पंडों डेटा विश्लेषण और डेटा तकरार के लिए सबसे लोकप्रिय अजगर पुस्तकालय में से एक है। इस लेख में हम देखेंगे कि कैसे हम एक पांडा डेटाफ़्रेम बना सकते हैं और फिर इस डेटा फ़्रेम से कुछ चुनिंदा पंक्तियों या स्तंभों को हटा सकते हैं।
पंक्तियों को हटाना
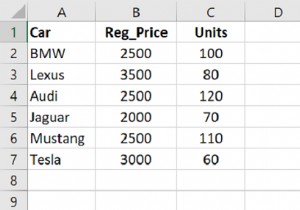
नीचे दिए गए उदाहरण में हमारे पास iris.csv फ़ाइल है जिसे डेटा फ़्रेम में पढ़ा जाता है। हम पहले मौजूदा डेटा फ़्रेम पर एक नज़र डालते हैं और फिर ड्रॉप फ़ंक्शन को इंडेक्स कॉलम पर लागू करते हैं, जिस मूल्य को हम छोड़ना चाहते हैं। जैसा कि हम परिणाम सेट के निचले भाग में देख सकते हैं कि पंक्तियों की संख्या 3 से कम कर दी गई है।
उदाहरण
import pandas as pd
# making data frame from csv file
data = pd.read_csv("E:\\iris1.csv",index_col ="Id")
print(data)
# dropping passed values
data.drop([6,9,10],inplace=True)
# display
print(data) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species Id 1 5.1 3.5 1.4 0.2 Iris-setosa 2 4.9 3.0 1.4 0.2 Iris-setosa 3 4.7 3.2 1.3 0.2 Iris-setosa . .. … .… .…..…… [150 rows x 5 columns] After Dropping SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species Id 1 5.1 3.5 1.4 0.2 Iris-setosa 2 4.9 3.0 1.4 0.2 Iris-setosa 3 4.7 3.2 1.3 0.2 Iris-setosa 149 6.2 3.4 5.4 2.3 Iris-virginica 150 5.9 3.0 5.1 1.8 Iris-virginica …………………. [147 rows x 5 columns]
ड्रॉपिंग कॉलम
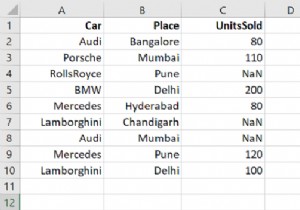
स्तंभों को छोड़ने के लिए एक पांडा डेटा फ्रेम बनाते हैं, हम अक्ष पैरामीटर का उपयोग करते हैं। इसका मान ड्रॉप फ़ंक्शन में एक पर सेट होता है और हम ड्रॉप किए जाने वाले कॉलम नामों की आपूर्ति करते हैं। जैसा कि आप देख सकते हैं कि परिणाम सेट में कॉलम की संख्या 5 से घटकर 3 हो जाती है।
उदाहरण
import pandas as pd
# making data frame from csv file
data = pd.read_csv("E:\\iris1.csv",index_col ="Id")
print(data)
# dropping passed values
data.drop(['SepalWidthCm','PetalLengthCm'],axis=1,inplace=True)
print("After Dropping")
# display
print(data) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species Id 1 5.1 3.5 1.4 0.2 Iris-setosa 2 4.9 3.0 1.4 0.2 Iris-setosa 3 4.7 3.2 1.3 0.2 Iris-setosa . . .… .… .…. .…… [150 rows x 5 columns] After Dropping SepalLengthCm PetalWidthCm Species Id 1 5.1 0.2 Iris-setosa 2 4.9 0.2 Iris-setosa 3 4.7 0.2 Iris-setosa .....…. [150 rows x 3 columns]