<पी> एक्सेल एक शक्तिशाली डेटा प्रबंधन और विश्लेषण उपकरण है। यह त्वरित रिपोर्टिंग और गणना के लिए एकदम सही है, लेकिन जब काम गड़बड़, दोहराव या बहुत बड़ा हो जाता है तो पायथन मदद करता है। पायथन स्वचालन, उन्नत विश्लेषण और एकीकरण संभावनाओं को खोलता है जो एक्सेल की अंतर्निहित सुविधाओं से परे हैं। पांडा जैसी पायथन लाइब्रेरी डेटा हेरफेर और openpyxl के लिए सीधे एक्सेल फ़ाइल हैंडलिंग के लिए इसे सहज बनाएं। <पी> इस ट्यूटोरियल में, हम पांच चीजें दिखाएंगे जो आप एक्सेल + पायथन के साथ कर सकते हैं। <पी> एक्सेल और पायथन के साथ आप जो पांच चीजें कर सकते हैं, उनका पता लगाने के लिए नमूना बिक्री डेटा पर विचार करें।
1. गंदे एक्सेल डेटा को साफ़ और मानकीकृत करें (बार-बार)
<पी> एक्सेल में गन्दा डेटा होना आम बात है, क्योंकि वास्तविक दुनिया का डेटा शायद ही कभी साफ़ होता है। अक्सर, डेटा में अतिरिक्त स्थान, मिश्रित पूंजीकरण, पाठ के रूप में संग्रहीत संख्याएं, असंगत स्वरूपण, गुम मान, डुप्लिकेट प्रविष्टियां या डेटा होता है जिसे विश्लेषण से पहले पुनर्गठन की आवश्यकता होती है। यह समस्या सूत्रों और विश्लेषणों को बर्बाद कर देती है। <पी> पायथन डेटा-क्लीनिंग कार्यों में उत्कृष्टता प्राप्त करता है। आप ऐसी स्क्रिप्ट लिख सकते हैं जो विभिन्न फ़ाइलों में डेटा प्रारूपों को मानकीकृत करती हैं, बुद्धिमान तरीकों का उपयोग करके लापता मानों को भरती हैं, डुप्लिकेट हटाती हैं, पैटर्न के आधार पर कॉलम को विभाजित या संयोजित करती हैं, और व्यावसायिक नियमों के विरुद्ध डेटा को मान्य करती हैं। इन चरणों के लिए एक्सेल में घंटों तक मैन्युअल रूप से ढूंढने और बदलने के संचालन की आवश्यकता हो सकती है। पायथन का उपयोग करके, आप एक दोहराने योग्य स्क्रिप्ट बना सकते हैं जो सेकंड में हजारों पंक्तियों को संसाधित करती है। <पी> मान लीजिए आपको अव्यवस्थित बिक्री डेटा प्राप्त हुआ। आइए एक पायथन स्क्रिप्ट का उपयोग करें जो अव्यवस्थित डेटा को पढ़ता है, कॉलम को साफ और मानकीकृत करता है, और गणना किए गए फ़ील्ड जोड़ता है।- राजस्व =इकाइयाँ * इकाई मूल्य
- नेटरेवेन्यू =राजस्व * (1 - डिस्काउंटपीसीटी)
import pandas as pd
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="Sales Data")
# Clean types
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
df["DiscountPct"] = pd.to_numeric(df["DiscountPct"], errors="coerce").fillna(0.0)
df["Returned"] = (
df["Returned"].astype(str).str.strip().str.lower()
.map({"yes": True, "no": False})
.fillna(False)
)
# Add calculated fields
df["Revenue"] = df["Units"] * df["UnitPrice"]
df["NetRevenue"] = df["Revenue"] * (1 - df["DiscountPct"])
# Write back into the SAME file as a NEW sheet
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="CleanData", index=False)
print("Saved CleanData sheet inside:", file_path)
<पी> 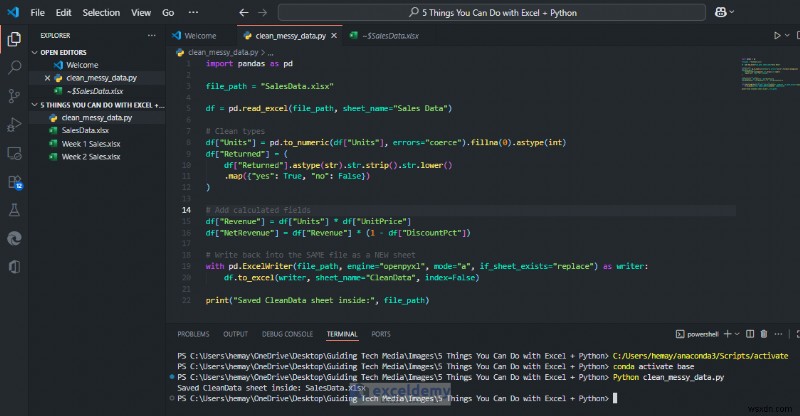 <पी> आपको साफ़ डेटासेट के साथ एक नई शीट मिलेगी जो पिवोट्स, चार्ट या लुकअप को नहीं तोड़ेगी। एक्सेल में, आप साफ किए गए डेटा से पिवोट्स/चार्ट का उपयोग करना जारी रख सकते हैं, यह जानते हुए कि यह हर रन के अनुरूप है। <पी>
<पी> आपको साफ़ डेटासेट के साथ एक नई शीट मिलेगी जो पिवोट्स, चार्ट या लुकअप को नहीं तोड़ेगी। एक्सेल में, आप साफ किए गए डेटा से पिवोट्स/चार्ट का उपयोग करना जारी रख सकते हैं, यह जानते हुए कि यह हर रन के अनुरूप है। <पी> 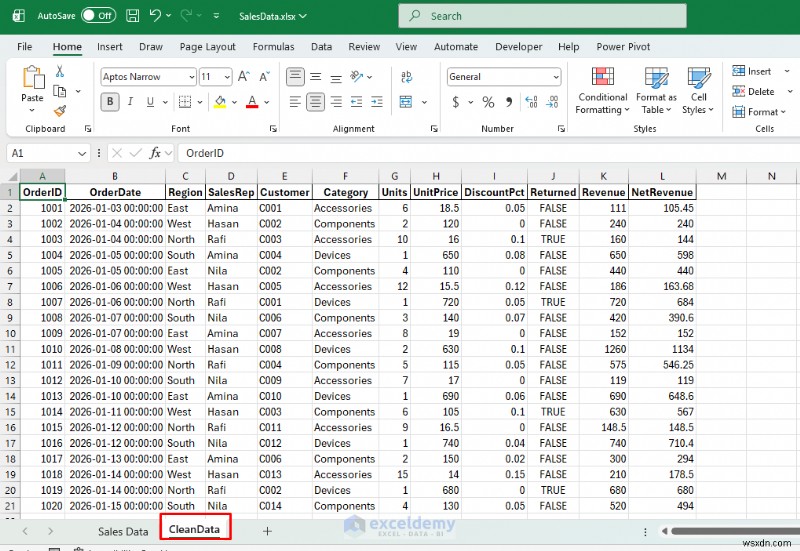
2. स्वचालित रूप से सारांश बनाएं (दोहराने योग्य रिपोर्ट)
<पी> एक्सेल में पंक्ति सीमाएँ हैं और जटिल गणनाओं के साथ यह धीमा हो सकता है। अजगर के पांडा लाइब्रेरी बड़े डेटासेट को कुशलता से संभालती है और गणना बहुत तेजी से करती है। <पी> पांडाके साथ , आप लाखों रिकॉर्ड वाले डेटासेट के साथ काम कर सकते हैं, जटिल समूहीकरण और एकत्रीकरण संचालन कर सकते हैं, और सांख्यिकीय विश्लेषण निष्पादित कर सकते हैं जो एक्सेल में अव्यावहारिक हो सकते हैं। पायथन पिवट-शैली सारांश उत्पन्न कर सकता है और उन्हें एक्सेल में निर्यात कर सकता है। मान लीजिए कि आप क्षेत्र और श्रेणी के अनुसार त्वरित सारांश चाहते हैं, लेकिन आप हर बार पिवोट्स का पुनर्निर्माण नहीं करना चाहते हैं।import pandas as pd
file_path = "SalesData.xlsx"
clean_sheet = "CleanData"
out_sheet = "Summary"
df = pd.read_excel(file_path, sheet_name=clean_sheet)
summary = (
df.groupby(["Region", "Category"], as_index=False)
.agg(
Orders=("OrderID", "count"),
Units=("Units", "sum"),
NetRevenue=("NetRevenue", "sum"),
Returns=("Returned", "sum")
)
)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
summary.to_excel(writer, sheet_name=out_sheet, index=False)
print(f"✅ Saved '{out_sheet}' sheet inside: {file_path}")
<पी> आपको राजस्व-दर-क्षेत्र सारांश मिलेगा - एक रेडी-टू-शेयर पिवट-स्टाइल शीट जो आपके द्वारा स्क्रिप्ट को दोबारा चलाने पर अपडेट हो जाती है। <पी> 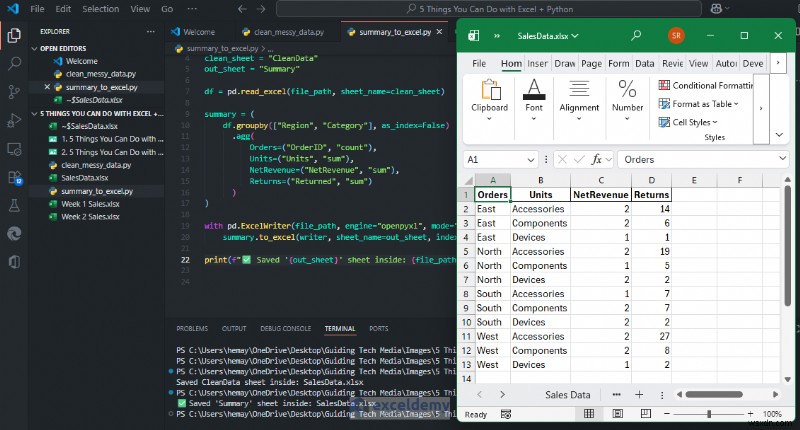
3. एक्सेल डेटा से चार्ट बनाएं (मैन्युअल फ़ॉर्मेटिंग के बिना)
<पी> चार्ट अक्सर रिपोर्टिंग का सबसे अधिक समय लेने वाला हिस्सा होते हैं। एक्सेल मानक चार्ट प्रदान करता है, लेकिन पायथन की विज़ुअलाइज़ेशन लाइब्रेरी Matplotlib जैसी है , समुद्री जन्म , और साजिश कहीं अधिक लचीलापन और परिष्कार प्रदान करें। आप कस्टम विज़ुअलाइज़ेशन उत्पन्न कर सकते हैं जो आपके डेटा में परिवर्तन होने पर स्वचालित रूप से अपडेट हो जाते हैं, इंटरैक्टिव डैशबोर्ड बनाते हैं जिन्हें उपयोगकर्ता एक्सप्लोर कर सकते हैं, या प्रत्येक तत्व पर सटीक नियंत्रण के साथ प्रकाशन-गुणवत्ता वाले ग्राफिक्स का उत्पादन कर सकते हैं। <पी> आइए क्षेत्र के आधार पर प्रदर्शन की कल्पना करें (क्षेत्र के अनुसार नेटरेवेन्यू)।import pandas as pd
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
file_path = "SalesData.xlsx"
source_sheet = "CleanData"
output_sheet = "RegionChart" # data + chart in this one sheet
# Prepare chart data (NetRevenue by Region)
df = pd.read_excel(file_path, sheet_name=source_sheet)
chart_data = (
df.groupby("Region", as_index=False)["NetRevenue"]
.sum()
.sort_values("NetRevenue", ascending=False)
)
# Write chart data into output_sheet (same workbook)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
chart_data.to_excel(writer, sheet_name=output_sheet, index=False)
# Add the native Excel chart on the same sheet
wb = load_workbook(file_path)
ws = wb[output_sheet]
chart = BarChart()
chart.title = "Net Revenue by Region"
chart.y_axis.title = "Net Revenue"
chart.x_axis.title = "Region"
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, "D2") # place chart to the right of the data table
wb.save(file_path)
print(f"✅ Chart Created: {output_sheet}")
<पी> अब आपके पास बार चार्ट के साथ क्षेत्र के अनुसार राजस्व का सारांश है। <पी> 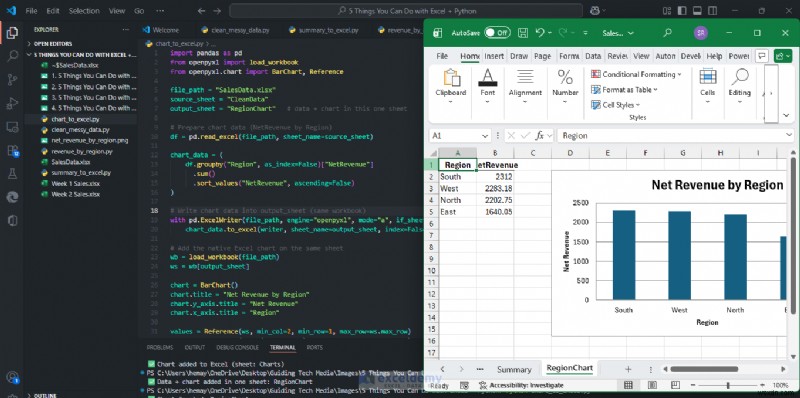
4. कई एक्सेल फ़ाइलों को एक मास्टर टेबल में मर्ज करें
<पी> विभिन्न स्रोतों से साप्ताहिक, मासिक या त्रैमासिक डेटा को मर्ज करना आम बात है। विभिन्न लोगों या टीमों से एक्सेल फ़ाइलों को मर्ज करना धीमा और त्रुटि-प्रवण है। पायथन उन्हें सेकंडों में संयोजित कर सकता है और स्रोत फ़ाइल को ट्रैक कर सकता है। <पी> आइए साप्ताहिक फ़ाइलों को साप्ताहिक रिपोर्ट/ नामक फ़ोल्डर में मर्ज करें (सभी समान कॉलम के साथ)।import pandas as pd
from pathlib import Path
base_folder = Path(__file__).resolve().parent
folder = base_folder / "Weekly Reports"
files = sorted(folder.glob("*.xlsx"))
files = [f for f in files if not f.name.startswith("~$")] # ignore Excel lock files
print("Looking in:", folder)
print("Files found:", [f.name for f in files])
frames = []
for f in files:
temp = pd.read_excel(f)
temp["SourceFile"] = f.name
frames.append(temp)
master = pd.concat(frames, ignore_index=True)
master.to_excel(base_folder / "master_report.xlsx", index=False)
print("Saved: master_report.xlsx")
<पी> आपको SourceFile के साथ एक समेकित तालिका मिलेगी ऑडिटिंग के लिए कॉलम. हर सप्ताह, आपको बस स्क्रिप्ट चलाने की आवश्यकता है। <पी> 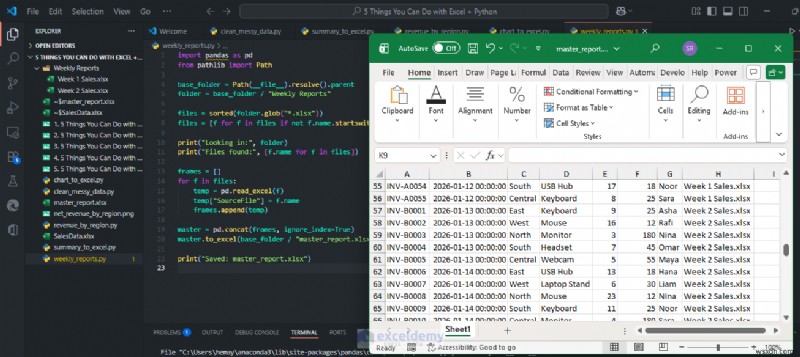
5. भविष्यवाणी करें कि एक्सेल आसानी से कुछ नहीं कर सकता (मशीन लर्निंग उदाहरण)
<पी> आप पैटर्न (छूट, श्रेणी, इकाइयां, कीमत) का उपयोग करके रिटर्न जोखिम का अनुमान लगा सकते हैं, फिर संभावनाएं लिखें ताकि एक्सेल उपयोगकर्ता फ़िल्टर और सॉर्ट कर सकें। पायथन ऐसे मशीन लर्निंग ऑपरेशन आसानी से कर सकता है। <पी> हमारा एक छोटा डेटासेट है; फिर भी, यह वर्कफ़्लो दिखाता है।import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="CleanData")
X = df[["Region", "SalesRep", "Category", "Units", "UnitPrice", "DiscountPct"]]
y = df["Returned"].astype(int)
cat_cols = ["Region", "SalesRep", "Category"]
num_cols = ["Units", "UnitPrice", "DiscountPct"]
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols),
("num", "passthrough", num_cols),
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# Predict probability of return for all rows
df["ReturnProb"] = model.predict_proba(X)[:, 1]
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="WithReturnRisk", index=False)
<पी> एक्सेल में, WithReturnRisk को एक्सप्लोर करें और ReturnProb फ़िल्टर करें उच्च से निम्न तक यह देखने के लिए कि कौन सा ऑर्डर जोखिम भरा लगता है। <पी> एक्सेल में पायथन (यदि आपके एक्सेल में उपलब्ध है)
<पी> यदि आपके कंप्यूटर पर एक्सेल में पायथन (पूर्वावलोकन) है, तो आप सीधे सेल में पायथन चला सकते हैं और परिणाम को शीट पर वापस कर सकते हैं। (माइक्रोसॉफ्ट का एक्सेल में पायथन का अवलोकन देखें .) यहां एक सरल उदाहरण है जो एक छोटी श्रृंखला को पढ़ता है, पाठ को साफ करता है, राजस्व की गणना करता है, और एक साफ तालिका लौटाता है।- एक्सेल में, अपना डेटासेट दर्ज करें
- खाली सेल पर क्लिक करें
- सूत्र पर जाएं टैब>> पायथन डालें चुनें
- पायथन स्क्रिप्ट चिपकाएँ
import pandas as pd
# Read the Excel range A1:J21 (including headers)
df = xl("A1:J21", headers=True)
# Clean text columns
for col in ["Region", "SalesRep"]:
df[col] = df[col].astype(str).str.strip().str.title()
# Fix data types
df["OrderDate"] = pd.to_datetime(df["OrderDate"], errors="coerce")
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
# Add a calculated column
df["Revenue"] = df["Units"] * df["UnitPrice"]
df
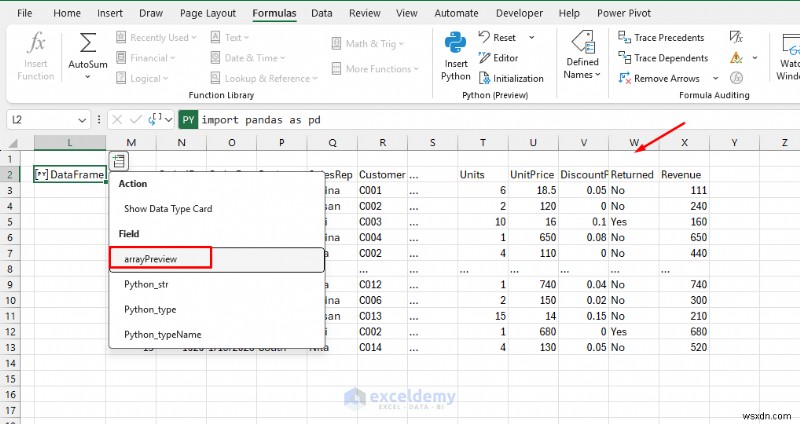
<पी> यह डेटाफ़्रेम लौटाएगा , जो कि पायथन की टेबल ऑब्जेक्ट है। एक्सेल इसे एक तालिका पूर्वावलोकन (और एक कार्ड) के रूप में दिखाता है। <पी> 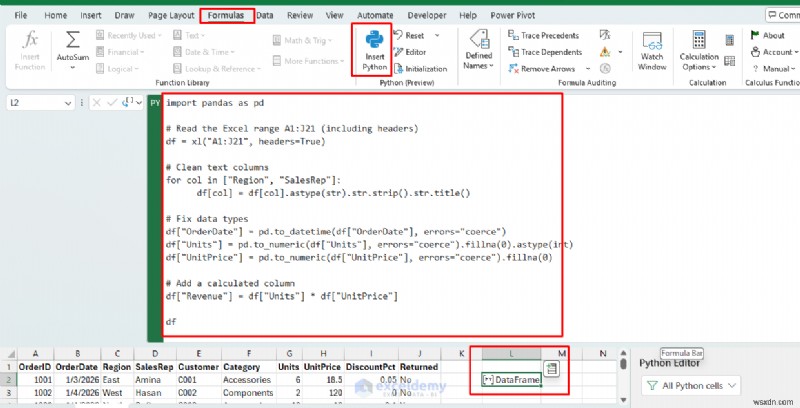 <पी> अब आउटपुट को एक साफ़ तालिका के रूप में कोशिकाओं में "स्पिल" करें।
<पी> अब आउटपुट को एक साफ़ तालिका के रूप में कोशिकाओं में "स्पिल" करें। - डेटा डालें पर क्लिक करें डेटाफ़्रेम से>> डेटाटाइप कार्ड दिखाएं चुनें तालिका का पूर्वावलोकन करने के लिए
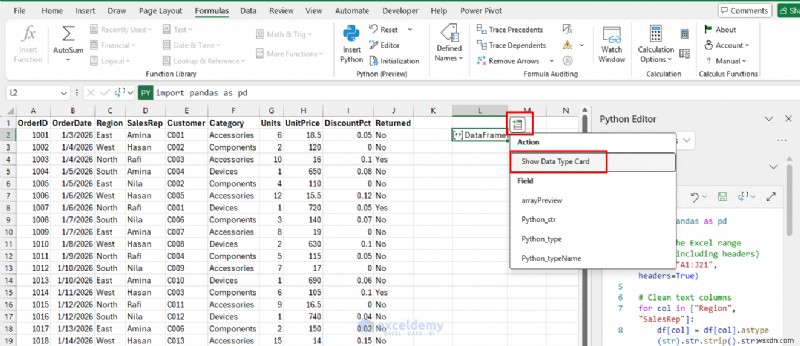
- arrayPreview चुनें टेबल को Excel में लाने के लिए
- अब आपके पास मानकीकृत पाठ और एक नया राजस्व है स्तंभ