इस खंड में हम देखेंगे कि ओपन एड्रेसिंग स्कीम में डबल हैशिंग तकनीक क्या है। एक साधारण हैश फ़ंक्शन h´(x) :U → {0, 1, । . ।, एम - 1}। ओपन एड्रेसिंग स्कीम में, वास्तविक हैश फ़ंक्शन h(x) सामान्य हैश फ़ंक्शन h’(x) ले रहा है, जब स्थान खाली नहीं है, तो सम्मिलित करने के लिए कुछ स्थान प्राप्त करने के लिए एक और हैश फ़ंक्शन करें।
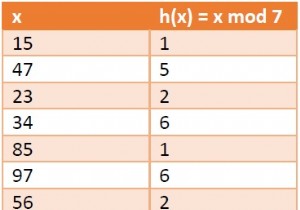
$$h_{1}(x)=x\:mod\:m$$
$$h_{2}(x)=x\:mod\:m^{\prime}$$
$$h(x,i)=(h^{1}(x)+ih^{2})\:mod\:m$$
i =0, 1, का मान। . ।, एम - 1. तो हम i =0 से शुरू करते हैं, और इसे तब तक बढ़ाते हैं जब तक हमें एक खाली जगह नहीं मिल जाती। तो शुरू में जब i =0, तब h(x, i) h´(x) के समान होता है।
उदाहरण
मान लीजिए कि हमारे पास आकार 20 (एम =20) की एक सूची है। हम कुछ तत्वों को रैखिक जांच फैशन में रखना चाहते हैं। तत्व हैं {96, 48, 63, 29, 87, 77, 48, 65, 69, 94, 61}
$$h_{1}(x)=x\:mod\:20$$
$$h_{2}(x)=x\:mod\:13$$
x h(x, i) =(h1 (x) + ih2(x)) mod 20

हैश टेबल