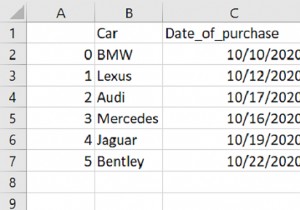
डेटाफ़्रेम को समय के अनुसार फ़िल्टर करने के लिए, लोकेशन का उपयोग करें और रिकॉर्ड लाने के लिए उसमें शर्त सेट करें। सबसे पहले, आवश्यक पुस्तकालय आयात करें -
import pandas as pd
दिनांक रिकॉर्ड के साथ सूची का शब्दकोश बनाएं -
d = {'Car': ['BMW', 'Lexus', 'Audi', 'Mercedes', 'Jaguar', 'Bentley'],'Date_of_Purchase': ['2021-07-10', '2021-08-12', '2021-06-17', '2021-03-16', '2021-05-19', '2021-08-22']
} सूचियों के उपरोक्त शब्दकोश से डेटाफ़्रेम बनाना -
dataFrame = pd.DataFrame(d)
अब, मान लें कि हमें एक विशिष्ट तिथि के बाद खरीदी गई कारों को लाने की आवश्यकता है। इसके लिए हम loc -
. का उपयोग करते हैंresDF = dataFrame.loc[dataFrame["Date_of_Purchase"] > "2021-07-15"]
उदाहरण
पूरा कोड निम्नलिखित है -
import pandas as pd
# dictionary of lists
d = {'Car': ['BMW', 'Lexus', 'Audi', 'Mercedes', 'Jaguar', 'Bentley'],'Date_of_Purchase': ['2021-07-10', '2021-08-12', '2021-06-17', '2021-03-16', '2021-05-19', '2021-08-22']
}
# creating dataframe from the above dictionary of lists
dataFrame = pd.DataFrame(d)
print"DataFrame...\n",dataFrame
# fetch cars purchased after 15th July 2021
resDF = dataFrame.loc[dataFrame["Date_of_Purchase"] > "2021-07-15"]
# print filtered data frame
print"\nCars purchased after 15th July 2021: \n",resDF आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame... Car Date_of_Purchase 0 BMW 2021-07-10 1 Lexus 2021-08-12 2 Audi 2021-06-17 3 Mercedes 2021-03-16 4 Jaguar 2021-05-19 5 Bentley 2021-08-22 Cars purchased after 15th July 2021: Car Date_of_Purchase 1 Lexus 2021-08-12 5 Bentley 2021-08-22