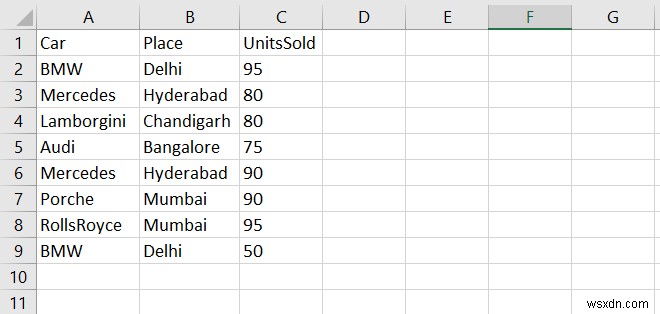
मल्टीइंडेक्स डेटा फ़्रेम एक डेटा फ़्रेम है जिसमें एक से अधिक इंडेक्स होते हैं। मान लें कि डेस्कटॉप पर संग्रहीत हमारा सीएसवी निम्नलिखित है -
सबसे पहले, पांडा पुस्तकालय को आयात करें और उपरोक्त सीएसवी फ़ाइल को पढ़ें -
pddf के रूप में पांडा आयात करें =pd.read_csv("C:/Users/amit_/Desktop/sales.csv") प्रिंट (df) हम इंडेक्स के रूप में डेटाफ्रेम के 'कार' और 'प्लेस' कॉलम बनाएंगे -
df =df.set_index(['Car', 'Place'])
डेटाफ़्रेम अब एक बहु-अनुक्रमित डेटाफ़्रेम है जिसमें अनुक्रमणिका के रूप में 'कार' और 'प्लेस' कॉलम होते हैं।
अब, मल्टीइंडेक्स डेटाफ़्रेम पर ग्रुपबाय का उपयोग करें:
res =df.groupby(level=['Car'])['UnitsSold'].mean() प्रिंट(res)
उदाहरण
निम्नलिखित कोड है -
pddf के रूप में पांडा आयात करें =pd.read_csv("C:/Users/amit_/Desktop/sales.csv")print(df)# डेटाफ़्रेम के कार और प्लेस कॉलम को indexdf =df.set_index(['Car) के रूप में सेट करें ', 'प्लेस'])# सॉर्टिंगडीएफ.सॉर्ट_इंडेक्स ()# ग्रुपबाय ऑन मल्टीइंडेक्स डेटाफ्रेम्स =डीएफ.ग्रुपबाय(लेवल=['कार'])['यूनिट्ससोल्ड'].मीन()प्रिंट(रेस) आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
कार प्लेस बिक0 बीएमडब्ल्यू दिल्ली 951 मर्सिडीज हैदराबाद 802 लेम्बोर्गिनी चंडीगढ़ 803 ऑडी बैंगलोर 754 मर्सिडीज हैदराबाद 905 पोर्श मुंबई 906 रोल्स रॉयस मुंबई 957 बीएमडब्ल्यू दिल्ली 50कारऑडी 75.8बीएमडब्ल्यू 72.5 लेम्बोर्गिनी 80.0 मर्सिडीज 85.0पोर्श 90.0 रोल्सरॉयस 95.0नाम:यूनिट्स बिकी, डीटाइप:फ्लोट64 पूर्व>