<पी> एक्सेल डेटा विश्लेषण के लिए सबसे शक्तिशाली उपकरणों में से एक है, लेकिन इसकी सीमाएँ हैं। जब डेटासेट लाखों पंक्तियों में विकसित हो जाते हैं, जब रिपोर्ट को स्वचालित रूप से चलाने की आवश्यकता होती है, या जब विश्लेषण के लिए मशीन लर्निंग की आवश्यकता होती है, तो एक्सेल अकेले ही अपनी उम्र दिखाना शुरू कर देता है। पायथन इनमें से कई कमियों को भरता है। पायथन एकीकरण ने एक्सेल को पारंपरिक स्प्रेडशीट टूल से अधिक शक्तिशाली डेटा विश्लेषण प्लेटफ़ॉर्म में बदल दिया है। एक्सेल के अंदर सीधे उपलब्ध पायथन के साथ, विश्लेषक अब उन्नत गणना कर सकते हैं, पूर्वानुमानित मॉडल बना सकते हैं, और अपनी कार्यपुस्तिका को छोड़े बिना परिष्कृत विज़ुअलाइज़ेशन उत्पन्न कर सकते हैं। <पी> इस ट्यूटोरियल में, हम उन्नत एक्सेल डेटा विश्लेषण के लिए पांच पायथन लाइब्रेरी दिखाएंगे जिनका उपयोग प्रत्येक पेशेवर को करना चाहिए। ये लाइब्रेरी आपको एक्सेल के भीतर सीधे उन्नत डेटा हेरफेर, विज़ुअलाइज़ेशन और मशीन लर्निंग करने की अनुमति देती हैं।
1. पांडा - डेटा हेरफेर और विश्लेषण का मूल
<पी> यदि आप एक्सेल विश्लेषण के लिए केवल एक पायथन लाइब्रेरी सीखते हैं, तो पांडा सीखें प्रथम. पांडाज़, पायथन में लगभग हर उन्नत एक्सेल-संबंधित कार्य की नींव है। यह Excel डेटा को शक्तिशाली DataFrames में बदल देता है बड़े डेटासेट की सफाई, परिवर्तन, फ़िल्टरिंग, समूहीकरण, विलय, एकत्रीकरण और कुशलतापूर्वक खोज के लिए। <पी> एक्सेल पेशेवरों के लिए मुख्य ताकतें:- pd.read_excel() के साथ Excel फ़ाइलों को मूल रूप से पढ़ें और लिखें और df.to_excel()
- अव्यवस्थित डेटा को संभालें:डुप्लिकेट हटाएं, गायब मान भरें, और प्रारूपों को मानकीकृत करें
- PivotTables से आगे जाने वाले तर्क के साथ उन्नत समूहीकरण और एकत्रीकरण निष्पादित करें
- एकाधिक शीट या फ़ाइलों को मर्ज करना या जोड़ना
- df.describe() के साथ सांख्यिकीय सारांश तैयार करें
- कोड की कुछ पंक्तियाँ चलाएँ और हर बार एक ही परिणाम प्राप्त करें
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
<पी> 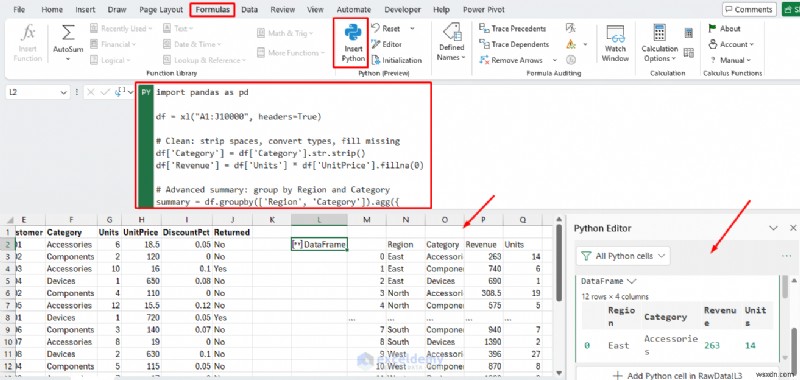 <पी> वीएस कोड में पायथन:
<पी> वीएस कोड में पायथन: import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
<पी> 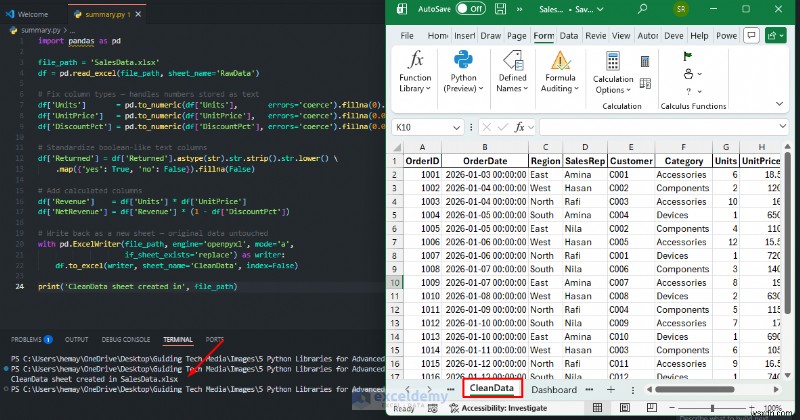 <पी> सारांश रिपोर्ट स्वचालित करना <पी> मैन्युअल PivotTables को Pandas groupby से बदलें वर्कफ़्लो जो सेकंडों में चलता है और हर बार आपका डेटा अपडेट होने पर एक रेडी-टू-शेयर शीट निर्यात करता है:
<पी> सारांश रिपोर्ट स्वचालित करना <पी> मैन्युअल PivotTables को Pandas groupby से बदलें वर्कफ़्लो जो सेकंडों में चलता है और हर बार आपका डेटा अपडेट होने पर एक रेडी-टू-शेयर शीट निर्यात करता है: summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
<पी> 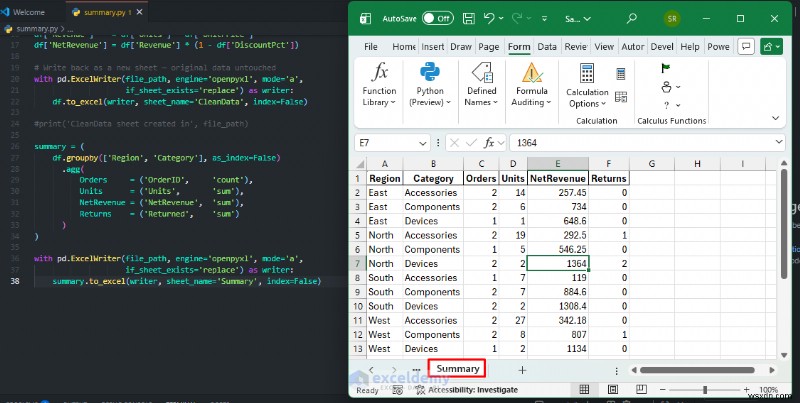 <पी> कब उपयोग करें: आपको PivotTable-शैली आउटपुट मिलता है, लेकिन सफाई और तर्क एक ही वर्कफ़्लो में होते हैं। इसका मतलब है कम टूटी हुई रिपोर्टें और कम मैन्युअल हस्तक्षेप। पावर उपयोगकर्ता देशी एक्सेल के लिए बहुत बड़े या बहुत जटिल डेटासेट को संभालने के लिए पांडा पर भरोसा करते हैं, खासकर जब डेटासेट कुछ हजार पंक्तियों से अधिक हो, जब आपको सफाई या सारांश चरण को दोहराने की आवश्यकता होती है, या जब आपको कई स्रोतों से डेटा को स्वचालित रूप से मर्ज करने की आवश्यकता होती है।
<पी> कब उपयोग करें: आपको PivotTable-शैली आउटपुट मिलता है, लेकिन सफाई और तर्क एक ही वर्कफ़्लो में होते हैं। इसका मतलब है कम टूटी हुई रिपोर्टें और कम मैन्युअल हस्तक्षेप। पावर उपयोगकर्ता देशी एक्सेल के लिए बहुत बड़े या बहुत जटिल डेटासेट को संभालने के लिए पांडा पर भरोसा करते हैं, खासकर जब डेटासेट कुछ हजार पंक्तियों से अधिक हो, जब आपको सफाई या सारांश चरण को दोहराने की आवश्यकता होती है, या जब आपको कई स्रोतों से डेटा को स्वचालित रूप से मर्ज करने की आवश्यकता होती है। 2. OpenPyXL - उन्नत एक्सेल फ़ाइल हेरफेर और मूल स्वरूपण
<पी> जबकि पांडा डेटा संभालते हैं, OpenPyXL .xlsx पर बेहतरीन नियंत्रण में उत्कृष्टता फ़ाइलें:एक्सेल-मूल सुविधाओं को खोए बिना सेल को फ़ॉर्मेट करना, चार्ट, तालिकाओं, शैलियों, सूत्रों और छवियों को जोड़ना। यह आपको .xlsx के साथ सीधे काम करने की सुविधा देता है फ़ाइलें, ताकि आपका पायथन वर्कफ़्लो अकेले कच्चे विश्लेषण के बजाय एक्सेल-तैयार आउटपुट उत्पन्न कर सके। <पी> एक्सेल पेशेवरों के लिए मुख्य ताकतें:- प्रोग्रामेटिक रूप से कार्यपुस्तिकाएं बनाएं और संशोधित करें
- साफ़ की गई तालिकाओं को नई शीट में निर्यात करें
- पेशेवर चार्ट को सीधे एक्सेल प्रारूप में जोड़ें जो स्वचालित रूप से अपडेट हो जाते हैं
- पुरानी रिपोर्ट टैब स्वचालित रूप से बदलें
- विशिष्ट कक्षों पर सशर्त स्वरूपण, बॉर्डर, फ़ॉन्ट और शैलियाँ लागू करें
- एक्सेल फ़ॉर्मूले जैसे =SUM() इंजेक्ट करें या =VLOOKUP() कोशिकाओं में
- शीट्स, फ़्रीज़ पैन को सुरक्षित रखें, और कॉलम की चौड़ाई प्रोग्रामेटिक रूप से सेट करें
- गैर-पायथन उपयोगकर्ताओं के लिए कार्यपुस्तिका-आधारित डिलिवरेबल्स बनाएं
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
<पी> 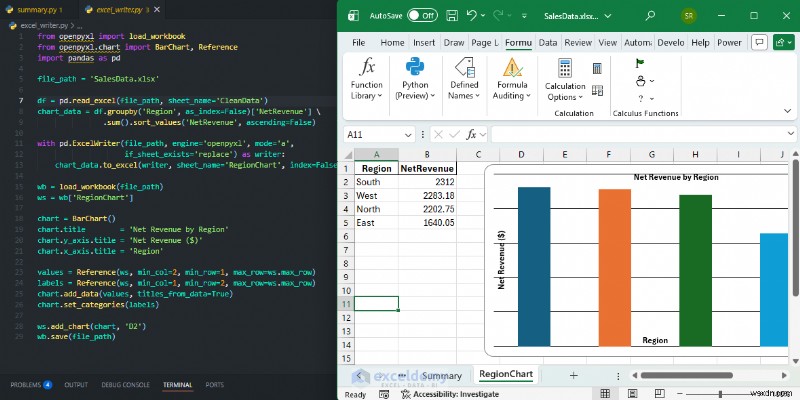 <पी> कब उपयोग करें: पांडा आपको डेटा का विश्लेषण करने में मदद करता है। openpyxl आपको इसे डिलीवर करने में मदद करता है। जब आपको पिक्सेल-परफेक्ट एक्सेल आउटपुट जैसे रिपोर्ट और डैशबोर्ड जो हाथ से तैयार किए गए हों, और जब परिणाम को .xlsx में रहने की आवश्यकता हो, तो OpenPyXL का उपयोग करें। मूल एक्सेल चार्ट और फ़ॉर्मेटिंग वाली फ़ाइल जिसे सहकर्मी संपादित करना जारी रख सकते हैं।
<पी> कब उपयोग करें: पांडा आपको डेटा का विश्लेषण करने में मदद करता है। openpyxl आपको इसे डिलीवर करने में मदद करता है। जब आपको पिक्सेल-परफेक्ट एक्सेल आउटपुट जैसे रिपोर्ट और डैशबोर्ड जो हाथ से तैयार किए गए हों, और जब परिणाम को .xlsx में रहने की आवश्यकता हो, तो OpenPyXL का उपयोग करें। मूल एक्सेल चार्ट और फ़ॉर्मेटिंग वाली फ़ाइल जिसे सहकर्मी संपादित करना जारी रख सकते हैं। 3. मैटप्लोटलिब - एक्सेल चार्ट से परे शक्तिशाली विज़ुअलाइज़ेशन
<पी> एक्सेल चार्ट सुविधाजनक हैं, लेकिन Matplotlib विश्लेषकों को अधिक नियंत्रण देता है। Matplotlib स्थिर, प्रकाशन-गुणवत्ता वाले प्लॉट बनाने के लिए पसंदीदा लाइब्रेरी है। यह अत्यधिक अनुकूलन योग्य है और त्वरित खोजपूर्ण विश्लेषण के लिए पांडा के साथ अच्छी तरह से एकीकृत होता है। <पी> एक्सेल पेशेवरों के लिए मुख्य ताकतें:- हीटमैप, ट्रेंडलाइन के साथ स्कैटर प्लॉट, बॉक्स प्लॉट, हिस्टोग्राम और 3डी चार्ट जैसे उन्नत प्लॉट बनाएं
- फ़ॉन्ट, रंग, ग्रिडलाइन, टिक मार्क और लेजेंड पर अधिक नियंत्रण प्राप्त करें
- मल्टी-पैनल सबप्लॉट लेआउट बनाएं जो एक साथ कई चार्ट दिखाएं
- छवियों, PDF, या SVG में निर्यात करें, या OpenPyXL के साथ विज़ुअल को Excel में वापस एम्बेड करें
- कस्टम लेबल और तीरों के साथ डेटा बिंदुओं को एनोटेट करें
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
<पी> 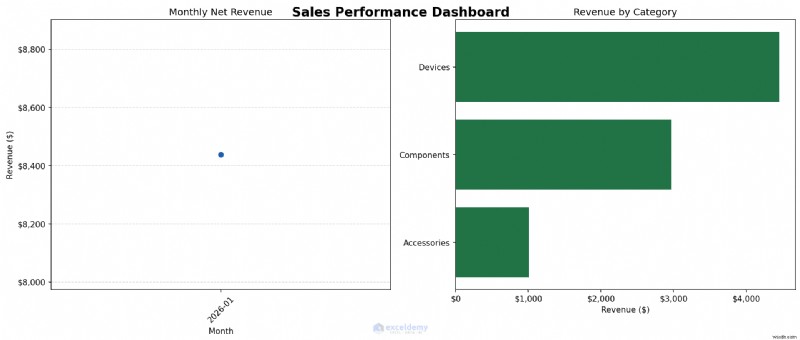 <पी> कब उपयोग करें: पहले विश्लेषण चार्ट तैयार करने के लिए पायथन का उपयोग करें। फिर तय करें कि क्या चार्ट को पायथन आउटपुट रहना चाहिए या क्या सारांशित डेटा को अंतिम डैशबोर्ड फ़ॉर्मेटिंग के लिए एक्सेल में वापस किया जाना चाहिए। जब आपको रिपोर्ट या प्रस्तुतियों के लिए चार्ट की आवश्यकता हो, या जब आपको लगातार स्टाइल के साथ अद्यतन डेटा से एक ही चार्ट को बार-बार बनाने की आवश्यकता हो तो मैटप्लोटलिब का उपयोग करें।
<पी> कब उपयोग करें: पहले विश्लेषण चार्ट तैयार करने के लिए पायथन का उपयोग करें। फिर तय करें कि क्या चार्ट को पायथन आउटपुट रहना चाहिए या क्या सारांशित डेटा को अंतिम डैशबोर्ड फ़ॉर्मेटिंग के लिए एक्सेल में वापस किया जाना चाहिए। जब आपको रिपोर्ट या प्रस्तुतियों के लिए चार्ट की आवश्यकता हो, या जब आपको लगातार स्टाइल के साथ अद्यतन डेटा से एक ही चार्ट को बार-बार बनाने की आवश्यकता हो तो मैटप्लोटलिब का उपयोग करें। 4. सीबॉर्न - सांख्यिकीय डेटा विज़ुअलाइज़ेशन
<पी> समुद्री जन्म Matplotlib पर निर्मित होता है और सांख्यिकीय विज़ुअलाइज़ेशन पर ध्यान केंद्रित करता है। यह देखने में आकर्षक चार्ट बनाने को सरल बनाता है जो पैटर्न और सहसंबंधों को उजागर करते हैं। जहां मैटप्लोटलिब को एक परिष्कृत चार्ट के लिए दर्जनों लाइनों की आवश्यकता हो सकती है, वहीं सीबॉर्न अक्सर आकर्षक डिफ़ॉल्ट स्टाइल के साथ एक या दो लाइनों में समान परिणाम प्राप्त कर सकता है। यह आपके डेटा में छिपे वितरण, सहसंबंध और पैटर्न को प्रकट करने में उत्कृष्टता प्राप्त करता है। <पी> एक्सेल पेशेवरों के लिए मुख्य ताकतें:- जल्दी से सांख्यिकीय चार्ट बनाएं
- खोजपूर्ण डेटा विश्लेषण के लिए अच्छा काम करें
- कॉलम एक दूसरे से कैसे संबंधित हैं यह देखने के लिए सहसंबंध हीटमैप बनाएं
- अंतर्निहित घनत्व वक्रों के साथ वितरण प्लॉट बनाएं
- समूहों की दृष्टिगत तुलना करने के लिए बॉक्स प्लॉट और वायलिन प्लॉट का उपयोग करें
- संख्यात्मक स्तंभों में एक स्वचालित स्कैटरप्लॉट मैट्रिक्स के लिए जोड़ी प्लॉट बनाएं
- एक पंक्ति में आत्मविश्वास अंतराल के साथ प्रतिगमन प्लॉट उत्पन्न करें
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
<पी> 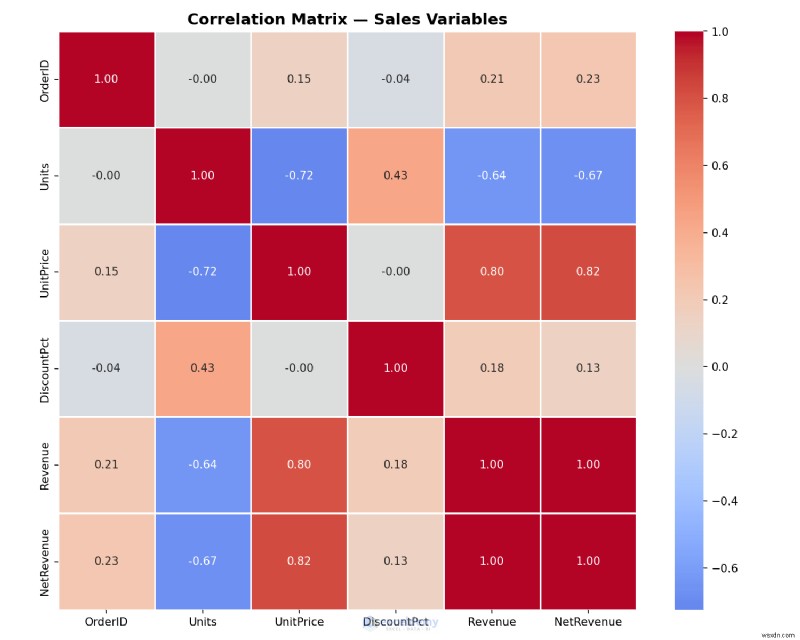 <पी> उदाहरण:एक पंक्ति में एक बॉक्स प्लॉट बनाना <पी> आउटलेर्स का तुरंत पता लगाने के लिए विभिन्न क्षेत्रों में राजस्व वितरण की तुलना करें।
<पी> उदाहरण:एक पंक्ति में एक बॉक्स प्लॉट बनाना <पी> आउटलेर्स का तुरंत पता लगाने के लिए विभिन्न क्षेत्रों में राजस्व वितरण की तुलना करें। plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
<पी> 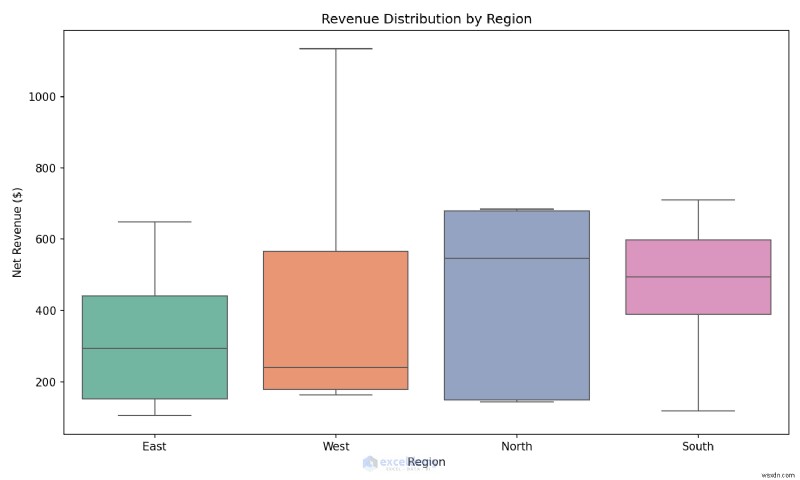 <पी> कब उपयोग करें: जब आप औपचारिक रिपोर्ट बनाने से पहले वितरण, आउटलेयर और रिश्तों को जल्दी से समझना चाहते हैं तो खोजपूर्ण विश्लेषण के दौरान सीबॉर्न का उपयोग करें।
<पी> कब उपयोग करें: जब आप औपचारिक रिपोर्ट बनाने से पहले वितरण, आउटलेयर और रिश्तों को जल्दी से समझना चाहते हैं तो खोजपूर्ण विश्लेषण के दौरान सीबॉर्न का उपयोग करें। 5. स्किकिट-लर्न - सीधे एक्सेल डेटा पर मशीन लर्निंग
<पी> यह वह पुस्तकालय है जो आपको रिपोर्टिंग से निर्णय समर्थन की ओर ले जाता है। स्किकिट-लर्न आपके एक्सेल वर्कफ़्लो में पेशेवर मशीन लर्निंग लाता है। यह एक्सेल उपयोगकर्ताओं के लिए पूर्वानुमानित विश्लेषण को सक्षम बनाता है, जिसमें प्रतिगमन, वर्गीकरण, क्लस्टरिंग और पूर्वानुमान शामिल है जिसे मूल एक्सेल आसानी से संभाल नहीं सकता है। केवल आपके डेटा में क्या हुआ इसका वर्णन करने के बजाय, यह आपको यह अनुमान लगाने में मदद करता है कि बिक्री की भविष्यवाणी करने से लेकर ग्राहकों को वर्गीकृत करने से लेकर विसंगतियों का पता लगाने तक, आगे क्या हो सकता है। <पी> एक्सेल पेशेवरों के लिए मुख्य ताकतें:- संख्यात्मक परिणामों या श्रेणियों जैसे मंथन जोखिम या बिक्री पूर्वानुमान की भविष्यवाणी करने के लिए रैखिक और लॉजिस्टिक प्रतिगमन
- व्याख्या योग्य भविष्यवाणियों के लिए निर्णय वृक्ष और यादृच्छिक वन
- K- का अर्थ है स्वचालित रूप से समान रिकॉर्ड को समूहीकृत करना
- मॉडल सटीकता को मापने के लिए ट्रेन-परीक्षण विभाजन और क्रॉस-सत्यापन
- सुविधा स्केलिंग, एन्कोडिंग, और प्रीप्रोसेसिंग पाइपलाइन
- फ़िल्टरिंग और सॉर्टिंग के लिए एक्सेल में पूर्वानुमान लौटाएं
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
<पी> 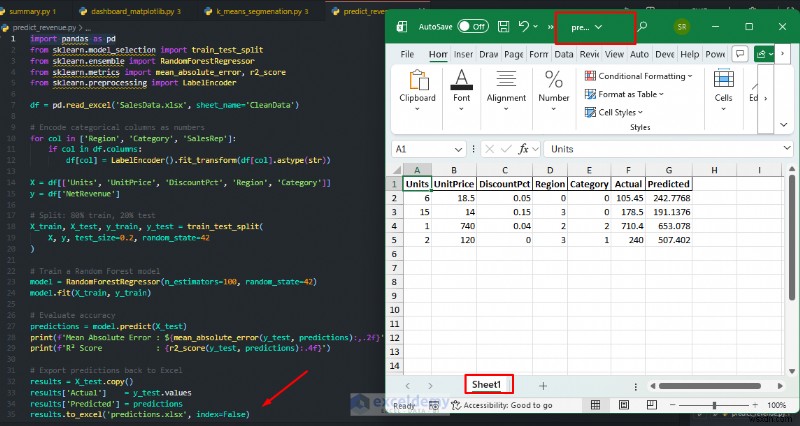 <पी> K-मतलब ग्राहक विभाजन: <पी> बिना किसी मैन्युअल मानदंड के ग्राहकों को खरीदारी व्यवहार के आधार पर समूहों में स्वचालित रूप से विभाजित करें।
<पी> K-मतलब ग्राहक विभाजन: <पी> बिना किसी मैन्युअल मानदंड के ग्राहकों को खरीदारी व्यवहार के आधार पर समूहों में स्वचालित रूप से विभाजित करें। import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
<पी> 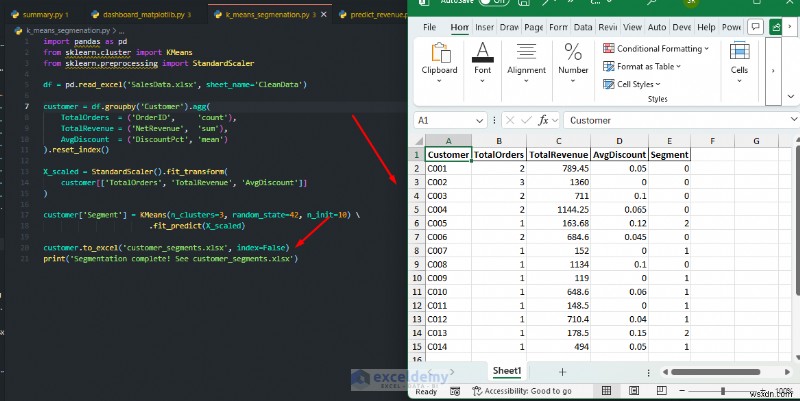 <पी> कब उपयोग करें: आप भविष्यवाणियों को वर्कशीट में वापस लिख सकते हैं, फिर एक्सेल उपयोगकर्ताओं को फ़िल्टर, सॉर्ट, चार्ट, या सूत्रों और सशर्त स्वरूपण के साथ परिणामों को संयोजित करने दें। यह पेशेवरों को मशीन लर्निंग अंतर्दृष्टि को सीधे स्प्रेडशीट में जोड़ने की अनुमति देता है। जब आपको भविष्य के मूल्यों का पूर्वानुमान लगाने, रिकॉर्ड को वर्गीकृत करने, या प्राकृतिक समूहों की खोज करने की आवश्यकता हो, जिन्हें पिवोटटेबल्स प्रकट नहीं कर सकते, तो स्किकिट-लर्न का उपयोग करें।
<पी> कब उपयोग करें: आप भविष्यवाणियों को वर्कशीट में वापस लिख सकते हैं, फिर एक्सेल उपयोगकर्ताओं को फ़िल्टर, सॉर्ट, चार्ट, या सूत्रों और सशर्त स्वरूपण के साथ परिणामों को संयोजित करने दें। यह पेशेवरों को मशीन लर्निंग अंतर्दृष्टि को सीधे स्प्रेडशीट में जोड़ने की अनुमति देता है। जब आपको भविष्य के मूल्यों का पूर्वानुमान लगाने, रिकॉर्ड को वर्गीकृत करने, या प्राकृतिक समूहों की खोज करने की आवश्यकता हो, जिन्हें पिवोटटेबल्स प्रकट नहीं कर सकते, तो स्किकिट-लर्न का उपयोग करें। बोनस:Xlwings - द्वि-दिशात्मक स्वचालन और लाइव एक्सेल एकीकरण
<पी> xlwings लाइब्रेरी वास्तविक समय में एक्सेल इंस्टेंस चलाती है। यह सच्चे स्वचालन को सक्षम करते हुए, पायथन और एक्सेल को जोड़ता है। जबकि openpyxl स्थिर फ़ाइलों को पढ़ता और लिखता है, xlwings Excel को खोल सकता है, उसमें लाइव हेरफेर कर सकता है, मूल्यों को वापस Python में पढ़ सकता है, Excel बटन से Python फ़ंक्शंस को ट्रिगर कर सकता है, और कोशिकाओं में दिखाई देने वाले पूर्ण UDF (उपयोगकर्ता-परिभाषित फ़ंक्शंस) का निर्माण कर सकता है। यह कई VBA-आधारित वर्कफ़्लोज़ का एक आधुनिक विकल्प है। <पी> एक्सेल पेशेवरों के लिए मुख्य ताकतें:- लाइव एक्सेल सत्र को नियंत्रित करें:कार्यपुस्तिकाओं को प्रोग्रामेटिक रूप से खोलें, पढ़ें, लिखें और बंद करें
- एक्सेल सेल से सीधे कॉल करने योग्य पायथन फ़ंक्शन को यूडीएफ के रूप में लिखें
- डेटा को ताज़ा करने और रिपोर्ट तैयार करने जैसे दोहराए जाने वाले कार्यों को स्वचालित करें
- पांडा डेटाफ़्रेम और मैटप्लोटलिब चार्ट को सीधे नामित श्रेणियों में पुश करें
- एक्सेल बटन द्वारा ट्रिगर की गई पायथन स्क्रिप्ट चलाएँ
- Windows और macOS दोनों पर काम करें
- डेस्कटॉप वर्कफ़्लो के लिए Excel में Python के एक मजबूत विकल्प या पूरक के रूप में कार्य करें
विभिन्न एक्सेल पेशेवरों के लिए सर्वश्रेष्ठ लाइब्रेरी स्टैक चुनना
<पी> प्रत्येक विश्लेषक को एक साथ सभी पाँच पुस्तकालयों की आवश्यकता नहीं होती है। उन्हें अपनाने का एक व्यावहारिक तरीका भूमिका है।- रिपोर्टिंग विश्लेषकों के लिए: यह संयोजन आपको डेटा साफ़ करने, सारांश बनाने, चार्ट बनाने और पॉलिश किए गए कार्यपुस्तिका आउटपुट निर्यात करने देता है।
- पांडा
- Matplotlib
- Openpyxl
- वित्त और संचालन विश्लेषकों के लिए: यह स्टैक मॉडलिंग, KPI गणना, आवंटन और दोहराने योग्य मासिक रिपोर्टिंग के लिए अच्छा काम करता है।
- पांडा
- सीबॉर्न
- Openpyxl
- उन्नत एनालिटिक्स टीमों के लिए: यह संयोजन आपको डेटा तैयार करने से लेकर पूर्वानुमानित स्कोरिंग से लेकर कार्यपुस्तिका वितरण तक पूरी पाइपलाइन प्रदान करता है।
- पांडा
- Matplotlib
- स्किकिट-लर्न
- Openpyxl
- सीबॉर्न