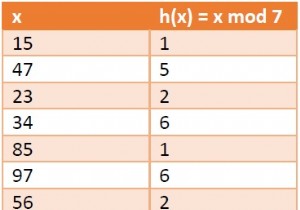
यहां हम विभाजन के साथ हैशिंग के बारे में चर्चा करेंगे। इसके लिए हम हैश फंक्शन का उपयोग करते हैं -
ℎ(𝑥) = 𝑥 𝑚𝑜𝑑 𝑚
इस हैश फ़ंक्शन का उपयोग करने के लिए हम एक सरणी A [0, … m - 1] बनाए रखते हैं। जहां सरणी का प्रत्येक तत्व लिंक की गई सूची के प्रमुख के लिए एक सूचक है। लिंक की गई सूची ली सरणी तत्व की ओर इशारा करती है ए [i] सभी तत्वों को x रखती है जैसे कि h(x) =i। इस तकनीक को हैशिंग बाय चेनिंग के रूप में जाना जाता है।
ऐसी हैश तालिका में, यदि हम एक तत्व x को बढ़ाना चाहते हैं, तो इसमें O(1) समय लगेगा। हम सूचकांक i =h(x) की गणना करते हैं। फिर x को सूची में जोड़ें या जोड़ें। अगर हम किसी तत्व को खोजना या हटाना चाहते हैं, तो यह प्रक्रिया इतनी आसान नहीं है। हमें सूचकांक i =h(x) ज्ञात करना है। फिर ट्रैवर्स लिस्ट ली। जब तक हम वांछित मूल्य तक नहीं पहुंच जाते या सूची समाप्त नहीं हो जाती। इस ऑपरेशन में सूची Li . के आकार के अनुरूप समय लग रहा है . यदि हमारे समुच्चय S में 0, m, 2m, 3m, …., nm तत्व हैं, तो L0 में संग्रहीत सभी तत्वों को खोजने और हटाने में रैखिक समय लगेगा।
इस तरह की स्थिति बहुत कम होती है। उदाहरण के लिए, यदि S को सार्वभौमिक समुच्चय U में समान रूप से और स्वतंत्र रूप से वितरित किया जाता है, और u, m का गुणज है, तो प्रत्येक सूची का अपेक्षित आकार Li केवल n/m है। इस मामले में खोज और हटाना O . लेता है (1 + α) समय की मात्रा। उल्लिखित परिदृश्य से बचने के लिए, हमें बुद्धिमानी से एम चुनना होगा। आम तौर पर, हम 2 की शक्ति के रूप में m से बचते हैं। m को एक अभाज्य के रूप में लेने की सिफारिश की जाती है जो 2 की शक्ति के बहुत करीब नहीं है।