एल्गोरिदम विश्लेषण में हम संचालन और चरणों की गणना करते हैं। यह मूल रूप से उचित है जब कंप्यूटर एक ऑपरेशन करने के लिए उस ऑपरेशन के लिए आवश्यक डेटा लाने के लिए जितना समय लेता है, उससे अधिक समय लेता है। आजकल एक ऑपरेशन करने की लागत मेमोरी से डेटा लाने की लागत से काफी कम है।
कई एल्गोरिदम के रन टाइम में संचालन की संख्या के बजाय मेमोरी संदर्भों की संख्या (कैश मिस की संख्या) का प्रभुत्व होता है। इसलिए, जब हम कुछ एल्गोरिदम तैयार करने की कोशिश करेंगे, तो हमें न केवल संचालन की संख्या को कम करने पर ध्यान केंद्रित करना होगा, बल्कि मेमोरी एक्सेस की संख्या को भी कम करना होगा। मेमोरी लेटेंसी को छिपाने वाले एल्गोरिदम को डिजाइन करने पर भी ध्यान देना होगा।
मान लीजिए कि एक साधारण कंप्यूटर मॉडल है जिसमें कंप्यूटर की मेमोरी में L1 कैश, L2 कैश और मुख्य मेमोरी होती है। हम रजिस्टरों में निवासी डेटा पर ALU का उपयोग करके कुछ अंकगणित और तार्किक संचालन करते हैं (R)
यह इसका ब्लॉक डायग्राम है -
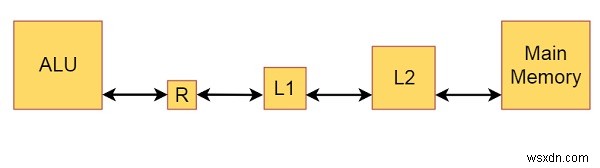
आरेख से हम मेमोरी और कैश के आकार के बारे में भी कुछ जानकारी प्राप्त कर सकते हैं। मुख्य मेमोरी मूल रूप से सैकड़ों या हजारों एमबी की होती है। जहाँ L2 कैश MB का कुछ अंश है और L1 कैश कुछ KB है। रजिस्टर का आकार कुछ बिट्स है। जब हम किसी प्रोग्राम को निष्पादित करते हैं, तो सारा डेटा मेमोरी में होता है। अगर हम ADD जैसे कुछ ऑपरेशन जोड़ते हैं, तो पहले नंबर को रजिस्टर में स्टोर किया जाएगा, रजिस्टरों में डेटा जोड़ा जाता है, फिर परिणाम मेमोरी में लिखा जाता है।
एक चक्र को उस समय की लंबाई होने दें, जिसमें पहले से ही रजिस्टरों में मौजूद डेटा को जोड़ने की आवश्यकता होगी। L1 कैश से डेटा को एक रजिस्टर में लोड करने के लिए समय की आवश्यकता होती है, मान लीजिए कि इस मॉडल में दो चक्र हैं। यदि आवश्यक डेटा L1 कैश में नहीं है, लेकिन L2 कैश में मौजूद है, तो हमें L1 कैश मिस मिलता है और आवश्यक डेटा L2 कैश से L1 कैश में ले जाया जाता है और 10 चक्रों में रजिस्टर होता है। जब हमारा आवश्यक डेटा L2 कैश में भी नहीं होता है, तो हमारे पास L2 कैश मिस होता है और आवश्यक डेटा मुख्य मेमोरी से L2 कैश, L1 कैश और रजिस्टर में 100 चक्रों में ले जाया जाएगा। फिर डेटा को मुख्य मेमोरी में लिखे जाने पर भी राइट ऑपरेशन को एक चक्र के रूप में गिना जाता है, क्योंकि हम अगले ऑपरेशन पर आगे बढ़ने से पहले पूर्ण लेखन की प्रतीक्षा नहीं करते हैं