माध्य उच्च आधे को डेटा के निचले आधे हिस्से से अलग करता है। फिलना () विधि का उपयोग करें और लापता कॉलम को माध्यिका से भरने के लिए माध्यिका सेट करें। सबसे पहले, आइए आवश्यक पुस्तकालयों को उनके संबंधित उपनामों के साथ आयात करें -
import pandas as pd import numpy as np
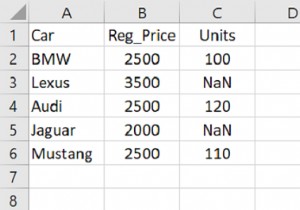
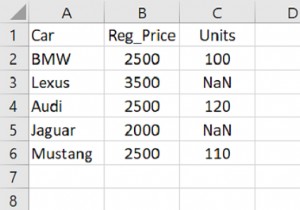
2 कॉलम के साथ डेटाफ़्रेम बनाएं। हमने Numpy np.NaN . का उपयोग करके NaN मान सेट किए हैं -
dataFrame = pd.DataFrame(
{
"Car": ['Lexus', 'BMW', 'Audi', 'Bentley', 'Mustang', 'Tesla'],"Units": [100, 150, np.NaN, 80, np.NaN, np.NaN]
}
) NaN के साथ स्तंभ मानों का माध्यिका ज्ञात कीजिए, अर्थात, यहां इकाइयों के स्तंभों के लिए। NaNs को उस कॉलम के माध्यिका से बदलें, जहां वह यूनिट्स कॉलम पर माध्यिका () का उपयोग करके स्थित है -
dataFrame.fillna(dataFrame['Units'].median(), inplace = True)
उदाहरण
निम्नलिखित कोड है -
import pandas as pd
import numpy as np
# Create DataFrame
dataFrame = pd.DataFrame(
{
"Car": ['Lexus', 'BMW', 'Audi', 'Bentley', 'Mustang', 'Tesla'],"Units": [100, 150, np.NaN, 80, np.NaN, np.NaN]
}
)
print"DataFrame ...\n",dataFrame
# finding median of the column values with NaN i.e, for Units columns here
# Replace NaNs with the median of the column where it is located
dataFrame.fillna(dataFrame['Units'].median(), inplace = True)
print"\nUpdated Dataframe after filling NaN values with median...\n",dataFrame आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame ... Car Units 0 Lexus 100.0 1 BMW 150.0 2 Audi NaN 3 Bentley 80.0 4 Mustang NaN 5 Tesla NaN Updated Dataframe after filling NaN values with median... Car Units 0 Lexus 100.0 1 BMW 150.0 2 Audi 100.0 3 Bentley 80.0 4 Mustang 100.0 5 Tesla 100.0