प्रदान किए गए डेटा फ़्रेम में प्रत्येक पंक्ति की रैंकिंग वाले कॉलम को जोड़ने के लिए जो हमें डेटा फ़्रेम को सॉर्ट करने और किसी विशेष तत्व की रैंक निर्धारित करने में मदद करेगा, उदाहरण के लिए -
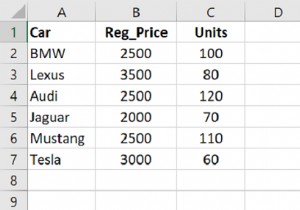
हमारा डेटाफ़्रेम
| नाम खेलने का समय (घंटों में) | <वें>दर|||
|---|---|---|---|
| 0 | ड्यूटी की कॉल | 45 | औसत से बेहतर |
| 1 | कुल ओवरडोज | 46 | अच्छा |
| 2 | GTA3 | 52 | सर्वश्रेष्ठ |
| 3 | धमकाने | 22 | औसत |
आउटपुट
| नाम खेलने का समय (घंटों में) | रेटिंग रैंकिंग | |||
|---|---|---|---|---|
| 0 | ड्यूटी की कॉल | 45 | औसत से बेहतर | 3.0 |
| 1 | कुल ओवरडोज | 46 | अच्छा | 2.0 |
| 2 | GTA3 | 52 | सर्वश्रेष्ठ | 1.0 |
| 3 | धमकाने | 22 | औसत | 4.0 |
अब, जैसा कि आप ऊपर दिए गए उदाहरण में देख सकते हैं, हमारी रैंकिंग पूरी संख्या है, लेकिन इसके बगल में एक दशमलव है, इसका मतलब है कि हम वास्तविक संख्याओं में भी रैंकिंग कर सकते हैं, और ऐसा तब होता है जब एक से अधिक तत्वों की रैंक समान होती है। डेटा फ्रेम की तुलना में ऐसे मामलों में हमारी रैंकिंग तत्वों के बीच विभाजित होती है। इसलिए, उनकी रैंक के रूप में उनके पास एक वास्तविक संख्या होती है।
अब हम अपने डेटा फ़्रेम को रैंक कैसे असाइन करें
हमारे डेटाफ़्रेम के तत्वों को रैंक प्रदान करने के लिए, हम पांडा लाइब्रेरी के एक अंतर्निहित फ़ंक्शन का उपयोग करते हैं जो कि .रैंक () है। समारोह। हम उस मानदंड को पास करते हैं जिसके आधार पर हम तत्वों की रैंकिंग कर रहे हैं, और यह फ़ंक्शन प्रत्येक पंक्ति में एक नया कॉलम देता है जहां रैंकिंग संग्रहीत की जाती है।
उदाहरण
.रैंक () फ़ंक्शन का उपयोग करने के लिए कोड है
import pandas as pd
games = {'Name' : ['Call Of Duty', 'Total Overdose', 'GTA 3', 'Bully'],
'Play Time(in hours)' : ['45', '46', '52', '22'],
'Rate' : ['Better than Average', 'Good', 'Best', 'Average']}
df = pd.DataFrame(games)
df['ranking'] = df['Play Time(in hours)'].rank(ascending = 0)
print(df)# Hello World program in Python
print ("Hello World!"); आउटपुट
Name Play Time(in hours) Rate ranking 0 Call Of Duty 45 Better than Average 3.0 1 TotalOverdose 46 Good 2.0 2 GTA 3 52 Best 1.0 3 Bully 22 Average 4.0
उपरोक्त कोड की व्याख्या
इस कोड में, हम दिए गए डेटा फ्रेम में मौजूद प्रत्येक तत्व को रैंक करने के लिए बस पांडा के पुस्तकालय के अंतर्निहित कार्य का उपयोग कर रहे हैं। हम 'प्ले टाइम (घंटों में)' कॉलम के साथ तत्वों को रैंक करने के लिए सर्वोत्तम मानदंड का उपयोग कर सकते हैं।
अब हम अपने डेटा फ्रेम में 'रैंकिंग' नाम का एक कॉलम जोड़ते हैं और अपने .rank() . का उपयोग करते हैं इसमें कार्य करें और कॉलम नाम पास करें जिसके लिए हमें अपने तत्वों की रैंकिंग करने की आवश्यकता है (इस मामले में, यह प्ले टाइम (घंटों में) कॉलम है) अब जब हमारा नया कॉलम बनाया जाता है तो हम अपना डेटा फ्रेम प्रिंट करते हैं।
निष्कर्ष
इस ट्यूटोरियल में, हम अपने डेटा फ्रेम में पंक्तियों को रैंक करते हैं और फिर पांडा लाइब्रेरी और इसके अंतर्निहित कार्यों का उपयोग करके अपने डेटा को प्रिंट करते हैं। पांडा डेटाफ़्रेम की रैंकिंग पंक्तियाँ एक आसान प्रक्रिया है, लेकिन आपको उपरोक्त विधि का ठीक से पालन करने की आवश्यकता है।