पंक्तियों को फ़िल्टर करने और विशिष्ट स्तंभ मान प्राप्त करने के लिए, पंडों में () विधि का उपयोग करें। सबसे पहले, हम आवश्यक पुस्तकालय को उपनाम के साथ आयात करते हैं -
import pandas as pd
Read_csv() का उपयोग करके CSV फ़ाइल पढ़ें। हमारी CSV फ़ाइल डेस्कटॉप पर है -
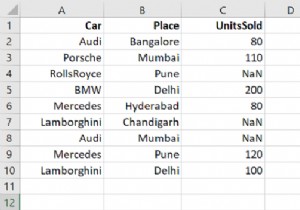
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv")
अब, विशिष्ट टेक्स्ट वाली पंक्तियों को फ़िल्टर करते हैं -
dataFrame = dataFrame[dataFrame['Car'].str.contains('Lamborghini')] उदाहरण
निम्नलिखित कोड है
import pandas as pd
# reading csv file
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv")
print("DataFrame...\n",dataFrame)
# select rows containing text "Lamborghini"
dataFrame = dataFrame[dataFrame['Car'].str.contains('Lamborghini')]
print("\nFetching rows with text Lamborghini ...\n",dataFrame) वाली पंक्तियाँ आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame... Car Place UnitsSold 0 Audi Bangalore 80 1 Porsche Mumbai 110 2 RollsRoyce Pune 100 3 BMW Delhi 95 4 Mercedes Hyderabad 80 5 Lamborghini Chandigarh 80 6 Audi Mumbai 100 7 Mercedes Pune 120 8 Lamborghini Delhi 100 Fetching rows with text Lamborghini ... Car Place UnitsSold 5 Lamborghini Chandigarh 80 8 Lamborghini Delhi 100