
रेगुलर एक्सप्रेशन (रेगेक्स) पहली बार में जटिल लग सकते हैं, लेकिन वे पैटर्न मिलान और टेक्स्ट हेरफेर के लिए शक्तिशाली उपकरण हैं। एक्सेल में, वे आपको जटिल पैटर्न के आधार पर डेटा खोजने, निकालने और बदलने की अनुमति देते हैं, जिससे डेटा सफाई, सत्यापन और पार्सिंग जैसे कार्य अधिक कुशल हो जाते हैं। एक बार जब आप बुनियादी बातें सीख लेते हैं तो वे सफाई, सत्यापन और जानकारी निकालने में लगने वाले घंटों की बचत कर सकते हैं। रेगेक्स का समर्थन करने के लिए, एक्सेल REGEXTEST, REGEXEXTRACT, और REGEXREPLACE जैसे फ़ंक्शन प्रदान करता है। <पी> एक्सेल पावर उपयोगकर्ताओं के लिए यह हमारा रेगेक्स क्रैश कोर्स है।
रेगेक्स क्या है?
<पी> रेगेक्स (नियमित अभिव्यक्ति) पाठ के लिए एक पैटर्न भाषा है। किसी सटीक शब्द को खोजने या मिलान करने के बजाय, रेगेक्स आपको टेक्स्ट के आकार का वर्णन करने देता है। एक्सेल में, रेगेक्स एक सुपर-पावर्ड FIND + MID + SUBSTITUTE संयुक्त की तरह है, जहां एक पैटर्न टेक्स्ट को सत्यापित, निकाल या साफ़ कर सकता है। <पी> आप रेगेक्स का उपयोग करके एक्सेल में सामान्य संरचनाओं का मिलान कर सकते हैं:ईमेल पते, फोन नंबर, कई प्रारूपों में तिथियां, या कोई भी आईडी जो नियम का पालन करती है। <पी> आधुनिक एक्सेल में, आप इसका उपयोग मुख्य रूप से इसके साथ करते हैं:- REGEXTEST (जांचें कि क्या कोई पैटर्न मौजूद है)
- REGEXEXTRACT (मिलान वाला भाग खींचें)
- REGEXREPLACE (मैचों को बदलें/साफ करें)
रेगेक्स मूल बातें:बिल्डिंग पैटर्न
<पी> रेगेक्स पैटर्न वे स्ट्रिंग हैं जो परिभाषित करते हैं कि आप क्या खोज रहे हैं। वे शाब्दिक वर्णों (उदाहरण के लिए, "एबीसी") को विशेष मेटाचैक्टर के साथ जोड़ते हैं। आप इस तालिका का उपयोग त्वरित संदर्भ के रूप में कर सकते हैं। <पी> मुख्य मेटाअक्षर और सिंटेक्स:- क्वांटिफ़ायर (*, +, ?, {}) उनसे पहले वाले तत्व पर लागू होते हैं।
- झंडे: एक्सेल के रेगेक्स फ़ंक्शन पैटर्न में (?i) जैसे इनलाइन फ़्लैग का समर्थन नहीं करते हैं; केस सेंसिटिविटी के लिए फ़ंक्शन तर्क का उपयोग करें (उदाहरण के लिए, REGEXTEST का तीसरा तर्क), या चरित्र वर्गों का उपयोग करें (उदाहरण के लिए, [Aa])।
- लालची बनाम आलसी: डिफ़ॉल्ट रूप से, क्वांटिफायर लालची होते हैं (जितना संभव हो उतना मिलान करें)। जोड़ना ? इसे आलसी बनाने के लिए एक क्वांटिफायर के बाद (उदाहरण के लिए, .*?).
एक्सेल के रेगेक्स फ़ंक्शंस
<पी> एक्सेल मूल रूप से तीन रेगेक्स फ़ंक्शन प्रदान करता है। ये फ़ंक्शन टेक्स्ट स्ट्रिंग और रेगुलर एक्सप्रेशन पैटर्न को इनपुट के रूप में लेते हैं और पैटर्न के आधार पर टेक्स्ट को मान्य या परिवर्तित करते हैं। आइए पाठ्यक्रम में उतरने से पहले प्रत्येक फ़ंक्शन को जान लें। <पी> वाक्यविन्यास:=REGEXTEST(text, pattern, [case_sensitivity])<पी> यह फ़ंक्शन जाँचता है कि पैटर्न दिए गए टेक्स्ट के किसी भाग से मेल खाता है या नहीं। यदि पैटर्न पाठ में कहीं भी मेल खाता है तो सत्य लौटाता है; अन्यथा गलत।
- पाठ: वह टेक्स्ट या सेल संदर्भ जिसका आप परीक्षण करना चाहते हैं।
- पैटर्न: रेगुलर एक्सप्रेशन (रेगेक्स) पैटर्न जो उस टेक्स्ट का वर्णन करता है जिसका आप मिलान करना चाहते हैं।
- [case_sensitivity]: निर्धारित करता है कि मिलान केस-संवेदी है या नहीं. डिफ़ॉल्ट रूप से, मिलान केस-संवेदी होता है।
- 0: केस संवेदनशील
- 1: मामला असंवेदनशील
=REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])<पी> यह फ़ंक्शन मेल खाने वाले टेक्स्ट को निकालता है।
- [return_mode]: एक संख्या जो निर्दिष्ट करती है कि आप कौन सी स्ट्रिंग निकालना चाहते हैं। डिफ़ॉल्ट रूप से, रिटर्न मोड 0.
- है
- 0: पैटर्न से मेल खाने वाली पहली स्ट्रिंग लौटाएं
- 1: पैटर्न से मेल खाने वाली सभी स्ट्रिंग्स को एक सरणी के रूप में लौटाएँ
- 2: पहले मैच से कैप्चरिंग समूहों को एक सरणी के रूप में लौटाएँ
=REGEXEXTRACT(A1, "\d{3}-\d{3}-\d{4}")
<पी> "123-456-7890" जैसा फ़ोन नंबर निकालता है। <पी> वाक्यविन्यास: =REGEXREPLACE(text, pattern, replacement, [occurrence], [case_sensitivity])<पी> यह फ़ंक्शन मिलानों को नए टेक्स्ट से बदल देता है।
- प्रतिस्थापन: वह पाठ जिसे आप पैटर्न के स्थान पर उपयोग करना चाहते हैं. आप कैप्चर समूहों को $1, $2, आदि के साथ संदर्भित कर सकते हैं
- घटना: निर्दिष्ट करता है कि आप पैटर्न का कौन सा उदाहरण बदलना चाहते हैं। डिफ़ॉल्ट रूप से, घटना 0 है, जो सभी उदाहरणों को प्रतिस्थापित करती है। अंत से खोजते हुए, एक ऋणात्मक संख्या उस उदाहरण को प्रतिस्थापित कर देती है।
=REGEXREPLACE(A1, "\d{3}", "***")
<पी> प्रत्येक तीन-अंकीय अनुक्रम को मास्क करता है। <पी> यदि एरे लौटाते हैं (उदाहरण के लिए, एकाधिक निष्कर्षण) तो ये फ़ंक्शन फैल जाते हैं। एक्सेल पावर उपयोगकर्ताओं के लिए व्यावहारिक उदाहरण
<पी> मान लीजिए आपके पास गड़बड़ डेटा है। आइए सामान्य परिदृश्यों पर रेगेक्स लागू करें।उदाहरण 1:ईमेल पते को मान्य करना
<पी> आप वैध कंपनी ईमेल को चिह्नित करने के लिए REGEXTEST का उपयोग कर सकते हैं (केस-असंवेदनशील मिलान अक्सर सुरक्षित होते हैं)। <पी> ईमेल को सत्यापित करने के लिए निम्नलिखित पैटर्न का उपयोग करें।- पैटर्न: ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
=REGEXTEST(A2, "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$")
<पी> अमान्य ईमेल को हाइलाइट करने के लिए सशर्त स्वरूपण का उपयोग करें: - घर पर जाएं टैब>> सशर्त फ़ॉर्मेटिंग चुनें>> नया नियम चुनें
- चुनें किस सेल को फ़ॉर्मेट करना है यह निर्धारित करने के लिए एक सूत्र का उपयोग करें
- निम्न सूत्र सम्मिलित करें
- प्रारूप चुनें>> एक भरण रंग चुनें>> ठीक पर क्लिक करें
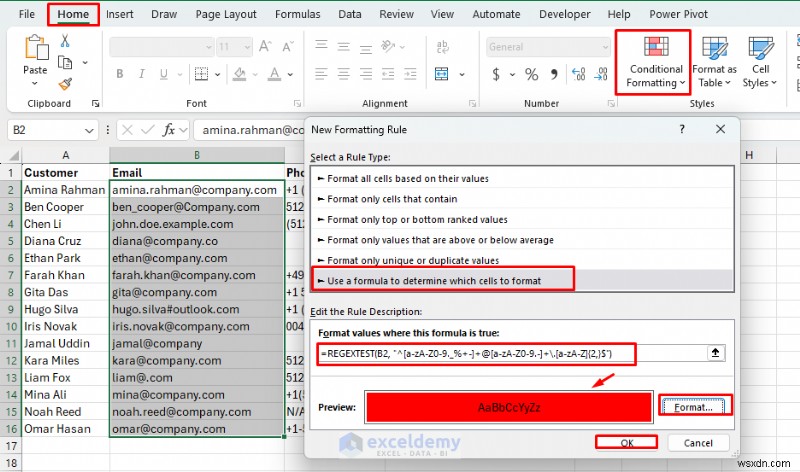
- अमान्य ईमेल पते लाल रंग में हाइलाइट किए गए हैं
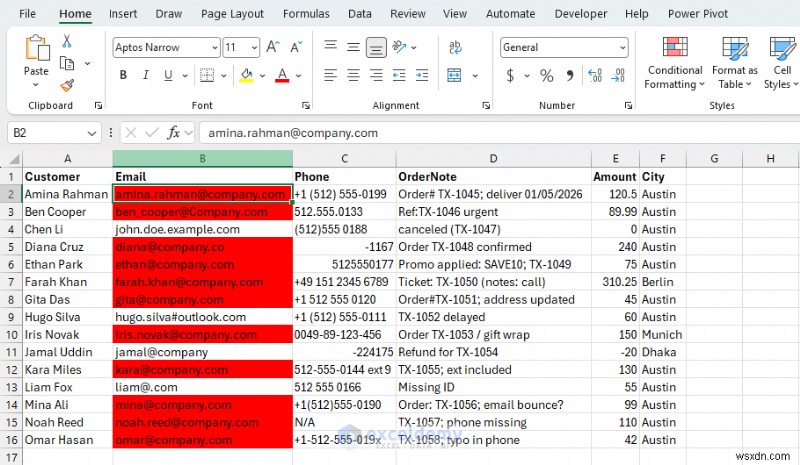 <पी> आप वैध कंपनी ईमेल को फ़्लैग करने के लिए REGEXTEST का भी उपयोग कर सकते हैं।
<पी> आप वैध कंपनी ईमेल को फ़्लैग करने के लिए REGEXTEST का भी उपयोग कर सकते हैं। =REGEXTEST(B2,"@company\.com$",1)
- तीसरा तर्क (1 ) मैच को केस-असंवेदनशील बनाता है, इसलिए Company.com अभी भी गुजरता है
- \. बिंदु से बच जाता है. एक सादा. का अर्थ है "कोई भी वर्ण"
उदाहरण 2:गंदे नोट्स से डेटा निकालना
<पी> मान लीजिए कि आपके पास नोट्स में ऑर्डर आईडी या फ़ोन नंबर जैसा मिश्रित डेटा है। आप REGEXEXTRACT फ़ंक्शन का उपयोग करके फ़ोन नंबर या ऑर्डर आईडी निकाल सकते हैं। <पी> ऑर्डर आईडी निकालें:=REGEXEXTRACT(D2,"TX-\d{4}")
- यदि कुछ पंक्तियों में यह नहीं है, तो IFERROR के साथ लपेटें:
=IFERROR(REGEXEXTRACT(D2,"TX-\d{4}"),"")
<पी> 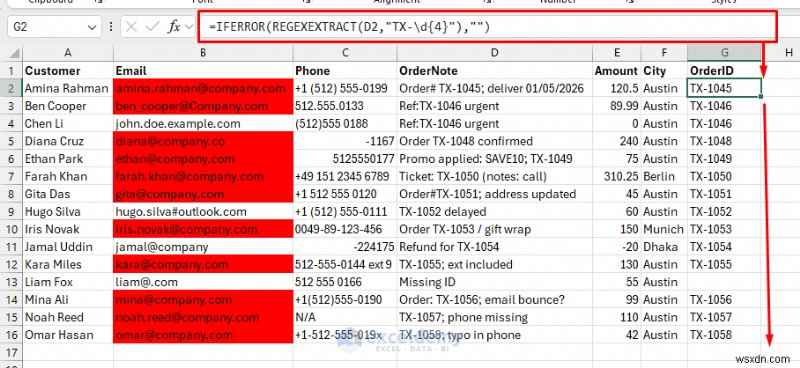 <पी> फ़ोन नंबर निकालें:
<पी> फ़ोन नंबर निकालें: - डेटा: "मुझे 123-456-7890 या (987) 654-3210 पर कॉल करें।"
- पैटर्न: (\d{3}[-. )]+){2}\d{4}
=REGEXEXTRACT(A2, "(\d{3}[-. )]+){2}\d{4}", 0, 1)
<पी> यह फ़ॉर्मूला टेक्स्ट से फ़ोन नंबर निकालता है. उदाहरण 3:गैर-अंकों को हटाकर फ़ोन नंबरों को मानकीकृत करना
- पहले केवल अंकों वाला संस्करण बनाएं।
=REGEXREPLACE(C2,"[^\d]","")
- अब आप प्रारूपित कर सकते हैं (उदाहरण:उपलब्ध होने पर अंतिम 10 अंक यूएस नंबर के रूप में):
=LET(x,REGEXREPLACE(C2,"[^\d]",""),
d,RIGHT(x,10),
IF(LEN(d)=10,"("&LEFT(d,3)&") "&MID(d,4,3)&"-"&RIGHT(d,4),""))
<पी> यह दृष्टिकोण सभी गैर-अंकीय वर्णों को हटा देता है और परिणामी फ़ोन नंबर को प्रारूपित करता है। 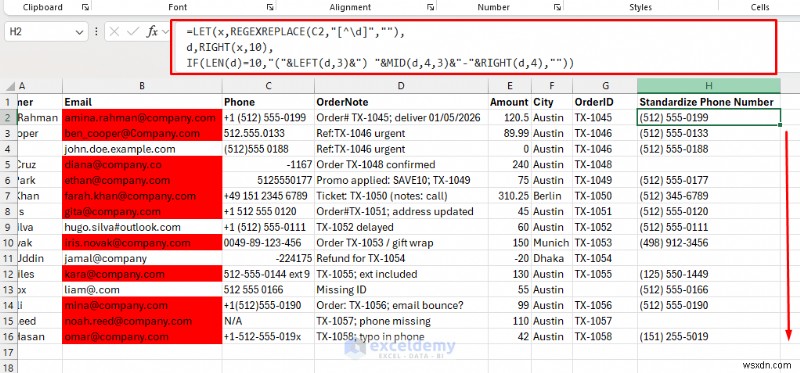
उदाहरण 4:तिथियों को पार्स करना और पुन:स्वरूपित करना
<पी> आप दिनांक को पार्स कर सकते हैं और रेगेक्स का उपयोग करके इसे पुन:स्वरूपित कर सकते हैं।- पैटर्न: (\d{1,2})/(\d{1,2})/(\d{4})
=REGEXREPLACE(A2, "(\d{1,2})/(\d{1,2})/(\d{4})", "$3-$2-$1")
<पी> यह सूत्र दिनांक को पार्स करता है और फिर इसे एक वैध आईएसओ-जैसे प्रारूप में पुन:स्वरूपित करता है। आप प्रतिस्थापन में भागों को संदर्भित करने के लिए कैप्चर ग्रुप () का भी उपयोग कर सकते हैं। उदाहरण 5:गंदे डेटा को साफ़ करना (उदाहरण के लिए, अतिरिक्त रिक्त स्थान हटाना)
<पी> आप गंदे डेटा को साफ करने के लिए रेगेक्स का उपयोग कर सकते हैं, जैसे अतिरिक्त स्थान हटाना और फ़ॉर्मेटिंग को सामान्य करना। <पी> अतिरिक्त रिक्त स्थान हटाने के लिए, निम्न पैटर्न का उपयोग करें।- पैटर्न: \s+
=REGEXREPLACE(A2, "\s+", " ")<पी> यह सूत्र रिक्त स्थान के रन को एकल स्थान से प्रतिस्थापित करता है।
उदाहरण 6:कोष्ठक में से कुछ भी हटाना (कोष्ठक सहित)
- एक सेल चुनें और निम्नलिखित सूत्र डालें:
=REGEXREPLACE(D2,"\s*\(.*?\)","")
- .*? एकगैर लालचीहै मिलान. यह अंतिम के बजाय पहले समापन कोष्ठक पर रुकता है।
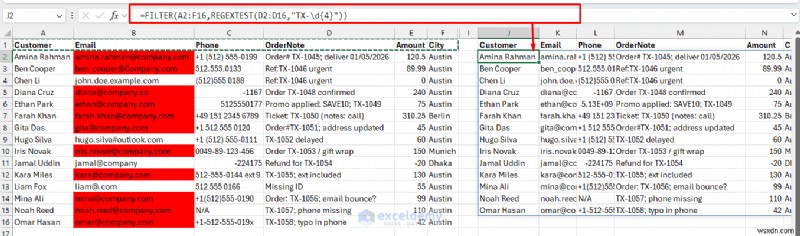
उदाहरण 7:ऑर्डर आईडी वाली पंक्तियों को फ़िल्टर करना
=FILTER(A2:F16,REGEXTEST(D2:D16,"TX-\d{4}"))
<पी> यह सूत्र रेगेक्स पैटर्न के आधार पर डेटा फ़िल्टर करता है। एक्सेल में उन्नत रेगेक्स तकनीक
- आगे की ओर देखें/पीछे की ओर देखें: पाठ का उपभोग किए बिना शर्तों पर जोर दें।
- सकारात्मक पूर्वानुमान:(?=…) उदाहरण के लिए, % चिह्न से पहले संख्याओं के लिए \d+(?=%)$।
- कीमतें निकालने के लिए REGEXEXTRACT में उपयोग करें:\d+\.\d{2}(?=\sUSD)
- गैर-कैप्चरिंग समूह: (?:…) कैप्चर के बिना समूहीकरण के लिए।
- विकल्प: विकल्पों के लिए, उदाहरण के लिए, (http|https)://\S+ URL के लिए।
- सरणी को संभालना: यदि REGEXEXTRACT एकाधिक समूह लौटाता है, तो INDEX या स्पिल रेंज का उपयोग करें।
- अन्य कार्यों के साथ संयोजन: शक्तिशाली वर्कफ़्लो के लिए IF, FILTER, या LAMBDA के साथ नेस्ट करें।
टिप्स और सर्वोत्तम अभ्यास
- परीक्षण पैटर्न: "ईसीएमएस्क्रिप्ट" फ्लेवर (एक्सेल के रेगेक्स के सबसे करीब) के साथ regex101.com जैसे ऑनलाइन टूल का उपयोग करें।
- प्रदर्शन: बड़े डेटासेट पर रेगेक्स धीमा हो सकता है; पहले नमूनों पर परीक्षण करें।
- त्रुटियाँ: यदि कोई मिलान नहीं है, तो REGEXEXTRACT #N/A लौटाता है; IFNA या IFERROR से संभालें।
- सीमाएं: एक्सेल का रेगेक्स पूर्ण पीसीआरई समर्थन के बिना, एक उपसमूह पर आधारित है, इसलिए रिकर्सन जैसी उन्नत सुविधाओं से बचें।
- अधिक सीखना: वास्तविक डेटासेट के साथ अभ्यास करें। रेगेक्स उपयोग के साथ आसान हो जाता है!
प्रैक्टिस वर्कबुक डाउनलोड करें
समापन
<पी> एक्सेल पावर उपयोगकर्ता डेटा सफाई, सत्यापन और स्वचालन में तेजी लाने के लिए हमारे रेगेक्स क्रैश कोर्स का पालन कर सकते हैं। एक बार जब आप बुनियादी बिल्डिंग ब्लॉक्स के साथ सहज हो जाएं, तो अधिक परिष्कृत पैटर्न मिलान के लिए लुकहेड्स और लुकबैक्स का पता लगाएं। यह क्रैश कोर्स आपको आरंभ कराता है:पहले अभिव्यक्ति को समझें, फिर एक रिक्त कार्यपुस्तिका में पैटर्न के साथ प्रयोग करें। रेगेक्स आपके एक्सेल में टेक्स्ट को संभालने के तरीके को बदल सकता है! समाधान के साथ निःशुल्क उन्नत एक्सेल अभ्यास प्राप्त करें!-
 Excel में रेंज कैसे खोजें और गणना कैसे करें
Excel में रेंज कैसे खोजें और गणना कैसे करें
गणितीय रूप से, आप किसी विशेष डेटासेट के अधिकतम मान से न्यूनतम मान घटाकर एक श्रेणी की गणना करते हैं। यह एक डेटासेट के भीतर मूल्यों के प्रसार का प्रतिनिधित्व करता है और परिवर्तनशीलता को मापने के लिए उपयोगी है - सीमा जितनी बड़ी होगी, आपका डेटा उतना ही अधिक फैला हुआ और परिवर्तनशील होगा। सौभाग्य से, एक
-
 Microsoft Excel सूत्र स्वचालित रूप से अपडेट नहीं हो रहे हैं
Microsoft Excel सूत्र स्वचालित रूप से अपडेट नहीं हो रहे हैं
प्रत्येक उपयोगकर्ता सहमत होगा कि माइक्रोसॉफ्ट एक्सेल आधुनिक कंप्यूटिंग की पुरातनता में सबसे उपयोगी उपकरणों में से एक है। हर एक दिन, लाखों लोग Microsoft Excel स्प्रैडशीट का उपयोग ढेर सारे कार्यों को करने के लिए करते हैं, जो साधारण से शुरू करते हैं जैसे जर्नल प्रविष्टियाँ या रिकॉर्ड बनाए रखना और जटिल
-
 आउटलुक 2013/2016 और 2010 में ऑफिस के जवाबों को कैसे सेटअप करें?
आउटलुक 2013/2016 और 2010 में ऑफिस के जवाबों को कैसे सेटअप करें?
आउट-ऑफ़-ऑफ़िस उत्तर, जिसे स्वचालित उत्तर भी कहा जाता है, Microsoft Outlook में आपको ई-मेल भेजने वाले लोगों को स्वचालित उत्तर भेजने के लिए एक बहुत ही उपयोगी सुविधा है। यह प्रेषकों को आपकी उपलब्धता से अद्यतन रखने में उपयोगी है। यह सुविधा आउटलुक 2013, आउटलुक 2016, आउटलुक 2010 और यहां तक कि माइक्रोसॉफ