प्रसरण का विश्लेषण या एनोवा एक उपयोगी विश्लेषण है। 1918 में प्रक्रिया के विकास की शुरुआत से ही इसका व्यापक रूप से उपयोग किया गया है। यह माध्य और विभिन्न समूहों के बीच सांख्यिकीय अंतर को दर्शाता है और यह निर्धारित करता है कि उनका प्रत्येक मूल्य कितना सहसंबद्ध है। एक नेस्टेड एनोवा वह जगह है जहां इन समूहों को कई समूहों में विभाजित किया जाता है जिन्हें हम व्यक्तिगत रूप से सहसंबंधित कर सकते हैं या नहीं भी कर सकते हैं। यह लेख नेस्टेड एनोवा के अवलोकन और एक्सेल में विश्लेषण करने के तरीके पर चर्चा करेगा।
आप नीचे दिए गए लिंक से प्रदर्शन के लिए उपयोग की गई कार्यपुस्तिका डाउनलोड कर सकते हैं।
एनोवा एनालिसिस क्या है?
एनोवा एक सांख्यिकीय पद्धति है जिसका उपयोग डेटासेट के भीतर देखे गए विचरण का विश्लेषण करने के लिए किया जाता है। इसे निष्पादित करने के लिए, हमें डेटासेट को दो वर्गों में विभाजित करने की आवश्यकता है- व्यवस्थित और यादृच्छिक कारक।
एनोवा हमें यह निर्धारित करने देता है कि कौन से कारक दिए गए डेटा के सेट को महत्वपूर्ण रूप से प्रभावित करते हैं। विश्लेषण पूरा करने के बाद, एक विश्लेषक आमतौर पर उन कार्यप्रणाली कारकों पर अतिरिक्त विश्लेषण करता है जो डेटा सेट की असंगत प्रकृति को महत्वपूर्ण रूप से प्रभावित करते हैं। उस मामले में, उसे अनुमानित प्रतिगमन विश्लेषण के लिए प्रासंगिक अतिरिक्त डेटा बनाने के लिए एनोवा निष्कर्षों का उपयोग करने की आवश्यकता है। एनोवा कई डेटा सेट की तुलना यह देखने के लिए करता है कि उनके बीच कोई लिंक है या नहीं।
एनोवा दो प्रकार की होती है, एक एकल कारक . है और दूसरा दो कारक है। एकल कारक में, ANOVA एकल चर पर एक कारक के प्रभाव का पता लगाता है। दूसरी ओर, दो कारकों एनोवा में कई आश्रित चर हैं।
नेस्टेड एनोवा का अवलोकन
नेस्टेड एनोवा, जैसा कि नाम से पता चलता है, में कम से कम एक कारक दूसरे के अंदर निहित होता है।
मान लीजिए कि दो अलग-अलग जगहों पर एक विशिष्ट संगठन के दो स्टोर हैं। उदाहरण के लिए, 2 टीमें हैं- पहले स्टोर में टीम ए और बी और दूसरे में सी और डी टीम। उनकी संबंधित टीम के भीतर सौंपे गए उनकी बिक्री को स्टोर के भीतर नेस्ट किया जाएगा।
लाक्षणिक रूप से, यह ऐसा होगा।
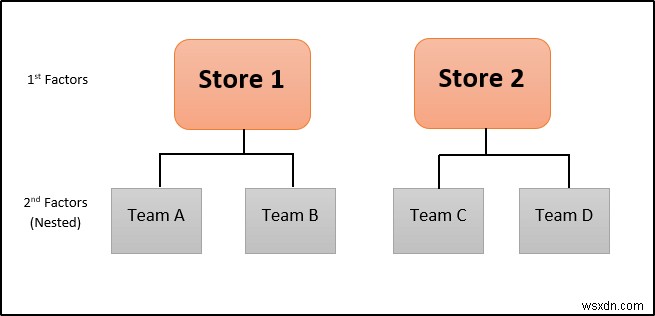
जैसा कि आप चित्र से देख सकते हैं, दूसरा कारक पहले कारक के अंदर निहित है। इसलिए, ऐसी बिक्री का एनोवा विश्लेषण नेस्टेड एनोवा श्रेणी में होगा।
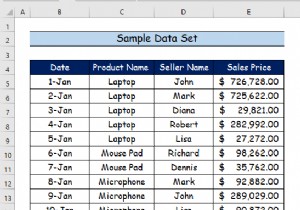
अब रीडिंग या डेटा प्रविष्टियों का डेटा अब स्प्रेडशीट पर इस तरह दिखेगा।
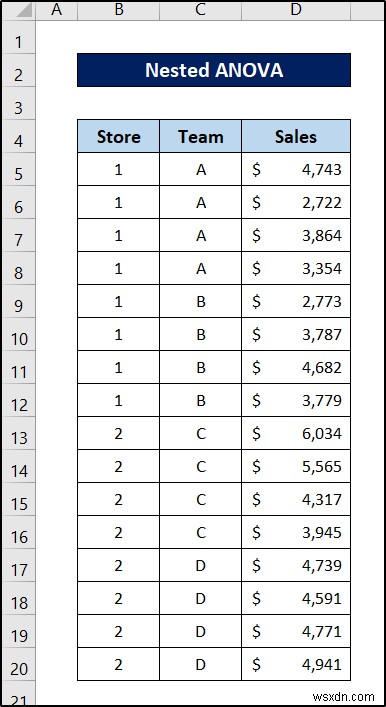
इस डेटा से, हम दो चीजों का विश्लेषण कर सकते हैं- क्या प्रत्येक स्टोर (कारक 1) और प्रत्येक टीम (कारक 2) में बिक्री समान है?
इस डेटा पर ANOVA करने पर (बाद के अनुभाग में इसके बारे में अधिक), हम कुछ इस तरह पाएंगे।
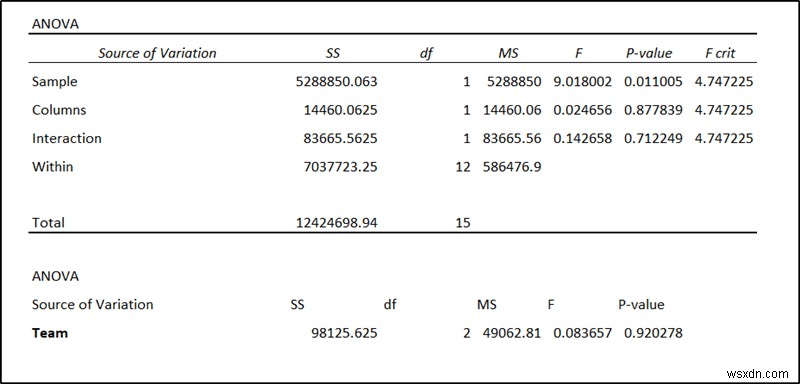
यहां p-मान प्रत्येक कारक के महत्व को आंकेंगे। इस डेटा से, हम देख सकते हैं कि स्टोर का सांख्यिकीय रूप से महत्वपूर्ण प्रभाव है जबकि उनमें टीम नहीं है।
इनमें से अधिक गणनाएं और व्याख्याएं अगले भाग में हैं।
एक्सेल में नेस्टेड एनोवा कैसे करें
नेस्टेड ANOVA को Excel में निष्पादित करने का कोई सीधा तरीका नहीं है। लेकिन हम अभी भी डेटासेट को संशोधित करके और कुछ मैन्युअल गणना करके ऑपरेशन कर सकते हैं। हम डेटा विश्लेषण टूलपैक का उपयोग करेंगे प्रतिकृति के साथ दो कारक यहाँ सुविधा। ध्यान रखें, हो सकता है कि आपके पास डेटा विश्लेषण टूलपैक . न हो डिफ़ॉल्ट रूप से आपके रिबन में। कैसे करें देखने के लिए यहां क्लिक करें डेटा विश्लेषण टूलपैक सक्षम करें . अंत में, हमें F.DIST.RT फ़ंक्शन की आवश्यकता होगी मैन्युअल गणना के लिए।
लेकिन पहले, हमें मूल कच्चे डेटासेट में कुछ संशोधन करने होंगे। क्योंकि हम प्रतिकृति के साथ दो कारक . का प्रदर्शन करेंगे इस पर। आइए पिछले अनुभाग से कच्चे डेटासेट को लें।
अब एक्सेल में नेस्टेड एनोवा करने के चरणों को देखने के लिए इन चरणों का पालन करें।
चरण:
- सबसे पहले, डेटासेट को निम्नलिखित में पुनर्व्यवस्थित करें। हमने टीम सी और डी के बिक्री मूल्यों को ए और बी के तहत शामिल किया ताकि एक्सेल उन्हें पढ़ सके।
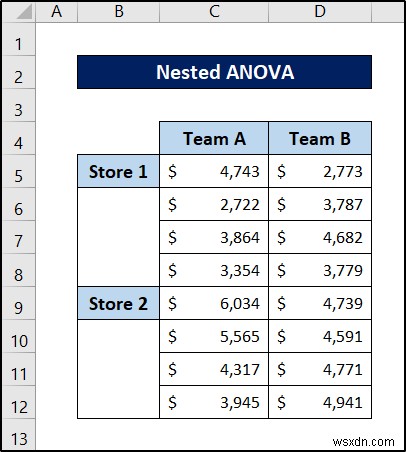
- अब डेटा पर जाएं अपने रिबन पर टैब करें।
- फिर डेटा विश्लेषण select चुनें विश्लेषण . से समूह अनुभाग।

- डेटा विश्लेषण बॉक्स दिखाई देगा।
- अब चुनें अनोवा:प्रतिकृति के साथ दो-कारक विश्लेषण टूल . के अंतर्गत
- फिर ठीक . पर क्लिक करें ।
- अगला, अनोवा:प्रतिकृति के साथ दो-कारक बॉक्स दिखाई देगा। बॉक्स में निम्नलिखित विवरण चुनें।
- सबसे पहले, श्रेणी दर्ज करें B4:D12 इनपुट रेंज के रूप में।
- दूसरा, डालें 4 प्रति नमूना पंक्तियों में फ़ील्ड, क्योंकि हमारे पास नेस्टेड कारकों में से प्रत्येक के लिए चार प्रविष्टियाँ हैं।
- आप अल्फा . को बदल सकते हैं मूल्य भी अगर आपको पसंद है। लेकिन हम इसे 0. . पर रखेंगे 05 अभी के लिए।
- तीसरा, आप आउटपुट विकल्प के अंतर्गत यह चुन सकते हैं कि आप अपने परिणाम कहां प्रदर्शित करना चाहते हैं ।
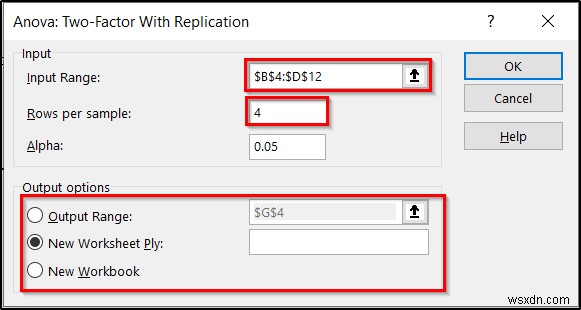
- जब आप इन सभी के साथ कर लें, तो ठीक . पर क्लिक करें ।
- परिणामस्वरूप, आपके द्वारा चयनित स्थान पर परिणाम पॉप अप होगा। हम ANOVA . के अंतर्गत अंतिम भाग का उपयोग करेंगे एक्सेल में नेस्टेड एनोवा विश्लेषण के लिए।
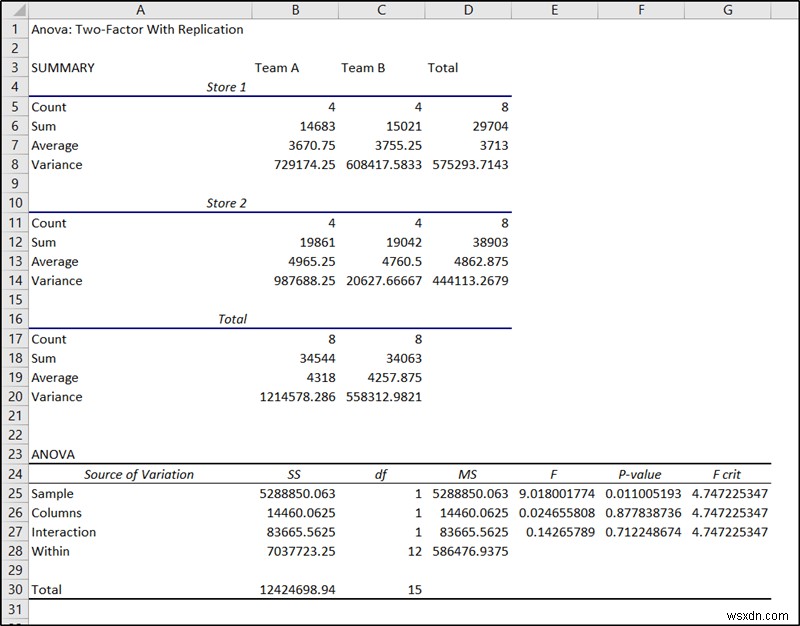
- सेल में नमूने का p-मान F25 नमूने के महत्व को इंगित करता है, जो इस मामले में, पहला कारक, स्टोर है।
- अन्य कारकों के महत्व के लिए, अब हमें कुछ मैन्युअल गणना करने की आवश्यकता है।
- सबसे पहले, सेल चुनें B34 और निम्न सूत्र लिखिए।
=B26+B27
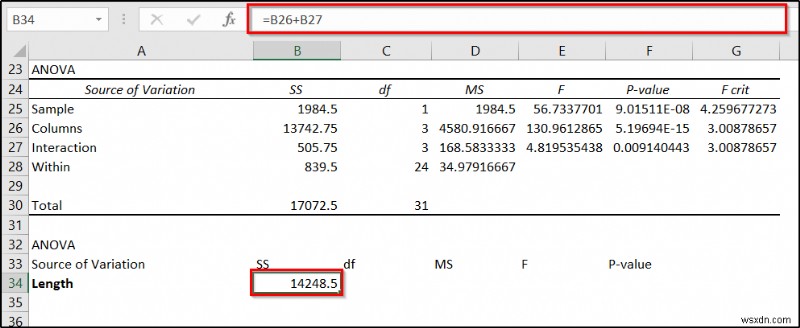
- फिर Enter दबाएं ।
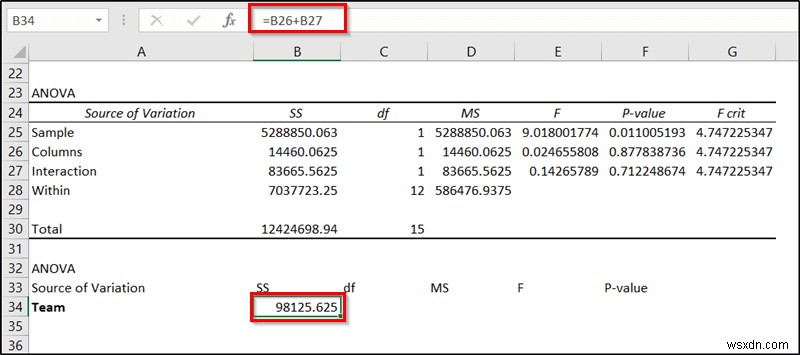
- अब सेल में निम्न सूत्र दर्ज करें C34 और Enter press दबाएं ।
=C26+C27
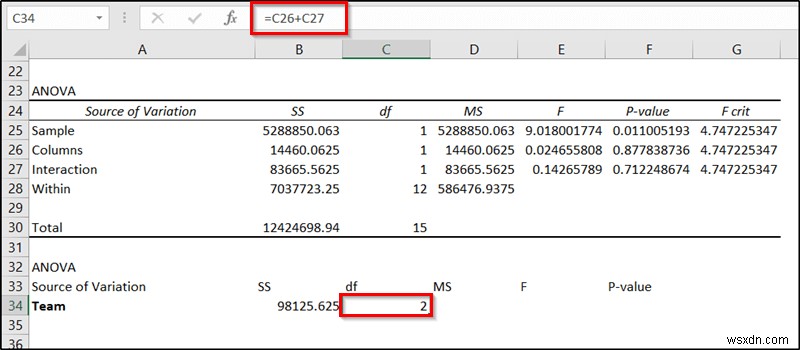
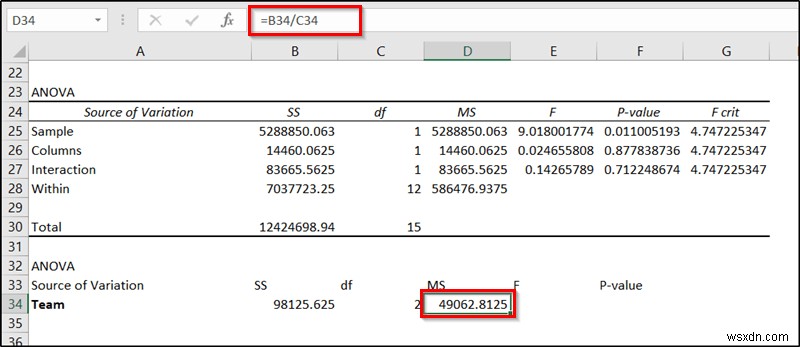
- अगला, निम्न सूत्र को सेल D34 . में डालें और Enter press दबाएं ।
=B34/C34
- उसके बाद, सेल में निम्न सूत्र का उपयोग करें E34 ।
=D34/D28
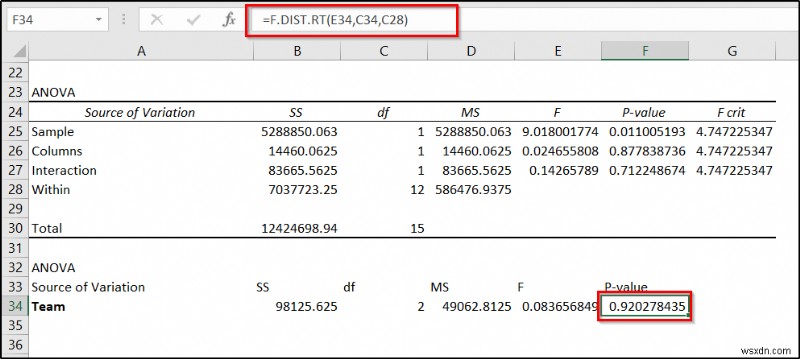
- आखिरकार, सेल में निम्न सूत्र का प्रयोग करें F34 और फिर Enter . दबाएं ।
=F.DIST.RT(E34,C34,C28)
परिणाम की व्याख्या
यदि एनोवा विश्लेषण से किसी कारक का पी-मान 0.05 से कम मान देता है तो इसका डेटा पर महत्वपूर्ण प्रभाव पड़ता है। इस उदाहरण में, हमारे पास दो कारक थे- स्टोर और टीम, जहां टीमों को स्टोर के अंदर नेस्ट किया गया था। इस डेटा के लिए स्टोर का p-मान सेल F25 . में है और टीमों का p-मान सेल F34 . में है ।
जैसा कि आप परिणाम से देख सकते हैं कि स्टोर का पी-वैल्यू 0.011005 है जो 0.05 से कम है। यह इस कारक की बिक्री पर एक महत्वपूर्ण प्रभाव को इंगित करता है। जबकि फैक्टर टीम का पी-वैल्यू 0.9202 है जो 0.05 से अधिक है। जो डेटा या बिक्री पर महत्वपूर्ण प्रभाव का संकेत नहीं देता है। इसलिए हम सुरक्षित रूप से यह निष्कर्ष निकाल सकते हैं कि इस मामले में टीमों के लिए कर्मचारियों के संयोजन की तुलना में स्टोर का स्थान अधिक महत्वपूर्ण है।
इस प्रकार हम एक्सेल में नेस्टेड एनोवा कर सकते हैं।
एक्सेल में नेस्टेड एनोवा के 2 उपयुक्त उदाहरण
नेस्टेड एनोवा करने का सामान्य विचार एक्सेल में समान है। अब हम अलग-अलग मामलों में इसके उपयोग को प्रदर्शित करने के लिए इसे दो अलग-अलग उदाहरणों में लागू करेंगे। ध्यान रखें कि, हमें डेटा विश्लेषण टूलपैक . की आवश्यकता है रिबन में उपलब्ध है। यदि आपके पास एक नहीं है, तो कैसे करें . देखने के लिए यहां क्लिक करें डेटा विश्लेषण टूलपैक सक्षम करें ।
<एच3>1. विभिन्न लंबाई के साथ प्रतिरोध की भिन्नता की गणना करनाइस पहले उदाहरण में, हम निम्नलिखित डेटासेट का उपयोग करेंगे।
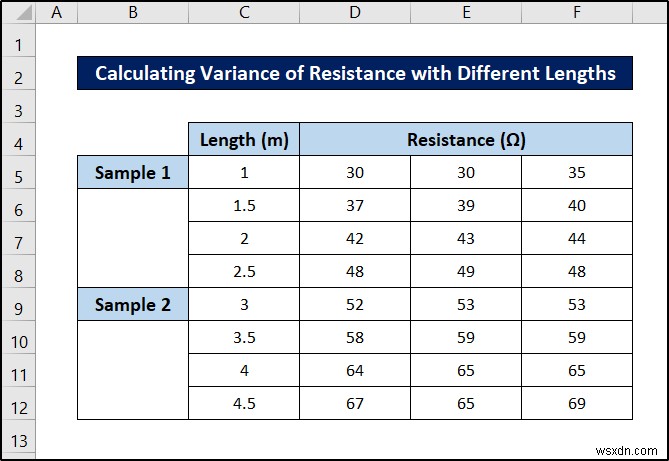
आप कह सकते हैं कि यहां दो घोंसले हैं- प्रतिरोध मान लंबाई के अंदर नेस्टेड हैं, जो बदले में अलग-अलग नमूनों के अंदर घोंसला बनाते हैं।
लेकिन मूल विचार प्रतिकृति के साथ दो-कारक . का उपयोग करना है डेटासेट के लिए। तो हमें इस तरह से डेटासेट की जरूरत है। और पहले की तरह ही, हमें F.DIST.RT फ़ंक्शन . की आवश्यकता होगी अंत में मैनुअल गणना के लिए। यह देखने के लिए चरणों का पालन करें कि हम एक्सेल में इस नेस्टेड डेटासेट में एनोवा कैसे कर सकते हैं।
चरण:
- सबसे पहले, डेटा पर जाएं अपने रिबन पर टैब करें।
- फिर डेटा विश्लेषण select चुनें विश्लेषण . से समूह अनुभाग।
- डेटा विश्लेषण बॉक्स दिखाई देगा।
- अब चुनें अनोवा:प्रतिकृति के साथ दो-कारक विश्लेषण टूल . के अंतर्गत
- फिर ठीक . पर क्लिक करें ।
- अगला, अनोवा:प्रतिकृति के साथ दो-कारक बॉक्स दिखाई देगा। बॉक्स में निम्नलिखित विवरण चुनें।
- सबसे पहले, श्रेणी दर्ज करें B4:F12 इनपुट रेंज के रूप में।
- दूसरा, डालें 4 प्रति नमूना पंक्तियों में फ़ील्ड, क्योंकि हमारे पास नेस्टेड कारकों में से प्रत्येक के लिए चार प्रविष्टियाँ हैं।
- आप अल्फा . को बदल सकते हैं मूल्य भी अगर आपको पसंद है। लेकिन हम इसे 05 . पर रखेंगे अभी के लिए।
- तीसरा, आप आउटपुट विकल्प के अंतर्गत यह चुन सकते हैं कि आप अपने परिणाम कहां प्रदर्शित करना चाहते हैं ।
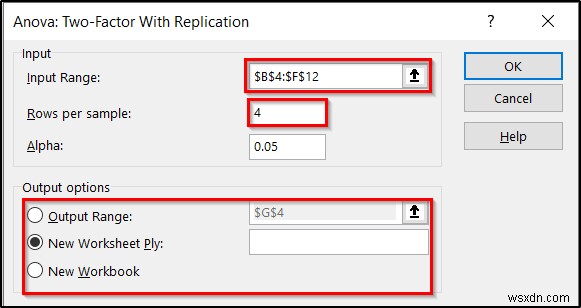
- जब आप इन सभी के साथ कर लें, तो ठीक . पर क्लिक करें ।
- परिणामस्वरूप, आपके द्वारा चयनित स्थान पर परिणाम पॉप अप होगा। हम ANOVA . के अंतर्गत अंतिम भाग का उपयोग करेंगे एक्सेल में नेस्टेड एनोवा विश्लेषण के लिए।
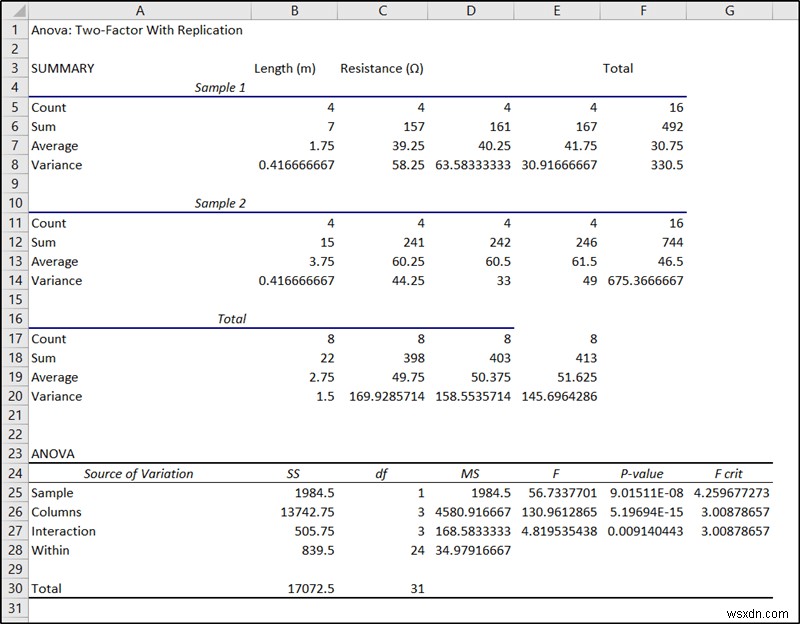
- सेल में नमूने का p-मान F25 नमूने के महत्व को इंगित करता है, जो इस मामले में, पहला कारक, नमूना है।
- अब सेल चुनें B34 और निम्न सूत्र लिखिए।
=B26+B27
- फिर Enter दबाएं ।
- अब सेल में निम्न सूत्र दर्ज करें C34 और Enter press दबाएं ।
=C26+C27
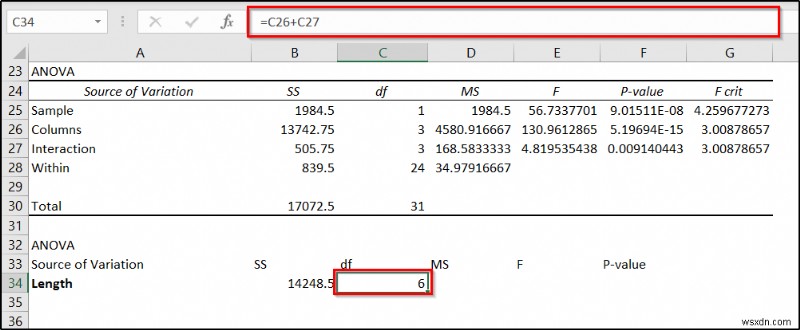
- अगला, निम्न सूत्र को सेल D34 . में डालें और Enter press दबाएं ।
=B34/C34
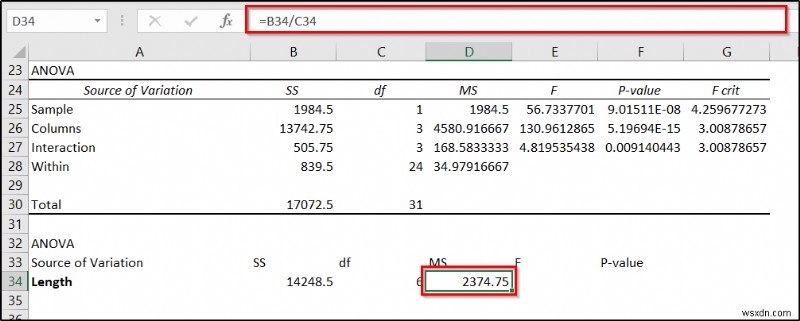
- उसके बाद, सेल में निम्न सूत्र का उपयोग करें E34 ।
=D34/D28
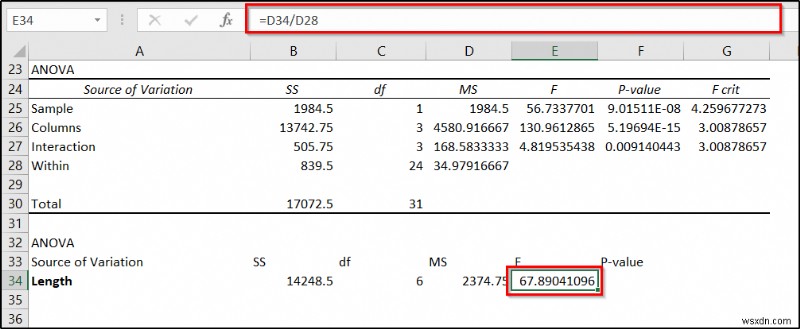
- आखिरकार, सेल में निम्न सूत्र का प्रयोग करें F34 और फिर Enter . दबाएं ।
=F.DIST.RT(E34,C34,C28)
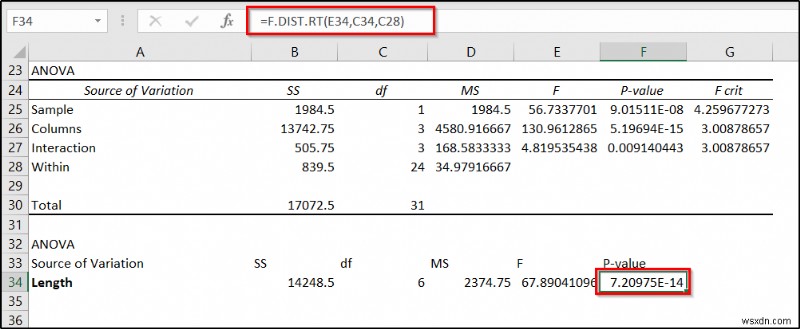
परिणाम की व्याख्या
अंतिम परिणाम में, सेल में p-मान F25 नमूने के महत्व (विभिन्न लंबाई के) और सेल के मूल्य को इंगित करता है F34 प्रतिरोध पर लंबाई के महत्व को इंगित करता है। चूंकि वे दोनों 0.05 के अल्फा मान से नीचे हैं, इसलिए वे दोनों इस उदाहरण में महत्वपूर्ण कारक हैं।
और पढ़ें: एक्सेल में एनोवा परिणामों की व्याख्या कैसे करें (3 तरीके)
समान रीडिंग
- एक्सेल में रिग्रेशन कैसे करें और एनोवा की व्याख्या कैसे करें
- एक्सेल में डू वन वे एनोवा (2 उपयुक्त उदाहरण)
- एनोवा परिणामों को एक्सेल में कैसे ग्राफ़ करें (3 उपयुक्त उदाहरण)
- एक्सेल में एनोवा को दोहराए गए उपाय कैसे करें (आसान चरणों के साथ)
इस दूसरे उदाहरण में, हम निम्नलिखित डेटासेट का उपयोग करेंगे।
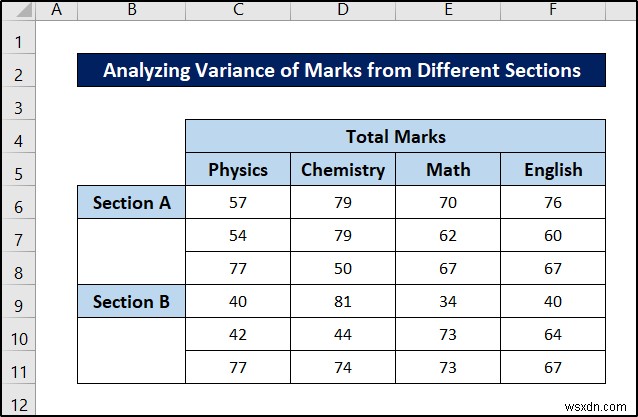
फिर से, यह एक दो-तरफा एनोवा के लिए डेटासेट की तरह लग सकता है। लेकिन यह एक्सेल में विश्लेषण करने के लिए एक पुनर्व्यवस्थित नेस्टेड एनोवा है। और पहले की तरह ही, हमें F.DIST.RT फ़ंक्शन . की आवश्यकता होगी अंत में मैन्युअल गणना के लिए।
यह देखने के लिए इन चरणों का पालन करें कि आप एक्सेल में इस नेस्टेड एनोवा को कैसे निष्पादित कर सकते हैं।
चरण:
- सबसे पहले, डेटा पर जाएं अपने रिबन पर टैब करें।
- फिर डेटा विश्लेषण select चुनें विश्लेषण . से समूह अनुभाग।
- डेटा विश्लेषण बॉक्स दिखाई देगा।
- अब चुनें अनोवा:प्रतिकृति के साथ दो-कारक विश्लेषण टूल . के अंतर्गत
- फिर ठीक . पर क्लिक करें ।
- अगला, अनोवा:प्रतिकृति के साथ दो-कारक बॉक्स दिखाई देगा। बॉक्स में निम्नलिखित विवरण चुनें।
- सबसे पहले, श्रेणी दर्ज करें B5:F11 इनपुट रेंज के रूप में।
- दूसरा, डालें 3 प्रति नमूना पंक्तियों में फ़ील्ड, क्योंकि हमारे पास नेस्टेड कारकों में से प्रत्येक के लिए तीन प्रविष्टियाँ हैं।
- आप अल्फा . को बदल सकते हैं मूल्य भी अगर आपको पसंद है। लेकिन हम इसे 05 . पर रखेंगे अभी के लिए।
- तीसरा, आप आउटपुट विकल्प के अंतर्गत यह चुन सकते हैं कि आप अपने परिणाम कहां प्रदर्शित करना चाहते हैं ।
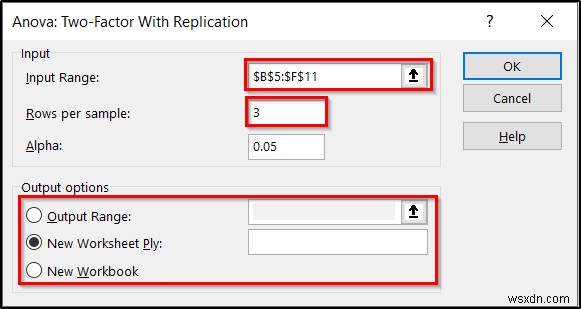
- जब आप इन सभी के साथ कर लें, तो ठीक . पर क्लिक करें ।
- परिणामस्वरूप, आपके द्वारा चयनित स्थान पर परिणाम पॉप अप होगा। We will use the last portion under ANOVA for the nested ANOVA analysis in Excel.
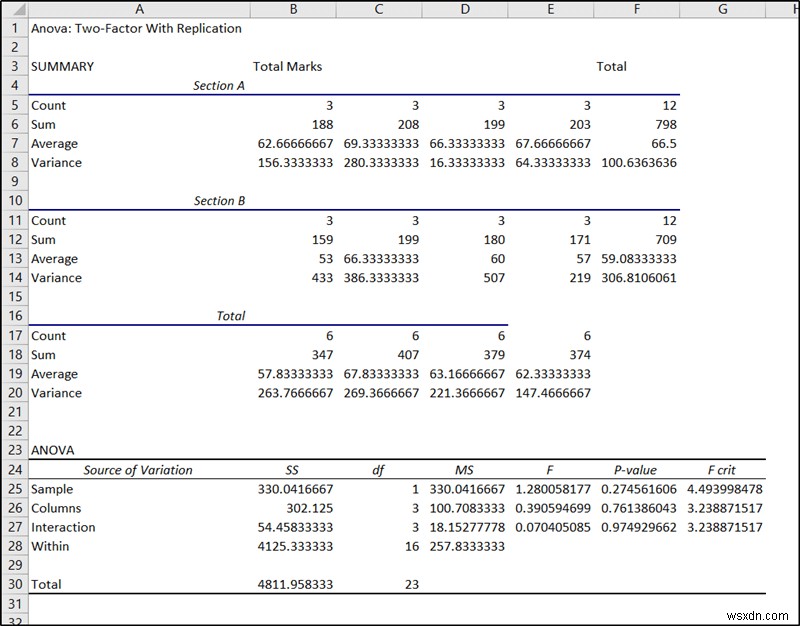
- The p-value of the sample in cell F25 indicates the significance of the sample which is, in this case, the first factor, section.
- Now select cell B34 और निम्न सूत्र लिखिए।
=B26+B27
- फिर Enter दबाएं ।
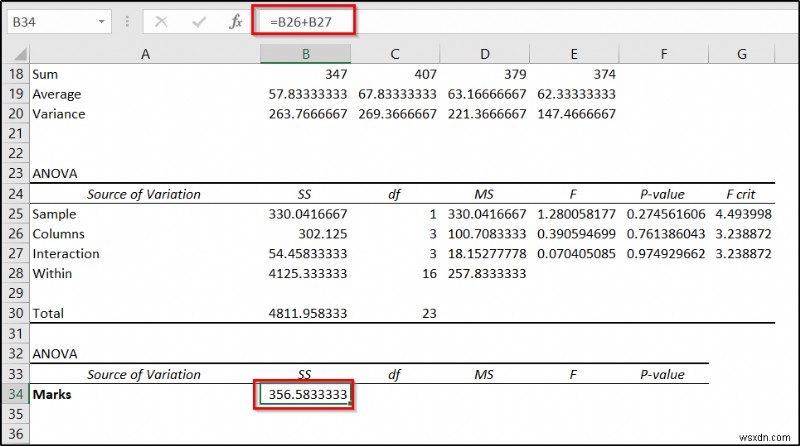
- Now enter the following formula in cell C34 और Enter press दबाएं ।
=C26+C27
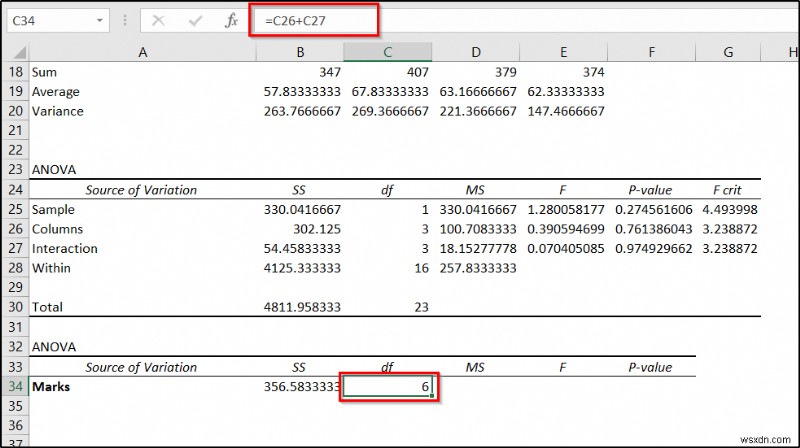
- Next, insert the following formula in cell D34 और Enter press दबाएं ।
=B34/C34
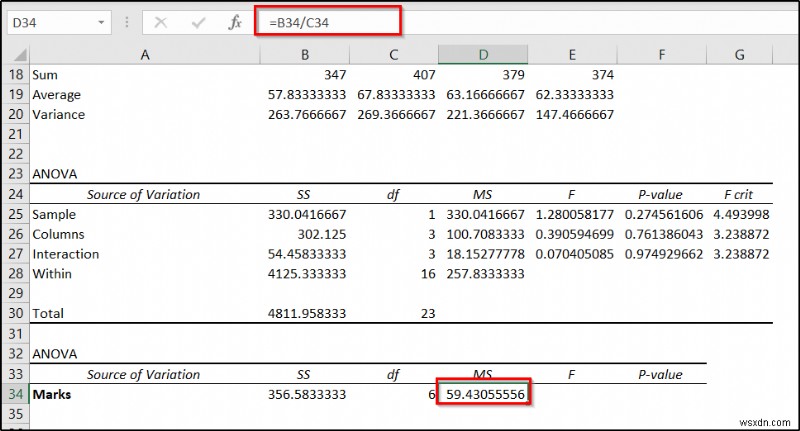
- After that, use the following formula in cell E34 ।
=D34/D28
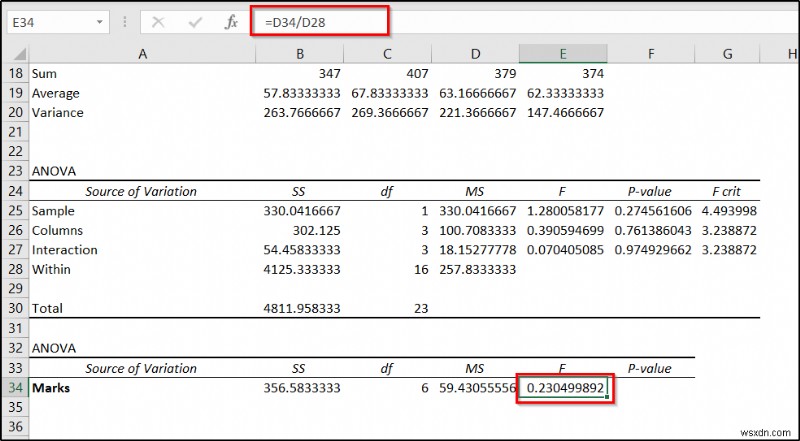
- Finally, use the following formula in cell F34 and then press Enter ।
=F.DIST.RT(E34,C34,C28)
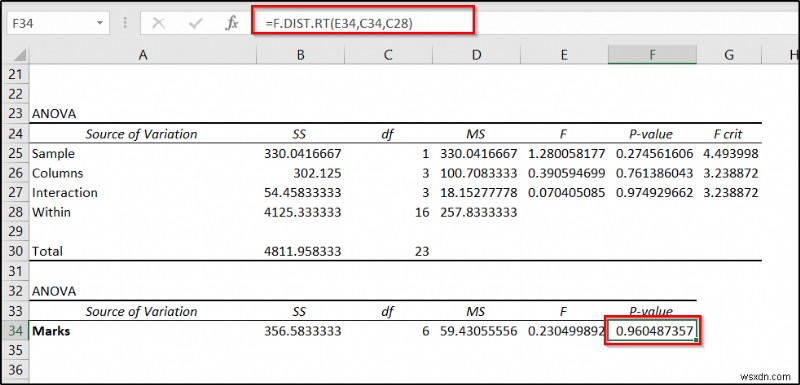
Interpretation of the Result
The p-value in cell F25 indicates the significance of the section on the statistics. This value is greater than the alpha value of 0.05. So this doesn’t have much significance. The cell value of F34 is the p-value of subject marks in the dataset. This, too, is higher than 0.05. So, again, this doesn’t have any significant effect on the marks on different subjects in different sections too for this dataset.
This is another example of how we can perform nested ANOVA in Excel.
और पढ़ें: How to Calculate P Value in Excel ANOVA (3 Suitable Examples)
Things You Should Remember About Nested ANOVA
- A nested ANOVA can have more than two factors. Like the one used in the first example of the previous section, a factor can be nested into one factor. That factor can also be nested into another one on the hierarchy along with other factors of the same level.
- A nested ANOVA is different than a two-way ANOVA. A two-factor ANOVA consists of two factors. Meanwhile, a nested ANOVA must have one of those factors nested inside the other. Which isn’t the case for the two-way ANOVA.
निष्कर्ष
So this was the method to perform a nested ANOVA in Excel. Hopefully, you have grasped the concept of using nested ANOVA in Excel with the two-way replication feature and can use it accordingly for your datasets. मुझे आशा है कि आपको यह मार्गदर्शिका सहायक और ज्ञानवर्धक लगी होगी। यदि आपके कोई प्रश्न या सुझाव हैं, तो हमें नीचे टिप्पणी में बताएं।
For more guides like this, visit Exceldemy.com ।
संबंधित लेख
- How to Apply Rows Per Sample ANOVA in Excel (2 Easy Methods)
- How to Make an ANOVA Table in Excel (3 Suitable Ways)
- Randomized Block Design ANOVA in Excel (with Easy Steps)
- How to Use ANOVA Two Factor Without Replication in Excel