पायथन पांडा में टेम्पलेट का उपयोग करके डेटाफ़्रेम में नई पंक्तियों को कैसे जोड़ें।
परिचय
डेटा इंजीनियरिंग विशेषज्ञ होने के नाते, मैं अक्सर पंक्तियों की तुलना में अधिक व्युत्पन्न कॉलम बनाता हूं क्योंकि विश्लेषण के लिए मुझे डेटा बनाने और भेजने की भूमिका अन्य डेटाबेस विशेषज्ञों का ध्यान रखना चाहिए। हालांकि, यह हर समय सच नहीं होता है।
हमें डेटा विशेषज्ञ टीम द्वारा हमें डेटा भेजने की प्रतीक्षा करने के बजाय नमूना पंक्तियाँ बनानी होंगी। इस विषय में मैं पंक्तियाँ बनाने के लिए साफ-सुथरी तरकीबें दिखाऊंगा।
इसे कैसे करें..
इस रेसिपी में, हम .loc विशेषता के साथ एक छोटे डेटासेट में पंक्तियों को जोड़कर शुरू करेंगे और फिर .append विधि का उपयोग करेंगे।
1.आइए हम बाद में पंक्तियों को जोड़ने के लिए डेटाफ़्रेम बनाकर शुरू करते हैं।
उदाहरण
import pandas as pd
import numpy as np
players_info = pd.DataFrame(data=[
{"players": "Roger Federer", "titles": 20},
{"players": "Rafael Nadal", "titles": 20},
{"players": "Novak Djokovic", "titles": 17},
{"players": "Andy Murray", "titles": 3}], columns=["players", "titles"]) आउटपुट
print(players_info.info())
उदाहरण
<class 'pandas.core.frame.DataFrame'> RangeIndex: 4 entries, 0 to 3 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 players 4 non-null object 1 titles 4 non-null int64 dtypes: int64(1), object(1) memory usage: 192.0+ bytes None
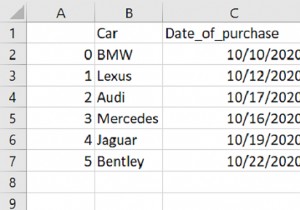
1. अब आइए .loc विशेषता का उपयोग करके डेटाफ़्रेम में नया खिलाड़ी "Dominic Theim" जोड़ें।
new_Player = ['Dominic Theim', 1] players_info.loc[4] = new_Player
आउटपुट
print(players_info)
players titles 0 Roger Federer 20 1 Rafael Nadal 20 2 Novak Djokovic 17 3 Andy Murray 3 4 Dominic Theim 1
1. उसी .loc विशेषता का उपयोग करके, हम डेटाफ़्रेम के अंत में नई पंक्ति जोड़ते हैं। यहां मैं दिखाऊंगा कि डेटाफ़्रेम में शब्दकोश कैसे जोड़ा जाता है।
new_player = {'players': 'Daniel Medvedev', 'titles': 0}
players_info.loc[len(players_info)] = new_player आउटपुट
print(players_info)
players titles 0 Roger Federer 20 1 Rafael Nadal 20 2 Novak Djokovic 17 3 Andy Murray 3 4 Dominic Theim 1 5 Daniel Medvedev 0
1. हम डेटाफ़्रेम में पांडा सीरीज़ होल्डिंग डेटा भी जोड़ सकते हैं।
players_info.loc[len(players_info)] = pd.Series({'players': 'Andy Zverev', 'titles': 0}) आउटपुट
print(players_info)
players titles 0 Roger Federer 20 1 Rafael Nadal 20 2 Novak Djokovic 17 3 Andy Murray 3 4 Dominic Theim 1 5 Daniel Medvedev 0 6 Andy Zverev 0
निष्कर्ष
हमने .loc पद्धति का उपयोग करके उपरोक्त 4 चरणों में डेटा जोड़ा है। .loc विशेषता डेटाफ़्रेम में यथास्थान परिवर्तन करती है।
अगले कुछ चरणों में, हम .append पद्धति को देखेंगे, जो कॉलिंग डेटाफ़्रेम को संशोधित नहीं करती है, बल्कि यह संलग्न पंक्तियों के साथ डेटाफ़्रेम की एक नई प्रति लौटाती है।
.append का पहला तर्क या तो कोई अन्य DataFrame, Series, Dictionary या एक सूची होना चाहिए।
उदाहरण
# Create a DataFrame with index
players_info = pd.DataFrame(data=[
{"players": "Roger Federer", "titles": 20},
{"players": "Rafael Nadal", "titles": 20},
{"players": "Novak Djokovic", "titles": 17},
{"players": "Andy Murray", "titles": 3}], columns=["players", "titles"],
index=["roger", "nadal", "djokovic", "murray"])
# Add a new row(dictionary) to DataFrame using .append method.
players_info.append({'players': 'Daniel Medvedev', 'titles': 0}) का उपयोग करके DataFrame में एक नई पंक्ति (शब्दकोश) जोड़ें।
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
1 # Add a new row(dictionary) to DataFrame using .append method.
----> 2 players_info.append({'players': 'Daniel Medvedev', 'titles': 0})
~\anaconda3\lib\site-packages\pandas\core\frame.py in append(self, other, ignore_index, verify_integrity, sort)
7046 other = Series(other)
7047 if other.name is None and not ignore_index:
-> 7048 raise TypeError(
7049 "Can only append a Series if ignore_index=True "
7050 "or if the Series has a name" TypeError केवल एक सीरीज को जोड़ सकता है अगर इग्नोर_इंडेक्स=ट्रू या सीरीज का कोई नाम हो
जब मैंने एक शब्दकोश जोड़ने की कोशिश की, तो उसने एक अपवाद उठाया जो हमें पैरामीटर का उपयोग करने के लिए कह रहा है Ignore_index=True. तो मुझे यह सुझाया गया पैरामीटर जोड़ने दें और देखें कि यह क्या करता है।
new_df = players_info.append({'players': 'Daniel Medvedev', 'titles': 0}, ignore_index=True) आउटपुट
print(f" *** Original with index \n {players_info} \n\n\n *** Modified index \n {new_df}")
*** Original with index players titles roger Roger Federer 20 nadal Rafael Nadal 20 djokovic Novak Djokovic 17 murray Andy Murray 3 *** Modified index players titles 0 Roger Federer 20 1 Rafael Nadal 20 2 Novak Djokovic 17 3 Andy Murray 3 4 Daniel Medvedev 0
मैंने इग्नोर_इंडेक्स =ट्रू पैरामीटर का उपयोग करने के बाद आउटपुट से क्या देखा? हां, जब इग्नोर_इंडेक्स को ट्रू पर सेट किया जाता है, तो पुराने इंडेक्स को पूरी तरह से हटा दिया जाएगा और इसे 0 से n-1 तक रेंजइंडेक्स से बदल दिया जाएगा।
जब आप डेटाफ़्रेम में एक ही बार में कई पंक्तियाँ जोड़ना चाहते हैं तो .append विधि काफी उपयोगी होती है।
player1 = pd.Series({'players': 'Andy Zverev', 'titles': 0}, name='zverev')
player2 = pd.Series({'players': 'Dominic Theim', 'titles': 1}, name='theim')
new_df_1 = players_info.append([player1, player2]) आउटपुट
print(new_df_1)
players titles roger Roger Federer 20 nadal Rafael Nadal 20 djokovic Novak Djokovic 17 murray Andy Murray 3 zverev Andy Zverev 0 theim Dominic Theim 1
ठीक है, अब जब आपने पंक्तियों को जोड़ने के बारे में मूलभूत बातें देख ली हैं, तो हम कई स्तंभों वाले डेटाफ़्रेम पर पंक्तियों को जोड़ने के तरीके के बारे में जानेंगे।
df = pd.read_csv("https://raw.githubusercontent.com/sasankac/TestDataSet/master/movies_data.csv") आउटपुट
print(df.info())
उदाहरण
<class 'pandas.core.frame.DataFrame'> RangeIndex: 4803 entries, 0 to 4802 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 budget 4803 non-null int64 1 id 4803 non-null int64 2 original_language 4803 non-null object 3 original_title 4803 non-null object 4 popularity 4803 non-null float64 5 release_date 4802 non-null object 6 revenue 4803 non-null int64 7 runtime 4801 non-null float64 8 status 4803 non-null object 9 title 4803 non-null object 10 vote_average 4803 non-null float64 11 vote_count 4803 non-null int64 dtypes: float64(3), int64(4), object(5) memory usage: 450.4+ KB None
Google के इस डेटासेट में 12 कॉलम हैं और यदि आप मैन्युअल रूप से डेटा की नई पंक्तियों में प्रवेश कर रहे थे तो कॉलम नाम को गलत टाइप करना या एक को पूरी तरह से भूल जाना बहुत आसान है। तो हम इस समस्या से कैसे बच सकते हैं? वैसे एक तरीका है, बस कॉलम नामों का एक टेम्प्लेट बनाएं।
columns_dictionary = df.iloc[0].to_dict()
##### Output:
print(columns_dictionary)
{'budget': 237000000, 'id': 19995, 'original_language': 'en', 'original_title': 'Avatar', 'popularity': 150.437577, 'release_date': '10/12/2009', 'revenue': 2787965087, 'runtime': 162.0, 'status': 'Released', 'title': 'Avatar', 'vote_average': 7.2, 'vote_count': 11800} तो, अब आप समझ सकते हैं कि हमने पहली पंक्ति ले ली है और इसे एक शब्दकोश में बदल दिया है। ठीक है, हमें कॉलम और मान भी मिल गए हैं, आइए अब पुराने मानों को एक डिक्शनरी समझ के साथ साफ़ करें जो किसी भी पिछले स्ट्रिंग मान को खाली स्ट्रिंग के रूप में निर्दिष्ट करता है। और अन्य सभी अनुपलब्ध मान के रूप में।
यह शब्दकोश अब किसी भी नए डेटा के लिए एक टेम्पलेट के रूप में काम कर सकता है जिसे आप दर्ज करना चाहते हैं।
उदाहरण
import datetime
new_data_dict = {}
for a, b in columns_dictionary.items():
if isinstance(b, str):
new_data_dict[a] = np.random.choice(list('abcde'))
elif isinstance(b, datetime.date):
new_data_dict[a] = np.nan
else:
new_data_dict[a] = np.nan आउटपुट
print(new_data_dict)
{'budget': nan, 'id': nan, 'original_language': 'e', 'original_title': 'a', 'popularity': nan, 'release_date': 'b', 'revenue': nan, 'runtime': nan, 'status': 'e', 'title': 'c', 'vote_average': nan, 'vote_count': nan}