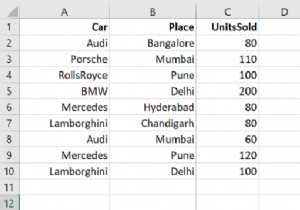
पंडों के डेटाफ़्रेम में अशक्त पंक्तियों को छोड़ने के लिए, ड्रॉपना () विधि का उपयोग करें। मान लें कि कुछ NaN यानी शून्य मानों वाली हमारी CSV फ़ाइल निम्नलिखित है -
आइए read_csv() का उपयोग करके CSV फ़ाइल पढ़ें। हमारा सीएसवी डेस्कटॉप पर है -
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv") ड्रॉपना () -
. का उपयोग करके शून्य मान निकालेंdataFrame = dataFrame.dropna()
उदाहरण
पूरा कोड निम्नलिखित है -
import pandas as pd
# reading csv file
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv")
print("DataFrame...\n",dataFrame)
# count the rows and columns in a DataFrame
print("\nNumber of rows and column in our DataFrame = ",dataFrame.shape)
dataFrame = dataFrame.dropna()
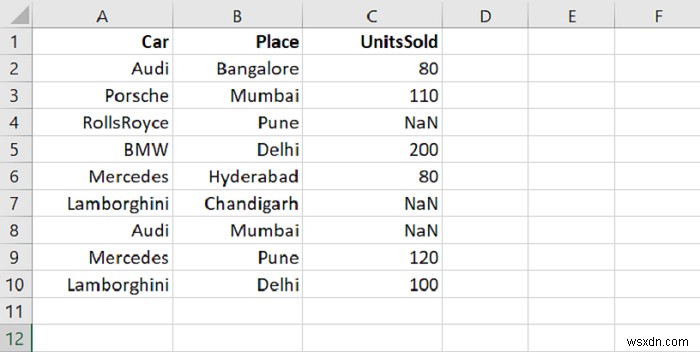
print("\nDataFrame after removing null values...\n",dataFrame)
print("\n(Updated) Number of rows and column in our DataFrame = ",dataFrame.shape)
आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame... Car Place UnitsSold 0 Audi Bangalore 80.0 1 Porsche Mumbai 110.0 2 RollsRoyce Pune NaN 3 BMW Delhi 200.0 4 Mercedes Hyderabad 80.0 5 Lamborghini Chandigarh NaN 6 Audi Mumbai NaN 7 Mercedes Pune 120.0 8 Lamborghini Delhi 100.0 Number of rows and column in our DataFrame = (9, 3) DataFrame after removing null values... Car Place UnitsSold 0 Audi Bangalore 80.0 1 Porsche Mumbai 110.0 3 BMW Delhi 200.0 4 Mercedes Hyderabad 80.0 7 Mercedes Pune 120.0 8 Lamborghini Delhi 100.0 (Updated) Number of rows and column in our DataFrame = (6, 3)