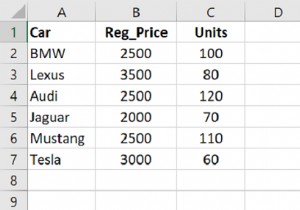
dataFrame = pd.DataFrame([[10, 15], [20, 25], [30, 35], [40, 45]],index=['w', 'x', 'y', 'z'],columns=['a', 'b'])
:ऑपरेटर -
. का उपयोग करके कई पंक्तियों का चयन करेंdataFrame[0:2]
उदाहरण
निम्नलिखित कोड है -
import pandas as pd # Create DataFrame dataFrame = pd.DataFrame([[10, 15], [20, 25], [30, 35], [40, 45]],index=['w', 'x', 'y', 'z'],columns=['a', 'b']) # DataFrame print"DataFrame...\n",dataFrame # select rows with loc print"\nSelect rows by passing label..." print(dataFrame.loc['z']) # select rows with integer location using iloc print"\nSelect rows by passing integer location..." print(dataFrame.iloc[1]) # selecting multiple rows print"\nSelect multiple rows..." print(dataFrame[0:2])
आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame... a b w 10 15 x 20 25 y 30 35 z 40 45 Select rows by passing label... a 40 b 45 Name: z, dtype: int64 Select rows by passing integer location... a 20 b 25 Name: x, dtype: int64 Select multiple rows... a b w 10 15 x 20 25