<पी> एक्सेल में पायथन एक शक्तिशाली Microsoft 365 सुविधा है जो आपको एक्सेल सेल के अंदर सीधे पायथन कोड लिखने और चलाने की सुविधा देती है। यह एक्सेल में पायथन एनालिटिक्स की शक्ति लाता है। आप सीधे सेल में Python टाइप करते हैं, Python गणनाएँ Microsoft क्लाउड में चलती हैं, और आपके परिणाम वर्कशीट में वापस आ जाते हैं। आप स्प्रेडशीट को छोड़े बिना या स्थानीय रूप से कुछ भी इंस्टॉल किए बिना डेटा विश्लेषण, सफाई, सांख्यिकी और विज़ुअलाइज़ेशन के लिए एक्सेल के परिचित इंटरफ़ेस और पुनर्गणना को पायथन के समृद्ध पारिस्थितिकी तंत्र के साथ जोड़ सकते हैं। <पी> इस ट्यूटोरियल में, हम दिखाएंगे कि एक्सेल में पायथन का उपयोग कैसे करें और यह कब और कैसे उपयोगी है। Jupyter या VS Code जैसे अन्य टूल पर स्विच करने के बजाय, आप Excel में सीधे Python का उपयोग कर सकते हैं।
आवश्यकताएँ और उपलब्धता
- Microsoft 365 सदस्यता: कई भुगतान योजनाओं (उपभोक्ता परिवार/व्यक्तिगत, वाणिज्यिक, शिक्षा, उद्यम) पर उपलब्ध है। कुछ सुविधाओं या उच्च गणना के लिए ऐड-ऑन की आवश्यकता हो सकती है।
- प्लेटफ़ॉर्म: मुख्य रूप से विंडोज़ डेस्कटॉप एक्सेल पर उपलब्ध; वेब, मैक और मोबाइल के लिए समर्थन अलग-अलग है। आईपैड के लिए एक्सेल, आईफोन के लिए एक्सेल, या एंड्रॉइड के लिए एक्सेल पर उपलब्ध नहीं है।
- किसी स्थानीय पायथन की आवश्यकता नहीं: सब कुछ पहले से स्थापित लाइब्रेरीज़ के साथ क्लाउड में चलता है। Excel में Python का उपयोग करने के लिए आपको Python के स्थानीय संस्करण की आवश्यकता नहीं है। यदि आपके कंप्यूटर पर पायथन का स्थानीय संस्करण स्थापित है, तो उस इंस्टॉलेशन में आपके द्वारा किया गया कोई भी अनुकूलन एक्सेल गणना में पायथन में प्रतिबिंबित नहीं होगा।
एक्सेल में पायथन का उपयोग शुरू करना
<पी> सेल में पायथन सक्षम करें:- एक सेल चुनें
- सूत्र पर जाएं टैब>> पायथन डालें चुनें
- या =PY टाइप करें एक सेल में और टैब दबाएँ
- फॉर्मूला बार हरा हो जाता है, जो पायथन मोड को दर्शाता है
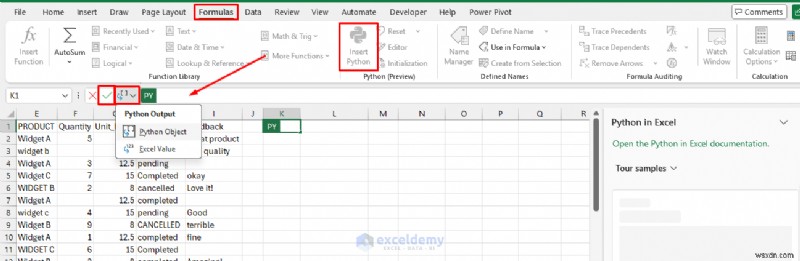 <पी> एक्सएल() फ़ंक्शन:एक्सेल और पायथन को जोड़ना <पी> Excel में Python का उपयोग करने की कुंजी xl() फ़ंक्शन है, जो आपके Python कोड को सीधे आपकी स्प्रेडशीट से डेटा पढ़ने देता है:
<पी> एक्सएल() फ़ंक्शन:एक्सेल और पायथन को जोड़ना <पी> Excel में Python का उपयोग करने की कुंजी xl() फ़ंक्शन है, जो आपके Python कोड को सीधे आपकी स्प्रेडशीट से डेटा पढ़ने देता है: - संपादन मोड में रहते हुए, सेल या रेंज (उदाहरण के लिए, A1:D100) का चयन करने के लिए क्लिक करें और खींचें
- एक्सेल xl(“A1:D100”) या इसी तरह का एक संदर्भ सम्मिलित करता है
df =xl(“A1:D100”, हेडर=True) <पी> # एकल कक्ष मान का संदर्भ लें
लक्ष्य =xl(“F1”) <पी> इस प्रकार Python आपके स्प्रेडशीट डेटा को "देखता" है। आप इसे =PY() सेल के अंदर लिखें और परिणाम के साथ एक सामान्य पायथन ऑब्जेक्ट के रूप में काम करें। <पी> आउटपुट विकल्प:
- एक्सेल वैल्यू के रूप में लौटने के लिए फॉर्मूला बार में ड्रॉपडाउन का उपयोग करें (मूल एक्सेल सेल/टेबल में कनवर्ट करता है) या पायथन ऑब्जेक्ट के रूप में रखें (अन्य पायथन कोशिकाओं में चेनिंग के लिए)
- Ctrl + Alt + Shift + M दबाएँ आउटपुट प्रकार को टॉगल करने के लिए
- कुछ मामलों में डिबगिंग या आउटपुट के लिए प्रिंट() का उपयोग करें
जब Excel में Python उपयोगी है
1. उन्नत डेटा सफ़ाई और परिवर्तन
<पी> पायथन आसानी से गड़बड़ तिथियों को ठीक कर सकता है, टेक्स्ट को मानकीकृत कर सकता है (कैपिटलाइज़ेशन, स्पेसिंग), नल और डुप्लिकेट को संभाल सकता है, विस्तृत डेटा को लंबे प्रारूप में अनपिवोट कर सकता है, और असंगत प्रारूपों या लापता मानों को प्रबंधित कर सकता है। पांडा इन कार्यों को संक्षिप्त और प्रतिलिपि प्रस्तुत करने योग्य बनाता है। <पी> पायथन:import pandas as pd
df = xl("A1:I56", headers=True)
df.columns = df.columns.str.strip().str.title()
# Fix names: Title Case
df["Customer_Name"] = df["Customer_Name"].str.strip().str.title()
# Fix region: Title Case
df["Region"] = df["Region"].str.strip().str.title()
# Standardize product: Title Case
df["Product"] = df["Product"].str.strip().str.title()
# Standardize status and feedback
df["Status"] = df["Status"].str.strip().str.capitalize()
df["Feedback"] = df["Feedback"].str.strip().str.capitalize()
# Parse all messy date formats into one
df["Order_Date"] = pd.to_datetime(df["Order_Date"], dayfirst=True, errors="coerce")
# Fill missing quantity with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df
- टिक चिह्न पर क्लिक करें या Ctrl+Enter दबाएँ कोड चलाने के लिए
- आउटपुट सेल पर कार्ड आइकन पर क्लिक करें>> arrayPreview चुनें
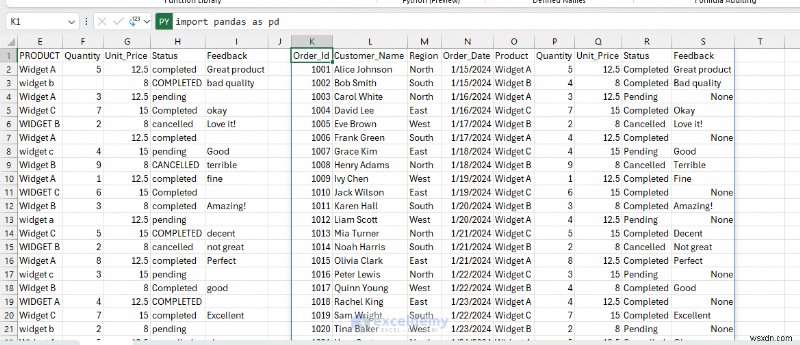
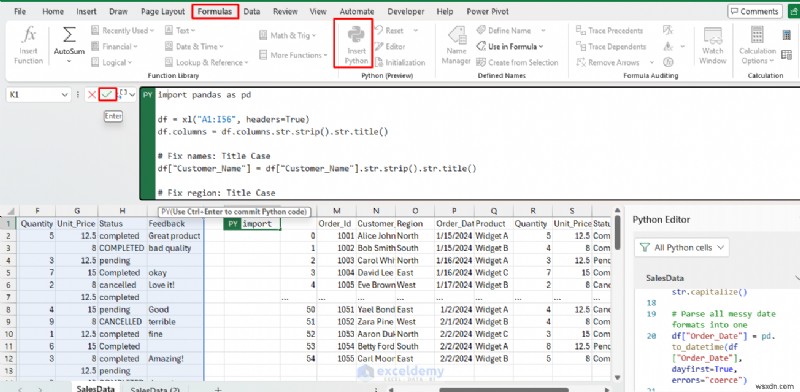 <पी> साफ़ किया गया डेटाफ़्रेम स्वचालित रूप से शीट में वापस आ जाता है। आगे के विश्लेषण और गणना के लिए स्वच्छ डेटा का उपयोग करने के लिए परिणाम को एक्सेल मान के रूप में लौटाएं।
<पी> साफ़ किया गया डेटाफ़्रेम स्वचालित रूप से शीट में वापस आ जाता है। आगे के विश्लेषण और गणना के लिए स्वच्छ डेटा का उपयोग करने के लिए परिणाम को एक्सेल मान के रूप में लौटाएं। - फ़ॉर्मूला बार से ड्रॉपडाउन का विस्तार करें>> एक्सेल वैल्यू चुनें
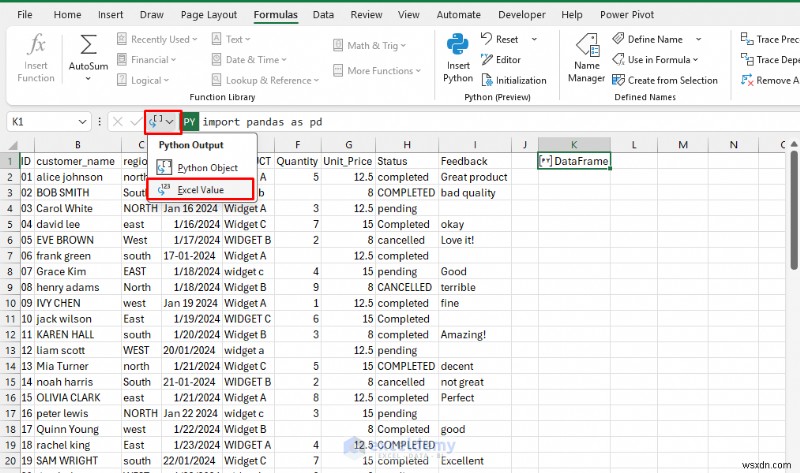
- अब अन्य उदाहरणों में नए, साफ किए गए डेटा का उपयोग करें
2. जटिल डेटा विश्लेषण और सांख्यिकी
<पी> पायथन एक्सेल के अंतर्निहित कार्यों से परे संचालन को सक्षम बनाता है, जिसमें जटिल समूह, बहु-चरण परिवर्तन और सांख्यिकीय सारांश शामिल हैं। यह समय-श्रृंखला विश्लेषण, प्रतिगमन, क्लस्टरिंग, बाहरी पहचान, पाठ पर भावना विश्लेषण और मोंटे कार्लो सिमुलेशन का भी समर्थन करता है। <पी> पायथन:import pandas as pd
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Revenue summary + outlier flag (> 2 std devs)
summary = df.groupby("Region")["Revenue"].agg(["sum", "mean", "std"])
summary["outlier_threshold"] = summary["mean"] + 2 * summary["std"]
summary.round(2)
<पी> परिणाम एक तालिका के रूप में सीधे आपकी शीट में वापस आ जाता है। आप df.describe() का भी उपयोग कर सकते हैं संपूर्ण डेटाफ़्रेम के लिए सारांश आँकड़े दिखाने के लिए। <पी> पायथन: import pandas as pd
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
df.describe()
<पी> 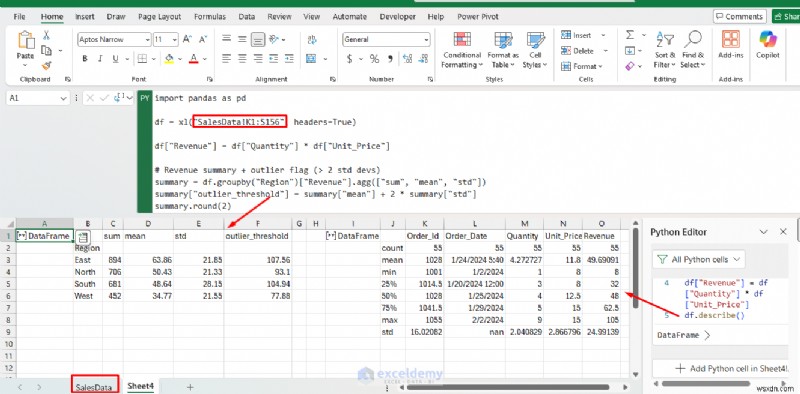
3. बेहतर चार्ट और विज़ुअलाइज़ेशन
<पी> मैटप्लोटलिब, सीबॉर्न, या प्लॉटनाइन के साथ घनत्व प्लॉट, झुंड प्लॉट, शब्द बादल, या छोटे गुणकों जैसे पेशेवर प्लॉट बनाना आसान है। ये एक्सेल चार्ट की तुलना में कहीं अधिक लचीले हैं। मैटप्लोटलिब और सीबॉर्न के साथ एक्सेल के मूल चार्ट से आगे बढ़ें: <पी> पायथन:import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
fig, ax = plt.subplots(figsize=(8, 4))
sns.boxplot(data=df, x="Region", y="Revenue", palette="Set2", ax=ax)
ax.set_title("Revenue Distribution by Region")
ax.set_xlabel("Region")
ax.set_ylabel("Revenue ($)")
fig
<पी> 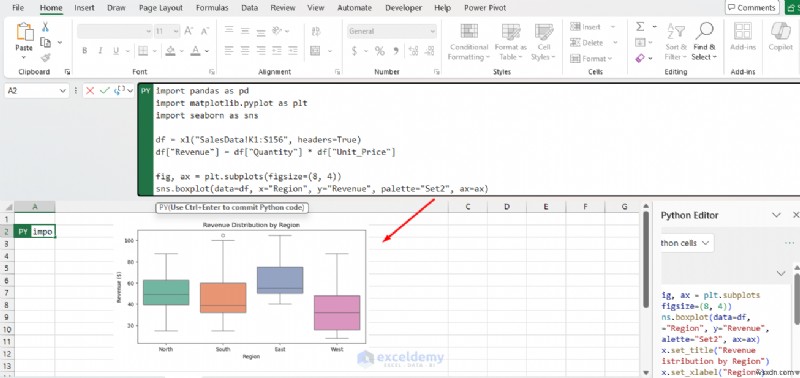 <पी> चार्ट सीधे वर्कशीट में एक छवि ऑब्जेक्ट के रूप में प्रस्तुत होता है, जो किसी भी एक्सेल चार्ट की तरह आकार बदलने योग्य और पुन:स्थापित करने योग्य होता है।
<पी> चार्ट सीधे वर्कशीट में एक छवि ऑब्जेक्ट के रूप में प्रस्तुत होता है, जो किसी भी एक्सेल चार्ट की तरह आकार बदलने योग्य और पुन:स्थापित करने योग्य होता है। 4. आपके स्प्रैडशीट डेटा पर मशीन लर्निंग
<पी> पायथन पूर्वानुमानित मॉडलिंग और पूर्वानुमान को सक्षम बनाता है। आप सीधे अपने एक्सेल डेटा पर स्टेट्समॉडल या स्किकिट-लर्न का उपयोग करके अधिक सटीक पूर्वानुमान या सरल मशीन लर्निंग मॉडल बना सकते हैं। <पी> एक्सेल को छोड़े बिना पूर्वानुमानित मॉडल चलाएँ: <पी> पायथन:import pandas as pd
from sklearn.linear_model import LinearRegression
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
# Convert to numeric and fill missing values with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Unit_Price"] = pd.to_numeric(df["Unit_Price"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df["Unit_Price"] = df["Unit_Price"].fillna(df["Unit_Price"].median())
# Calculate Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# One-hot encode Product
X = pd.get_dummies(df[["Product", "Unit_Price"]], drop_first=True)
y = df["Revenue"]
# Fit the Linear Regression model
model = LinearRegression().fit(X, y)
# Add predictions
df["Predicted_Revenue"] = model.predict(X).round(2)
# Create final result with useful columns
result = df[["Order_Id", "Product", "Revenue", "Predicted_Revenue"]].copy()
result["Difference"] = (result["Revenue"] - result["Predicted_Revenue"]).round(2)
# Optional: Show model performance
print("Model R² Score:", round(model.score(X, y), 4))
result
<पी> 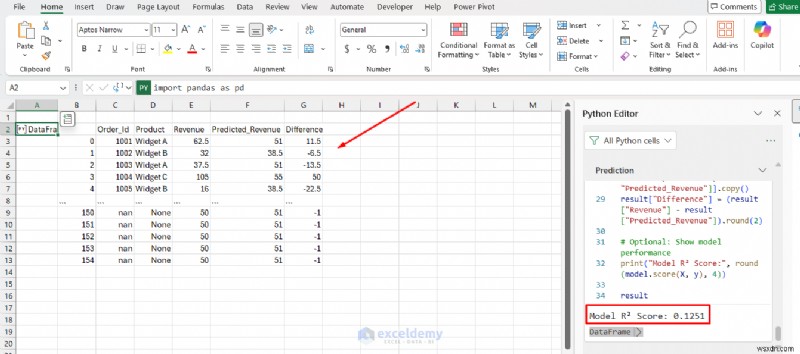 <पी> व्यवसाय विश्लेषक किसी अलग वातावरण में स्विच किए बिना अपने मौजूदा डेटा पर मशीन लर्निंग मॉडल लागू कर सकते हैं।
<पी> व्यवसाय विश्लेषक किसी अलग वातावरण में स्विच किए बिना अपने मौजूदा डेटा पर मशीन लर्निंग मॉडल लागू कर सकते हैं। 5. रोलिंग गणना और समय श्रृंखला
<पी> केवल एक्सेल फ़ार्मुलों का उपयोग करके चलती औसत, संचयी योग या अंतराल सुविधाओं की गणना करना मुश्किल है। Python इन कार्यों को सरल बनाता है। <पी> पायथन:import pandas as pd
# Load your full sales data
df = xl("SalesData!K1:S156", headers=True)
# Calculate Daily Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Rolling Calculations (Time Series)
# Sort by date first (important for time series)
df = df.sort_values("Order_Date").reset_index(drop=True)
# 7-day Rolling Metrics on Revenue (weekly trend)
df["Revenue_7d_Mean"] = df["Revenue"].rolling(window=7, min_periods=1).mean().round(2)
df["Revenue_7d_Sum"] = df["Revenue"].rolling(window=7, min_periods=1).sum().round(2)
df["Revenue_7d_Max"] = df["Revenue"].rolling(window=7, min_periods=1).max().round(2)
df["Revenue_7d_Std"] = df["Revenue"].rolling(window=7, min_periods=1).std().round(2)
# 30-day Rolling Mean (monthly trend)
df["Revenue_30d_Mean"] = df["Revenue"].rolling(window=30, min_periods=1).mean().round(2)
# Cumulative Revenue (running total)
df["Cumulative_Revenue"] = df["Revenue"].cumsum().round(2)
# Select columns to display
result = df[["Order_Id", "Order_Date", "Product", "Revenue",
"Revenue_7d_Mean", "Revenue_7d_Sum", "Revenue_30d_Mean",
"Cumulative_Revenue"]]
result
<पी> यह दृष्टिकोण बिक्री रुझानों का विश्लेषण करने, दैनिक या साप्ताहिक उतार-चढ़ाव को सुचारू करने, विसंगतियों का पता लगाने और गति का पूर्वानुमान लगाने के लिए उपयोगी है। <पी> 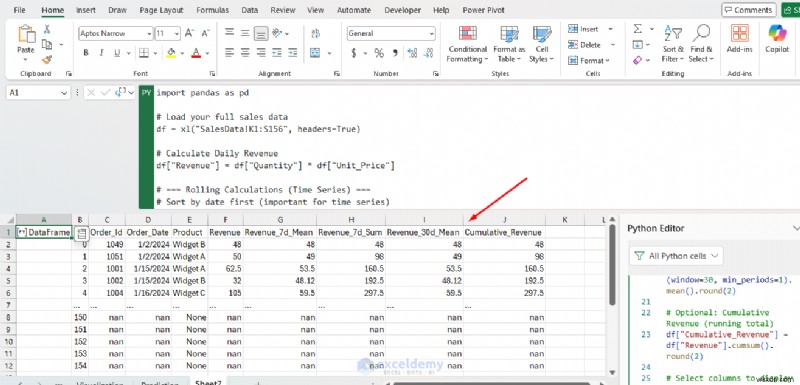
- राजस्व_7d_मीन: 7-दिवसीय चलती औसत (साप्ताहिक बिक्री रुझान को सुचारू करती है)
- राजस्व_7डी_योग: पिछले 7 दिनों में कुल राजस्व
- राजस्व_30d_मीन: 30-दिवसीय चलती औसत (दीर्घकालिक प्रवृत्ति)
- संचयी_राजस्व: उस तिथि तक के सभी राजस्व का कुल योग
टिप्स और सर्वोत्तम अभ्यास
- श्रृंखला कोशिकाएँ: एक भी सेल को अव्यवस्थित किए बिना मल्टी-स्टेप वर्कफ़्लो बनाने के लिए पिछले पायथन ऑब्जेक्ट्स (वे वेरिएबल्स के रूप में दिखाई देते हैं) का संदर्भ लें
- प्रदर्शन: भारी गणनाओं के लिए, क्लाउड कोटा का ध्यान रखें। यदि आवश्यक हो तो बड़े कार्यों को चरणों में तोड़ें या प्रीमियम गणना का उपयोग करें
- सुरक्षा: कोड पृथक क्लाउड कंटेनरों में चलता है। संवेदनशील कार्यों से बचें; Microsoft गोपनीयता प्रबंधित करता है
- डिबगिंग: चरण दर चरण प्रिंट() या आउटपुट डेटाफ़्रेम का उपयोग करें। सेल में त्रुटियाँ दिखाई देती हैं
- एक्सेल के साथ संयोजित करें: भारी सामान उठाने के लिए पायथन और फ़ॉर्मेटिंग, पिवोट्स या डैशबोर्ड के लिए एक्सेल का उपयोग करें
- सीखने की अवस्था: यदि आप पायथन में नए हैं, तो पहले पांडा पर ध्यान केंद्रित करें। कई निःशुल्क ट्यूटोरियल और नमूना फ़ाइलें उपलब्ध हैं
- साझा करना: संगत Microsoft 365 वाले प्राप्तकर्ता परिणाम देख या ताज़ा कर सकते हैं; अन्यथा, परिणाम स्थिर मानों में परिवर्तित हो जाते हैं
जानने की सीमाएं
- केवल क्लाउड निष्पादन; इंटरनेट कनेक्शन आवश्यक है
- मानक योजनाओं पर कोटा की गणना करें
- पायथन वातावरण एनाकोंडा-प्रबंधित है; आप अपने स्वयं के पैकेज स्थापित नहीं कर सकते या स्थानीय अनुकूलन का उपयोग नहीं कर सकते
- डेस्कटॉप की तुलना में मोबाइल और वेब समर्थन सीमित है
- बहुत बड़े डेटासेट या लंबे समय तक चलने वाले कोड का टाइमआउट हो सकता है