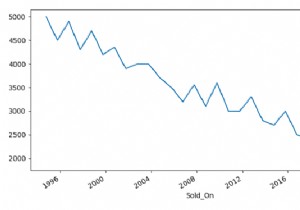
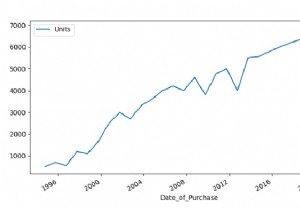
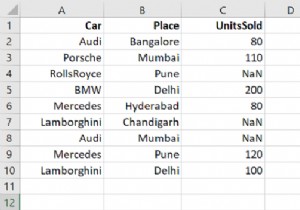
वांछित पाठ वाली पंक्तियों को पुनरावृत्त करने और लाने के लिए, itertuples() और find() विधि का उपयोग करें। itertuples() DataFrame पंक्तियों पर पुनरावृति करता है।
सबसे पहले, हम आवश्यक पुस्तकालय को एक उपनाम के साथ आयात करते हैं -
pd के रूप में पांडा आयात करें
हमारा सीएसवी डेस्कटॉप पर है जैसा कि नीचे दिए गए पथ में दिखाया गया है -
C:\\Users\\amit_\\Desktop\\CarRecords.csv
आइए हम CSV फ़ाइल पढ़ें और पंडों का डेटाफ़्रेम बनाएं -
dataFrame =pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv") एक विशिष्ट पाठ वाली पंक्तियों को पुनरावृत्त करें और प्राप्त करें। हम "लेम्बोर्गिनी" टेक्स्ट के साथ कार कॉलम ला रहे हैं -
k के लिए dataFrame.itertuples():if k[1].find('Lamborghini') !=-1:print(k) उदाहरण
निम्नलिखित कोड है
पंडों को पीडी के रूप में आयात करें# सीएसवी फाइलडेटाफ्रेम पढ़ना =पीडी.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv")print("DataFrame...\n",dataFrame)# iterate और एक विशिष्ट पाठ वाली पंक्तियों को प्राप्त करें# हम dataFrame.itertuples():if k[1].find('Lamborghini') !=-1:print(k) आउटपुट
यह निम्नलिखित आउटपुट देगा -
पंडस(इंडेक्स=5, कार='लेम्बोर्गिनी', प्लेस='चंडीगढ़', यूनिट्स बिकी=80)पंडस(इंडेक्स=8, कार='लेम्बोर्गिनी', प्लेस='दिल्ली', यूनिट्स बिकी=100)