हम पांडस डेटाफ़्रेम को ग्रुपबाय () का उपयोग करके समूहित करेंगे। ग्रूपर फ़ंक्शन का उपयोग करके उपयोग किए जाने वाले कॉलम का चयन करें। हम कार बिक्री रिकॉर्ड के लिए नीचे दिखाए गए उदाहरण के लिए दिन-वार समूहबद्ध करेंगे और दिन के अंतराल के साथ पंजीकरण मूल्य की गणना करेंगे।
ग्रुपबाय () ग्रूपर विधि में फ़्रीक्वेंसी को दिनों के अंतराल के रूप में सेट करें, यानी, अगर फ़्रीक 7D है, तो इसका मतलब है कि डेटा को हर महीने के 7 दिनों के अंतराल के अनुसार दिनांक कॉलम में दी गई अंतिम तिथि तक समूहीकृत किया जाएगा।
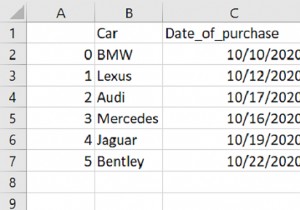
सबसे पहले, मान लें कि तीन स्तंभों के साथ हमारा पंडों का डेटाफ़्रेम निम्नलिखित है -
import pandas as pd
# dataframe with one of the columns as Date_of_Purchase
dataFrame = pd.DataFrame(
{
"Car": ["Audi", "Lexus", "Tesla", "Mercedes", "BMW", "Toyota", "Nissan", "Bentley", "Mustang"],
"Date_of_Purchase": [
pd.Timestamp("2021-06-10"),
pd.Timestamp("2021-07-11"),
pd.Timestamp("2021-06-25"),
pd.Timestamp("2021-06-29"),
pd.Timestamp("2021-03-20"),
pd.Timestamp("2021-01-22"),
pd.Timestamp("2021-01-06"),
pd.Timestamp("2021-01-04"),
pd.Timestamp("2021-05-09")
],
"Reg_Price": [1000, 1400, 1100, 900, 1700, 1800, 1300, 1150, 1350]
}
) इसके बाद, Groupby फ़ंक्शन के अंतर्गत Date_of_Purchase कॉलम का चयन करने के लिए ग्रॉपर का उपयोग करें। फ़्रीक्वेंसी 7D सेट की गई है यानी 7 दिनों के अंतराल को कॉलम में उल्लिखित अंतिम तिथि तक समूहीकृत किया गया है -
print"\nGroup Dataframe by 7 days...\n",dataFrame.groupby(pd.Grouper(key='Date_of_Purchase', axis=0, freq='7D')).sum()
उदाहरण
निम्नलिखित कोड है -
import pandas as pd
# dataframe with one of the columns as Date_of_Purchase
dataFrame = pd.DataFrame(
{
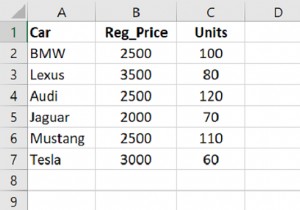
"Car": ["Audi", "Lexus", "Tesla", "Mercedes", "BMW", "Toyota", "Nissan", "Bentley", "Mustang"],
"Date_of_Purchase": [
pd.Timestamp("2021-06-10"),
pd.Timestamp("2021-07-11"),
pd.Timestamp("2021-06-25"),
pd.Timestamp("2021-06-29"),
pd.Timestamp("2021-03-20"),
pd.Timestamp("2021-01-22"),
pd.Timestamp("2021-01-06"),
pd.Timestamp("2021-01-04"),
pd.Timestamp("2021-05-09")
],
"Reg_Price": [1000, 1400, 1100, 900, 1700, 1800, 1300, 1150, 1350]
}
)
print"DataFrame...\n",dataFrame
# Grouper to select Date_of_Purchase column within groupby function
print("\nGroup Dataframe by 7 days...\n",dataFrame.groupby(pd.Grouper(key='Date_of_Purchase', axis=0, freq='7D')).sum()
) आउटपुट
यह निम्नलिखित आउटपुट उत्पन्न करेगा -
DataFrame... Car Date_of_Purchase Reg_Price 0 Audi 2021-06-10 1000 1 Lexus 2021-07-11 1400 2 Tesla 2021-06-25 1100 3 Mercedes 2021-06-29 900 4 BMW 2021-03-20 1700 5 Toyota 2021-01-22 1800 6 Nissan 2021-01-06 1300 7 Bentley 2021-01-04 1150 8 Mustang 2021-05-09 1350 Group Dataframe by 7 days... Reg_Price Date_of_Purchase 2021-01-04 2450.0 2021-01-11 NaN 2021-01-18 1800.0 2021-01-25 NaN 2021-02-01 NaN 2021-02-08 NaN 2021-02-15 NaN 2021-02-22 NaN 2021-03-01 NaN 2021-03-08 NaN 2021-03-15 1700.0 2021-03-22 NaN 2021-03-29 NaN 2021-04-05 NaN 2021-04-12 NaN 2021-04-19 NaN 2021-04-26 NaN 2021-05-03 1350.0 2021-05-10 NaN 2021-05-17 NaN 2021-05-24 NaN 2021-05-31 NaN 2021-06-07 1000.0 2021-06-14 NaN 2021-06-21 1100.0 2021-06-28 900.0 2021-07-05 1400.0