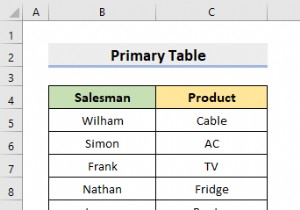
रिलेशनल डेटाबेस डिज़ाइन (RDD) मॉडल की जानकारी और डेटा पंक्तियों और स्तंभों के साथ तालिकाओं के एक सेट में। संबंध/तालिका की प्रत्येक पंक्ति एक रिकॉर्ड का प्रतिनिधित्व करती है, और प्रत्येक स्तंभ डेटा की एक विशेषता का प्रतिनिधित्व करता है। स्ट्रक्चर्ड क्वेरी लैंग्वेज (एसक्यूएल) का उपयोग रिलेशनल डेटाबेस में हेरफेर करने के लिए किया जाता है। एक रिलेशनल डेटाबेस का डिज़ाइन चार चरणों से बना होता है, जहाँ डेटा को संबंधित तालिकाओं के एक सेट में तैयार किया जाता है। चरण हैं -
- संबंधों/विशेषताओं को परिभाषित करें
- प्राथमिक कुंजियों को परिभाषित करें
- रिश्तों को परिभाषित करें
- सामान्यीकरण
रिलेशनल डेटाबेस डेटा को व्यवस्थित करने और लेनदेन करने के उनके दृष्टिकोण में अन्य डेटाबेस से भिन्न होते हैं। RDD में, डेटा को तालिकाओं में व्यवस्थित किया जाता है और सभी प्रकार के डेटा एक्सेस नियंत्रित लेनदेन के माध्यम से किए जाते हैं। रिलेशनल डेटाबेस डिज़ाइन डेटाबेस डिज़ाइन से आवश्यक ACID (परमाणुता, स्थिरता, अखंडता और स्थायित्व) गुणों को संतुष्ट करता है। रिलेशनल डेटाबेस डिज़ाइन डेटा प्रबंधन समस्याओं से निपटने के लिए अनुप्रयोगों में डेटाबेस सर्वर के उपयोग को अनिवार्य करता है।
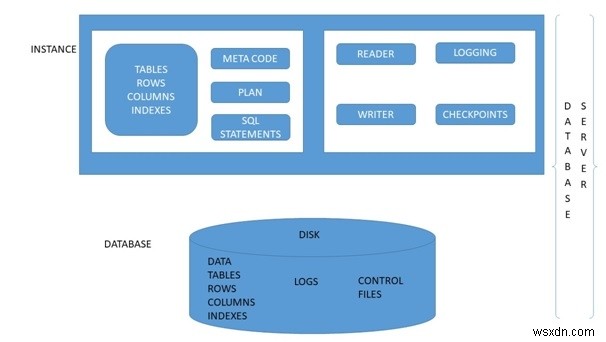
रिलेशनल डेटाबेस डिजाइन प्रक्रिया
डेटाबेस डिजाइन विज्ञान की तुलना में अधिक कला है, क्योंकि आपको कई निर्णय लेने होते हैं। डेटाबेस आमतौर पर किसी विशेष एप्लिकेशन के अनुरूप अनुकूलित किए जाते हैं। कोई भी दो अनुकूलित अनुप्रयोग समान नहीं हैं, और इसलिए, कोई भी दो डेटाबेस एक जैसे नहीं हैं। इन डिज़ाइन निर्णयों को करने के लिए दिशानिर्देश (आमतौर पर क्या नहीं करना है के संदर्भ में) प्रदान किए जाते हैं, लेकिन विकल्प अंततः डिज़ाइनर पर निर्भर करते हैं।
चरण 1 - डेटाबेस के उद्देश्य को परिभाषित करें (आवश्यकता विश्लेषण)
- आवश्यकताओं को इकट्ठा करें और अपने डेटाबेस के उद्देश्य को परिभाषित करें।
- नमूना इनपुट फॉर्म, प्रश्न और रिपोर्ट तैयार करने से अक्सर मदद मिलती है।
चरण 2 - डेटा एकत्र करें, तालिकाओं में व्यवस्थित करें और प्राथमिक कुंजी निर्दिष्ट करें
- डेटाबेस के उद्देश्य पर निर्णय लेने के बाद, डेटाबेस में संग्रहीत करने के लिए आवश्यक डेटा एकत्र करें। डेटा को विषय-आधारित तालिकाओं में विभाजित करें।
- तथाकथित प्राथमिक कुंजी के रूप में एक कॉलम (या कुछ कॉलम) चुनें, जो प्रत्येक पंक्ति की विशिष्ट रूप से पहचान करता है।
चरण 3 - तालिकाओं के बीच संबंध बनाएं
स्वतंत्र और असंबंधित तालिकाओं से युक्त एक डेटाबेस बहुत कम उद्देश्य की पूर्ति करता है (आप इसके बजाय एक स्प्रेडशीट का उपयोग करने पर विचार कर सकते हैं)। एक संबंधपरक डेटाबेस की शक्ति उस संबंध में निहित है जिसे तालिकाओं के बीच परिभाषित किया जा सकता है। एक संबंधपरक डेटाबेस को डिजाइन करने में सबसे महत्वपूर्ण पहलू तालिकाओं के बीच संबंधों की पहचान करना है। संबंधों के प्रकारों में शामिल हैं:
- एक से अनेक
- अनेक-से-अनेक
- एक-से-एक
एक से अनेक
"क्लास रोस्टर" डेटाबेस में, एक शिक्षक शून्य या अधिक कक्षाएं पढ़ा सकता है, जबकि एक कक्षा को एक (और केवल एक) शिक्षक द्वारा पढ़ाया जाता है। एक "कंपनी" डेटाबेस में, एक प्रबंधक शून्य या अधिक कर्मचारियों का प्रबंधन करता है, जबकि एक कर्मचारी को एक (और केवल एक) प्रबंधक द्वारा प्रबंधित किया जाता है। एक "उत्पाद बिक्री" डेटाबेस में, एक ग्राहक कई ऑर्डर दे सकता है; जबकि एक विशेष ग्राहक द्वारा ऑर्डर दिया जाता है। इस तरह के संबंध को एक-से-अनेक के रूप में जाना जाता है।
एक-से-अनेक संबंध को एक तालिका में प्रदर्शित नहीं किया जा सकता है। उदाहरण के लिए, "क्लास रोस्टर" डेटाबेस में, हम शिक्षक नामक एक तालिका से शुरू कर सकते हैं, जो शिक्षकों (जैसे नाम, कार्यालय, फोन और ईमेल) के बारे में जानकारी संग्रहीत करती है। प्रत्येक शिक्षक द्वारा सिखाई गई कक्षाओं को संग्रहीत करने के लिए, हम कक्षा 1, कक्षा 2, कक्षा 3 कॉलम बना सकते हैं, लेकिन कितने कॉलम बनाने के लिए तुरंत एक समस्या का सामना करना पड़ता है। दूसरी ओर, यदि हम कक्षा नामक तालिका से शुरू करते हैं, जो एक कक्षा के बारे में जानकारी संग्रहीत करती है, तो हम (एक) शिक्षक (जैसे नाम, कार्यालय, फोन और ईमेल) के बारे में जानकारी संग्रहीत करने के लिए अतिरिक्त कॉलम बना सकते हैं। हालांकि, चूंकि एक शिक्षक कई कक्षाओं को पढ़ा सकता है, इसलिए इसका डेटा तालिका कक्षाओं में कई पंक्तियों में दोहराया जाएगा।
एक-से-अनेक संबंध का समर्थन करने के लिए, हमें दो तालिकाओं को डिज़ाइन करने की आवश्यकता है:उदा। प्राथमिक कुंजी के रूप में क्लास आईडी के साथ कक्षाओं के बारे में जानकारी संग्रहीत करने के लिए एक तालिका कक्षाएं; और एक तालिका शिक्षक प्राथमिक कुंजी के रूप में शिक्षक आईडी के साथ शिक्षकों के बारे में जानकारी संग्रहीत करने के लिए। फिर हम टेबल क्लासेस ("कई"-एंड या चाइल्ड टेबल), जैसा कि नीचे दिखाया गया है।
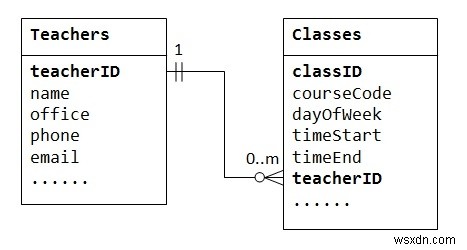 चाइल्ड टेबल Classes में कॉलम TeacherID को फॉरेन की के रूप में जाना जाता है। चाइल्ड टेबल की विदेशी कुंजी पैरेंट टेबल की प्राथमिक कुंजी होती है, जिसका इस्तेमाल पैरेंट टेबल के संदर्भ में किया जाता है।
चाइल्ड टेबल Classes में कॉलम TeacherID को फॉरेन की के रूप में जाना जाता है। चाइल्ड टेबल की विदेशी कुंजी पैरेंट टेबल की प्राथमिक कुंजी होती है, जिसका इस्तेमाल पैरेंट टेबल के संदर्भ में किया जाता है।
अनेक-से-अनेक
"उत्पाद बिक्री" डेटाबेस में, ग्राहक के आदेश में एक या अधिक उत्पाद हो सकते हैं; और एक उत्पाद कई ऑर्डर में प्रदर्शित हो सकता है। "किताबों की दुकान" डेटाबेस में, एक या अधिक लेखकों द्वारा एक पुस्तक लिखी जाती है; जबकि कोई लेखक शून्य या अधिक पुस्तकें लिख सकता है। इस प्रकार के संबंध को अनेक-से-अनेक के रूप में जाना जाता है।
आइए "उत्पाद बिक्री" डेटाबेस के साथ उदाहरण दें। हम दो तालिकाओं से शुरू करते हैं:उत्पाद और आदेश। तालिका उत्पादों में उत्पाद आईडी के साथ प्राथमिक कुंजी के रूप में उत्पादों (जैसे नाम, विवरण और मात्राइनस्टॉक) के बारे में जानकारी होती है। तालिका के आदेशों में ग्राहक के आदेश होते हैं (ग्राहक आईडी, दिनांक आदेशित, दिनांक आवश्यक और स्थिति)। फिर से, हम ऑर्डर किए गए आइटम को ऑर्डर टेबल के अंदर स्टोर नहीं कर सकते, क्योंकि हम नहीं जानते कि आइटम के लिए कितने कॉलम आरक्षित करने हैं। हम ऑर्डर जानकारी को उत्पाद तालिका में भी संग्रहीत नहीं कर सकते हैं।
कई-से-अनेक संबंधों का समर्थन करने के लिए, हमें एक तीसरी तालिका (जिसे जंक्शन तालिका के रूप में जाना जाता है) बनाने की आवश्यकता होती है, जैसे ऑर्डर विवरण (या ऑर्डरलाइन), जहां प्रत्येक पंक्ति किसी विशेष ऑर्डर के आइटम का प्रतिनिधित्व करती है। ऑर्डर विवरण तालिका के लिए, प्राथमिक कुंजी में दो कॉलम होते हैं:ऑर्डर आईडी और उत्पाद आईडी, जो प्रत्येक पंक्ति को विशिष्ट रूप से पहचानते हैं। ऑर्डर विवरण तालिका में कॉलम ऑर्डर आईडी और उत्पाद आईडी का उपयोग ऑर्डर और उत्पाद तालिकाओं को संदर्भित करने के लिए किया जाता है, इसलिए, वे ऑर्डर विवरण तालिका में विदेशी कुंजी भी हैं।
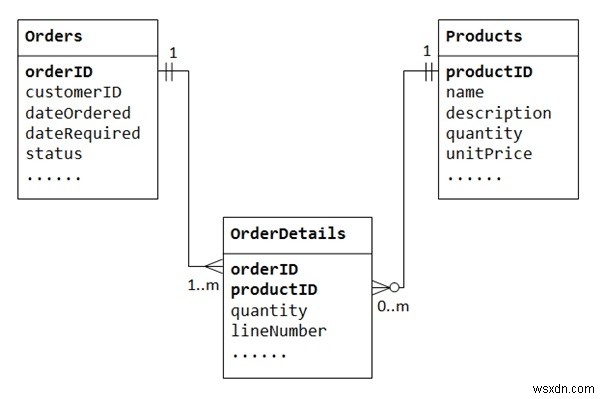
कई-से-अनेक संबंध, वास्तव में, जंक्शन तालिका की शुरूआत के साथ दो एक-से-कई संबंधों के रूप में कार्यान्वित किए जाते हैं।
ऑर्डर विवरण में एक ऑर्डर में कई आइटम होते हैं। ऑर्डर विवरण आइटम एक विशेष ऑर्डर से संबंधित होता है।
एक उत्पाद कई ऑर्डर विवरण में प्रकट हो सकता है। प्रत्येक ऑर्डर विवरण आइटम में एक उत्पाद निर्दिष्ट होता है।
वन-टू-वन
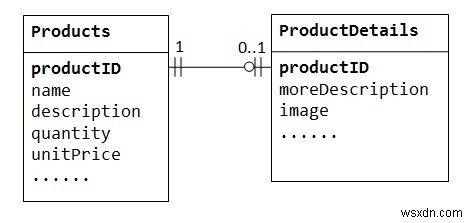
"उत्पाद बिक्री" डेटाबेस में, किसी उत्पाद में वैकल्पिक पूरक जानकारी जैसे छवि, अधिक विवरण और टिप्पणी हो सकती है। उन्हें उत्पाद तालिका के अंदर रखने से कई रिक्त स्थान प्राप्त होते हैं (इन वैकल्पिक डेटा के बिना उन रिकॉर्ड में)। इसके अलावा, ये बड़े डेटा डेटाबेस के प्रदर्शन को ख़राब कर सकते हैं।
इसके बजाय, हम वैकल्पिक डेटा को स्टोर करने के लिए एक और टेबल (जैसे ProductDetails, ProductLines या ProductExtras) बना सकते हैं। केवल वैकल्पिक डेटा वाले उन उत्पादों के लिए एक रिकॉर्ड बनाया जाएगा। दो टेबल, उत्पाद और उत्पाद विवरण, एक-से-एक संबंध प्रदर्शित करते हैं। अर्थात्, मूल तालिका में प्रत्येक पंक्ति के लिए, चाइल्ड टेबल में अधिकतम एक पंक्ति (संभवतः शून्य) होती है। दोनों तालिकाओं के लिए प्राथमिक कुंजी के रूप में एक ही कॉलम उत्पाद आईडी का उपयोग किया जाना चाहिए।
कुछ डेटाबेस एक तालिका के अंदर बनाए जा सकने वाले स्तंभों की संख्या को सीमित करते हैं। आप डेटा को दो तालिकाओं में विभाजित करने के लिए एक-से-एक संबंध का उपयोग कर सकते हैं। एक-से-एक संबंध कुछ संवेदनशील डेटा को सुरक्षित तालिका में संग्रहीत करने के लिए भी उपयोगी है, जबकि गैर-संवेदनशील डेटा मुख्य तालिका में।
कॉलम डेटा प्रकार
आपको प्रत्येक कॉलम के लिए उपयुक्त डेटा प्रकार चुनना होगा। आमतौर पर डेटा प्रकारों में पूर्णांक, फ़्लोटिंग-पॉइंट नंबर, स्ट्रिंग (या टेक्स्ट), दिनांक/समय, बाइनरी, संग्रह (जैसे गणना और सेट) शामिल होते हैं।
चरण 4 - डिज़ाइन को परिष्कृत और सामान्य करें
उदाहरण के लिए,
- और कॉलम जोड़ना,
- एक-से-एक संबंध का उपयोग करके वैकल्पिक डेटा के लिए एक नई तालिका बनाएं,
- एक बड़ी तालिका को दो छोटी तालिकाओं में विभाजित करें,
- अन्य तरीके।
सामान्यीकरण
आपका डेटाबेस संरचनात्मक रूप से सही और इष्टतम है या नहीं, यह जांचने के लिए तथाकथित सामान्यीकरण नियम लागू करें।
पहला सामान्य फ़ॉर्म (1NF): एक तालिका 1NF होती है यदि प्रत्येक सेल में एक मान होता है, मानों की सूची नहीं। इस संपत्ति को परमाणु के रूप में जाना जाता है। 1NF भी आइटम 1, आइटम 2, आइटम N जैसे कॉलम के दोहराए जाने वाले समूह को प्रतिबंधित करता है। इसके बजाय, आपको एक-से-अनेक संबंध का उपयोग करके एक अन्य तालिका बनानी चाहिए।
दूसरा सामान्य रूप (2NF) - एक तालिका 2NF है यदि यह 1NF है और प्रत्येक गैर-कुंजी कॉलम प्राथमिक कुंजी पर पूरी तरह से निर्भर है। इसके अलावा, यदि प्राथमिक कुंजी कई स्तंभों से बनी है, तो प्रत्येक गैर-कुंजी स्तंभ पूरे सेट पर निर्भर करेगा न कि उसके भाग पर।
उदाहरण के लिए, ऑर्डर विवरण तालिका की प्राथमिक कुंजी जिसमें ऑर्डर आईडी और उत्पाद आईडी शामिल हैं। यदि यूनिटप्राइस केवल उत्पाद आईडी पर निर्भर है, तो इसे ऑर्डर विवरण तालिका (लेकिन उत्पाद तालिका में) में नहीं रखा जाएगा। दूसरी ओर, यदि इकाई मूल्य उत्पाद के साथ-साथ विशेष आदेश पर निर्भर है, तो इसे ऑर्डर विवरण तालिका में रखा जाएगा।
तीसरा सामान्य रूप (3NF) - एक तालिका 3NF है यदि यह 2NF है और गैर-कुंजी कॉलम एक दूसरे से स्वतंत्र हैं। दूसरे शब्दों में, गैर-कुंजी कॉलम प्राथमिक कुंजी पर निर्भर होते हैं, केवल प्राथमिक कुंजी पर और कुछ नहीं। उदाहरण के लिए, मान लीजिए कि हमारे पास उत्पाद तालिका है जिसमें कॉलम उत्पाद आईडी (प्राथमिक कुंजी), नाम और इकाई मूल्य है। कॉलम छूट दर उत्पाद तालिका से संबंधित नहीं होगी यदि यह इकाई मूल्य पर भी निर्भर है, जो प्राथमिक कुंजी का हिस्सा नहीं है।
उच्च सामान्य रूप: 3NF में इसकी अपर्याप्तता है, जो एक उच्च सामान्य रूप की ओर ले जाती है, जैसे कि Boyce/Codd सामान्य रूप, चौथा सामान्य रूप (4NF) और पाँचवाँ सामान्य रूप (5NF), जो इस ट्यूटोरियल के दायरे से बाहर है।
कभी-कभी, आप प्रदर्शन कारणों से कुछ सामान्यीकरण नियमों को तोड़ने का निर्णय ले सकते हैं (उदाहरण के लिए, ऑर्डर तालिका में कुल मूल्य नामक कॉलम बनाएं जिसे ऑर्डर विवरण रिकॉर्ड से प्राप्त किया जा सकता है); या क्योंकि अंतिम उपयोगकर्ता ने इसके लिए अनुरोध किया था। सुनिश्चित करें कि आप इसके बारे में पूरी तरह से जानते हैं, इसे संभालने के लिए प्रोग्रामिंग तर्क विकसित करें, और निर्णय को ठीक से दस्तावेज करें।
अखंडता नियम
आपको अपने डिजाइन की अखंडता की जांच करने के लिए अखंडता नियमों को भी लागू करना चाहिए -
1. निकाय की सत्यनिष्ठा नियम - प्राथमिक कुंजी में NULL नहीं हो सकता। अन्यथा, यह विशिष्ट रूप से पंक्ति की पहचान नहीं कर सकता है। कई स्तंभों से बनी समग्र कुंजी के लिए, किसी भी स्तंभ में NULL नहीं हो सकता है। अधिकांश RDBMS इस नियम की जाँच करते हैं और इसे लागू करते हैं।
2.संदर्भात्मक सत्यनिष्ठा नियम - प्रत्येक विदेशी कुंजी मान को संदर्भित तालिका (या मूल तालिका) में प्राथमिक कुंजी मान से मेल खाना चाहिए।
आप चाइल्ड टेबल में एक विदेशी कुंजी के साथ एक पंक्ति तभी सम्मिलित कर सकते हैं जब मूल तालिका में मान मौजूद हो।
यदि मूल तालिका में कुंजी का मान बदलता है (उदाहरण के लिए, पंक्ति अद्यतन या हटाई गई), तो चाइल्ड टेबल में इस विदेशी कुंजी के साथ सभी पंक्तियों को तदनुसार संभाला जाना चाहिए। आप या तो (ए) परिवर्तनों को अस्वीकार कर सकते हैं; (बी) तदनुसार चाइल्ड टेबल में परिवर्तन को कैस्केड करें (या रिकॉर्ड हटाएं); (सी) चाइल्ड टेबल में कुंजी मान को NULL पर सेट करें।
अधिकांश RDBMS को एक निर्दिष्ट तरीके से जांच करने और संदर्भात्मक अखंडता सुनिश्चित करने के लिए स्थापित किया जा सकता है।
3.व्यावसायिक तर्क वफ़ादारी - उपरोक्त दो सामान्य अखंडता नियमों के अलावा, व्यावसायिक तर्क से संबंधित अखंडता (सत्यापन) हो सकती है, उदाहरण के लिए, ज़िप कोड एक निश्चित सीमा के भीतर 5 अंकों का होगा, डिलीवरी की तारीख और समय व्यावसायिक घंटों में गिर जाएगा; ऑर्डर की गई मात्रा स्टॉक में मात्रा के बराबर या उससे कम होगी, आदि। इन्हें अमान्यता नियम (विशिष्ट कॉलम के लिए) या प्रोग्रामिंग लॉजिक किया जा सकता है।
स्तंभ अनुक्रमण
डेटा खोज और पुनर्प्राप्ति की सुविधा के लिए आप चयनित कॉलम पर एक इंडेक्स बना सकते हैं। अनुक्रमणिका एक संरचित फ़ाइल है जो SELECT के लिए डेटा एक्सेस को गति देती है लेकिन INSERT, UPDATE और DELETE को धीमा कर सकती है। एक इंडेक्स संरचना के बिना, एक मिलान मानदंड के साथ एक चयन क्वेरी को संसाधित करने के लिए (उदाहरण के लिए, ग्राहकों से चुनें * जहां नाम ='टैन आह टेक'), डेटाबेस इंजन को तालिका में प्रत्येक रिकॉर्ड की तुलना करने की आवश्यकता होती है। एक विशेष सूचकांक (उदाहरण के लिए, बीटीआरईई संरचना में) प्रत्येक रिकॉर्ड की तुलना किए बिना रिकॉर्ड तक पहुंच सकता है। हालांकि, जब भी कोई रिकॉर्ड बदला जाता है, तो इंडेक्स को फिर से बनाने की आवश्यकता होती है, जिसके परिणामस्वरूप इंडेक्स का उपयोग करने के साथ ओवरहेड जुड़ा होता है।
इंडेक्स को एक कॉलम, कॉलम के एक सेट (जिसे कॉन्टेनेटेड इंडेक्स कहा जाता है), या कॉलम के हिस्से पर परिभाषित किया जा सकता है (उदाहरण के लिए, VARCHAR (100) के पहले 10 अक्षर) (आंशिक इंडेक्स कहा जाता है) . आप एक टेबल में एक से अधिक इंडेक्स बना सकते हैं। उदाहरण के लिए, यदि आप अक्सर ग्राहक नाम या फ़ोन नंबर का उपयोग करके किसी ग्राहक की खोज करते हैं, तो आप स्तंभ ग्राहक नाम, साथ ही फ़ोन नंबर पर एक अनुक्रमणिका बनाकर खोज को गति दे सकते हैं। अधिकांश RDBMS प्राथमिक कुंजी पर स्वचालित रूप से एक अनुक्रमणिका बनाता है।