हम शर्तें सेट कर सकते हैं और डेटाफ़्रेम पंक्तियाँ ला सकते हैं। इन शर्तों को तार्किक ऑपरेटरों और यहां तक कि संबंधपरक ऑपरेटरों का उपयोग करके सेट किया जा सकता है।
सबसे पहले, आवश्यक पांडा पुस्तकालयों को आयात करें -
import pandas as pd
आइए हम एक DataFrame बनाएं और अपनी CSV फ़ाइल पढ़ें -
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesRecords.csv")
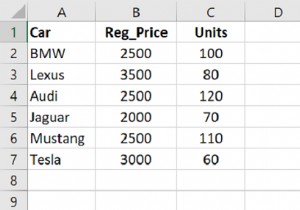
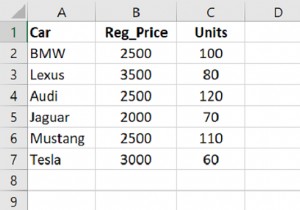
1000 से कम पंजीकरण मूल्य वाली डेटाफ़्रेम पंक्तियों को लाया जा रहा है। हम इसके लिए रिलेशनल ऑपरेटर का उपयोग कर रहे हैं -
dataFrame[dataFrame.Reg_Price < 1000]
उदाहरण
निम्नलिखित कोड है -
import pandas as pd
# reading csv file
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesRecords.csv")
print("DataFrame...\n",dataFrame)
# count the rows and columns in a DataFrame
print("\nNumber of rows and column in our DataFrame = ",dataFrame.shape)
# fetching dataframe rows with registration price less than 1000
resData = dataFrame[dataFrame.Reg_Price < 1000]
print("DataFrame...\n",resData) आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame... Car Date_of_Purchase Reg_Price 0 BMW 10/10/2020 1000 1 Lexus 10/12/2020 750 2 Audi 10/17/2020 750 3 Jaguar 10/16/2020 1500 4 Mustang 10/19/2020 1100 5 Lamborghini 10/22/2020 1000 Number of rows and column in our DataFrame = (6, 3) DataFrame... Car Date_of_Purchase Reg_Price 1 Lexus 10/12/2020 750 2 Audi 10/17/2020 750