पांडा डेटा सफाई, डेटा विश्लेषण आदि के लिए एक बहुत व्यापक रूप से इस्तेमाल किया जाने वाला पायथन पुस्तकालय है। इस लेख में हम देखेंगे कि हम किसी दिए गए डेटा सेट से विशिष्ट डेटा प्राप्त करने के लिए क्वेरी विधि का उपयोग कैसे कर सकते हैं। हमारे पास एक क्वेरी के अंदर सिंगल और मल्टीपल दोनों स्थितियां हो सकती हैं।
डेटा पढ़ना
आइए पहले पांडा लाइब्रेरी का उपयोग करके डेटा को पांडा डेटा फ़्रेम में पढ़ें। नीचे दिया गया प्रोग्राम बस यही करता है।
उदाहरण
import pandas as pd
# Reading data frame from csv file
data = pd.read_csv("D:\\heart.csv")
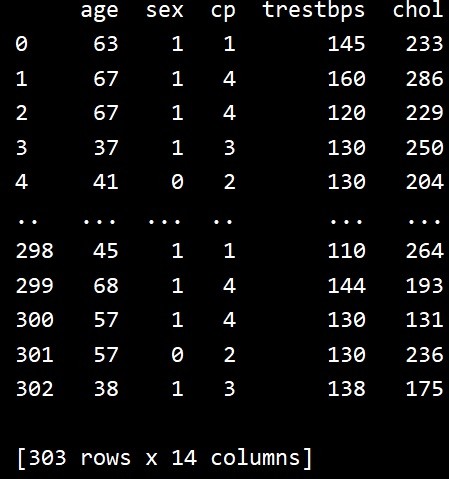
print(data) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
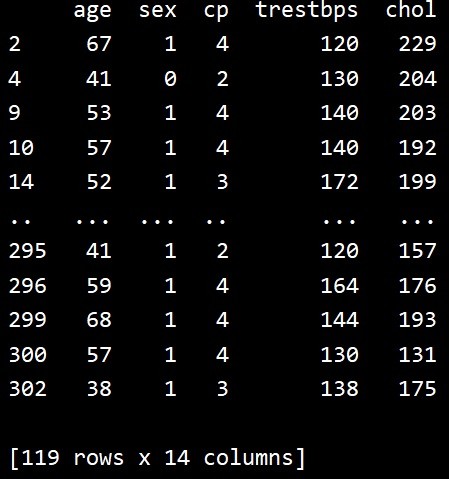
एकल शर्त वाली क्वेरी
आगे हम देखते हैं कि हम सिंगल कंडीशन के साथ क्वेरी मेथड का उपयोग कैसे कर सकते हैं। जैसा कि आप देख सकते हैं कि मूल 303 पंक्तियों में से केवल 119 पंक्तियाँ ही परिणाम के रूप में वापस आती हैं।
उदाहरण
import pandas as pd
# Data frame from csv file
data = pd.read_csv("D:\\heart.csv")
data.query('chol < 230', inplace=True)
# Result
print(data) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
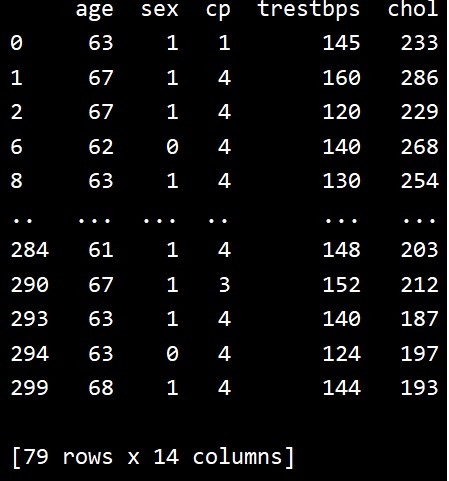
एकाधिक शर्तों वाली क्वेरी
ऊपर के समान दृष्टिकोण में हम क्वेरी विधि में कई शर्तें लागू कर सकते हैं। यह परिणाम डेटा सेट को और प्रतिबंधित कर देगा। अब केवल 79 पंक्तियाँ वापस आती हैं जब हम आयु को 60 से अधिक तक सीमित करते हैं।
उदाहरण
import pandas as pd
# Data frame from csv file
data = pd.read_csv("D:\\heart.csv")
data.query('chol < 230' and 'age > 60', inplace=True)
# Result
print(data) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -