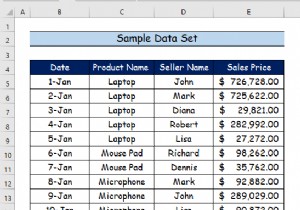
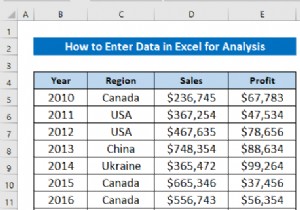
डेटा विश्लेषण टूलपैक एक्सेल की सबसे अच्छी विशेषताओं में से एक है जब हमें उन्नत सांख्यिकीय विश्लेषण करने की आवश्यकता होती है। यदि आप एक्सेल में डेटा विश्लेषण टूलपैक का उपयोग करने के लिए कुछ विशेष तरकीबों की तलाश कर रहे हैं, तो आप सही जगह पर आए हैं। एक्सेल में डेटा विश्लेषण टूलपैक का उपयोग करने के कई तरीके हैं। यह आलेख एक्सेल डेटा विश्लेषण टूलपैक का उपयोग करने के तेरह उपयुक्त उदाहरणों पर चर्चा करेगा। आइए यह सब जानने के लिए पूरी गाइड का पालन करें।
Excel में डेटा विश्लेषण टूलपैक सक्षम करने के चरण
एक्सेल डेटा विश्लेषण टूलपैक की सभी विशेषताओं का विश्लेषण करने से पहले, हमें यह दिखाना होगा कि इस टूलपैक को कैसे स्थापित किया जाए। यहां हम प्रदर्शित करने जा रहे हैं कि डेटा विश्लेषण टूलपैक . को कैसे सक्षम किया जाए एक्सेल में। ऐसा करने के लिए आपको निम्नलिखित प्रक्रिया का पालन करना होगा।
📌 चरण:
- सबसे पहले, विकल्प पर जाएं फ़ाइल . से ।
- फिर, ऐड-इन्स . पर जाएं ।
- यहां, एक्सेल ऐड-इन्स का चयन करें प्रबंधित करें . में ड्रॉप-डाउन मेनू।
- और जाओ . पर क्लिक करें ।
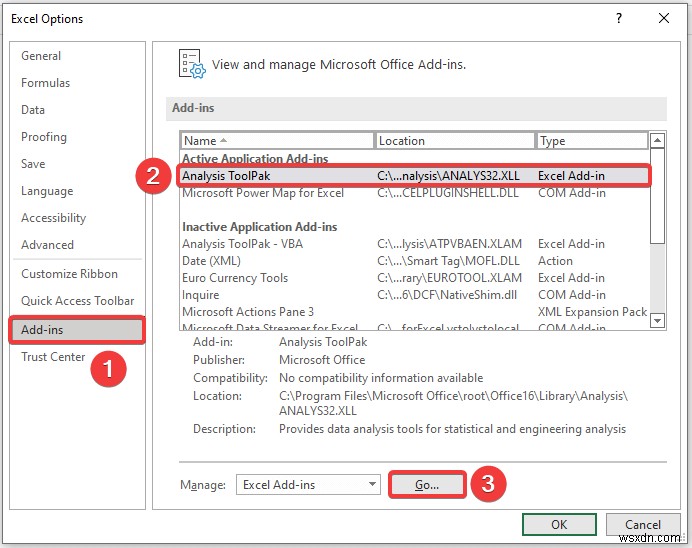
- फिर, एक नई विंडो दिखाई देगी।
- यहां, चिह्नित करें विकल्प विश्लेषण टूलपैक। और ठीक . पर क्लिक करें . इस प्रकार आप एक्सेल डेटा विश्लेषण टूलपैक को सक्रिय करने में सक्षम होंगे।
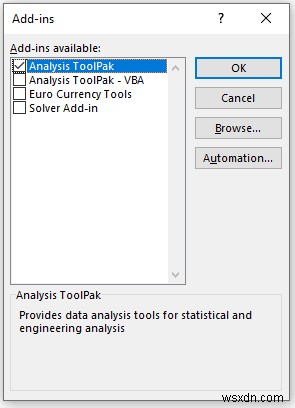
- अब, विश्लेषण . पर जाएं डेटा . में मेनू टैब। यहां आपको डेटा विश्लेषण . मिलेगा विकल्प।
13 डेटा विश्लेषण टूलपैक की अद्भुत विशेषताएं जिनका आप एक्सेल में उपयोग कर सकते हैं
हम एक्सेल में डेटा विश्लेषण टूलपैक का उपयोग करने के लिए तेरह प्रभावी और पेचीदा तरीकों का उपयोग करेंगे। यहां, हम एक्सेल डेटा विश्लेषण टूलपैक की तेरह विशेषताओं को प्रदर्शित करेंगे। यह खंड तेरह तरीकों पर विस्तृत विवरण प्रदान करता है। आप अपने उद्देश्य के लिए किसी एक का उपयोग कर सकते हैं, जब अनुकूलन की बात आती है तो उनके पास लचीलेपन की एक विस्तृत श्रृंखला होती है। आपको इन सभी को सीखना और लागू करना चाहिए, क्योंकि ये आपकी सोचने की क्षमता और एक्सेल ज्ञान में सुधार करते हैं। हम Microsoft Office 365 . का उपयोग करते हैं संस्करण यहाँ है, लेकिन आप अपनी पसंद के अनुसार किसी अन्य संस्करण का उपयोग कर सकते हैं।
<एच3>1. अनोवा विश्लेषणअनोवा यह निर्धारित करने का पहला अवसर प्रदान करता है कि डेटा के दिए गए सेट पर कौन से कारक महत्वपूर्ण प्रभाव डालते हैं। विश्लेषण पूरा होने के बाद, एक विश्लेषक पद्धतिगत कारकों . पर अतिरिक्त विश्लेषण करता है जो डेटा सेट की असंगत प्रकृति को महत्वपूर्ण रूप से प्रभावित करते हैं। और वह f-परीक्षण . में Anova विश्लेषण के निष्कर्षों का उपयोग करता है अनुमानित प्रतिगमन विश्लेषण . के लिए प्रासंगिक अतिरिक्त डेटा बनाने के लिए . एनोवा विश्लेषण यह देखने के लिए एक साथ कई डेटा सेट की तुलना करता है कि उनके बीच कोई लिंक है या नहीं। एनोवा एक सांख्यिकीय पद्धति है जिसका उपयोग डेटासेट के भीतर देखे गए विचरण को दो वर्गों में विभाजित करके विश्लेषण करने के लिए किया जाता है:1) व्यवस्थित कारक और 2) यादृच्छिक कारक
अनोवा का सूत्र:
F=MSE / MST
यहां:
एफ =अनोवा गुणांक
एमएसटी =उपचार के कारण वर्गों का औसत योग
एमएसई =त्रुटि के कारण वर्गों का औसत योग
अनोवा दो प्रकार का होता है:एकल कारक और दो कारक। विधि विचरण विश्लेषण से संबंधित है।
- दो कारकों में, कई आश्रित चर होते हैं और एक कारक में, एक आश्रित चर होगा।
- एकल कारक अनोवा एक चर पर एक कारक के प्रभाव की गणना करता है। और यह जांचता है कि सभी नमूना डेटा सेट समान हैं या नहीं।
- एकल-कारक अनोवा उन अंतरों की पहचान करता है जो अनेक चरों के औसत साधनों के बीच सांख्यिकीय रूप से महत्वपूर्ण हैं।
1.1 सिंगल फैक्टर एनोवा विश्लेषण
यहां, हम प्रदर्शित करेंगे कि एकल कारक अनोवा विश्लेषण कैसे किया जाता है। आइए पहले हम आपको हमारे एक्सेल डेटासेट से परिचित कराते हैं ताकि आप समझ सकें कि हम इस लेख के साथ क्या हासिल करने की कोशिश कर रहे हैं। हमारे पास कारकों का समूह दिखाने वाला डेटासेट है। आइए एकल कारक एनोवा विश्लेषण करने के चरणों के माध्यम से चलते हैं।
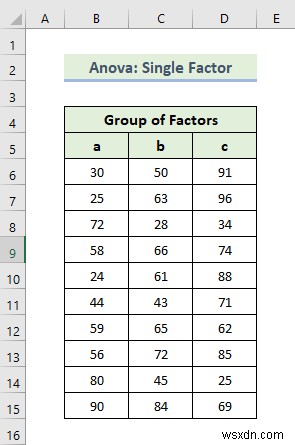
📌 चरण:
- सबसे पहले, डेटा पर जाएं शीर्ष रिबन में टैब।
- फिर, डेटा विश्लेषण . चुनें उपकरण।
- जब डेटा विश्लेषण विंडो प्रकट होती है, अनोवा:सिंगल फ़ैक्टर . चुनें विकल्प।
- फिर, ठीक . पर क्लिक करें ।
<मजबूत> 
- अब, अनोवा:सिंगल फैक्टर विंडो खुलेगी।
- इनपुट रेंज में डेटा प्रदान करें बॉक्स, जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर एनोवा विश्लेषण निर्धारित करना चाहते हैं।
- जांचें पहली पंक्ति में लेबल . नाम का बॉक्स ।
- आउटपुट रेंज . में बॉक्स में, वह डेटा श्रेणी प्रदान करें जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर अपने परिकलित डेटा को संग्रहीत करना चाहते हैं। या आप नई वर्कशीट प्लाई . का चयन करके नई वर्कशीट में आउटपुट दिखा सकते हैं और आप नई कार्यपुस्तिका . का चयन करके नई कार्यपुस्तिका में आउटपुट भी देख सकते हैं ।
- अगला, आपको पहली पंक्ति में लेबल . की जांच करनी होगी यदि आप लेबल के साथ इनपुट डेटा श्रेणी का चयन करते हैं।
- फिर, ठीक . पर क्लिक करें ।
<मजबूत> 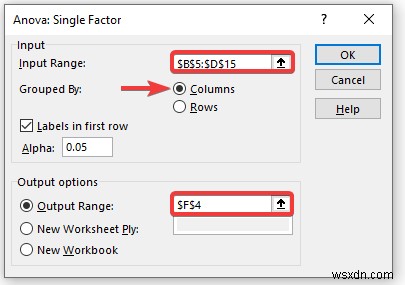
- परिणामस्वरूप, एनोवा के परिणाम नीचे दिखाए गए अनुसार होंगे।
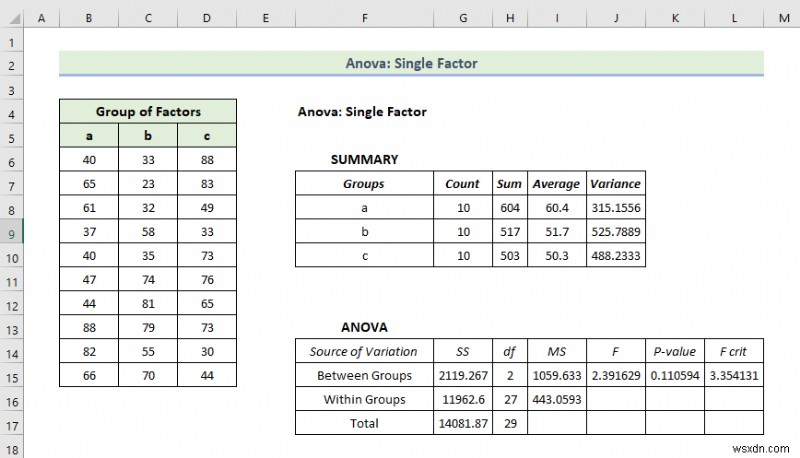
परिणाम की व्याख्या:
- सारांश तालिका में, आप प्रत्येक समूह का औसत और प्रसरण पाएंगे। यहां आप औसत . देख सकते हैं स्तर 60.4 . है समूह a . के लिए लेकिन भिन्नता 315.15 . है जो अन्य समूहों की तुलना में बहुत कम है। इसका मतलब है कि समूह में सदस्य कम मूल्यवान हैं।
- यहां, अनोवा के परिणाम इतने महत्वपूर्ण नहीं हैं क्योंकि आप केवल वेरिएंस की गणना कर रहे हैं।
- यहाँ, P-मान स्तंभों के बीच संबंध की व्याख्या करते हैं और मान 0.05 से अधिक हैं इसलिए यह सांख्यिकीय रूप से महत्वपूर्ण नहीं है। और कॉलम के बीच भी कोई संबंध नहीं होना चाहिए।
1.2 अनोवा:प्रतिकृति के साथ दो कारक
यहां, हम प्रतिकृति एनोवा विश्लेषण के साथ दो-कारक प्रदर्शित करने जा रहे हैं। मान लीजिए कि आपके पास किसी स्कूल के विभिन्न परीक्षा अंकों के बारे में कुछ आंकड़े हैं। उस स्कूल में दो शिफ्ट होती हैं। एक सुबह की शिफ्ट के लिए है तो दूसरी दिन की शिफ्ट के लिए। आप दो पाली के छात्रों के अंकों के बीच संबंध खोजने के लिए तैयार डेटा का डेटा विश्लेषण करना चाहते हैं। आइए प्रतिकृति विश्लेषण के साथ दो-कारक एनोवा करने के चरणों के माध्यम से चलते हैं।
📌 चरण:
- सबसे पहले, डेटा पर जाएं शीर्ष रिबन में टैब।
- फिर, डेटा विश्लेषण . चुनें उपकरण।
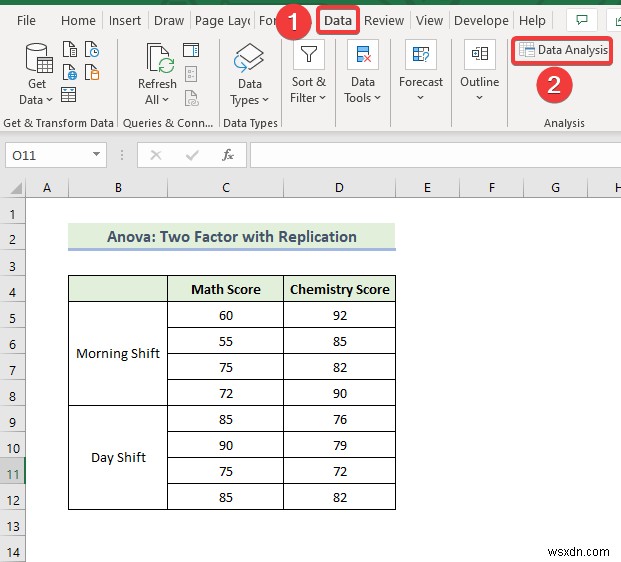
- जब डेटा विश्लेषण विंडो प्रकट होती है, अनोवा:प्रतिकृति के साथ दो-कारक . चुनें विकल्प।
- फिर, ठीक . पर क्लिक करें ।
<मजबूत> 
- अब, एक नई विंडो दिखाई देगा।
- डेटा को इनपुट रेंज में प्रदान करें बॉक्स, जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर एनोवा विश्लेषण निर्धारित करना चाहते हैं।
- अगला, प्रति नमूना पंक्तियों में 4 इनपुट करें बॉक्स जैसा आपके पास है 4 प्रति पारी पंक्तियाँ।
- आउटपुट रेंज . में बॉक्स में, वह डेटा श्रेणी प्रदान करें जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर अपने परिकलित डेटा को संग्रहीत करना चाहते हैं। या आप नई वर्कशीट प्लाई . का चयन करके नई वर्कशीट में आउटपुट दिखा सकते हैं और आप नई कार्यपुस्तिका . का चयन करके नई कार्यपुस्तिका में आउटपुट भी देख सकते हैं ।
- फिर, ठीक . पर क्लिक करें ।
<मजबूत> 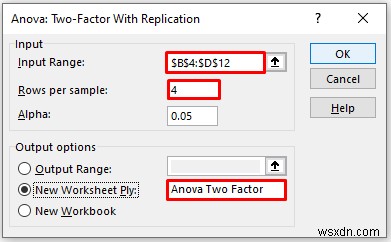
- परिणामस्वरूप, आप एक नई वर्कशीट तैयार होते देखेंगे।
- और, दोतरफा अनोवा परिणाम इस वर्कशीट में दिखाया गया है।
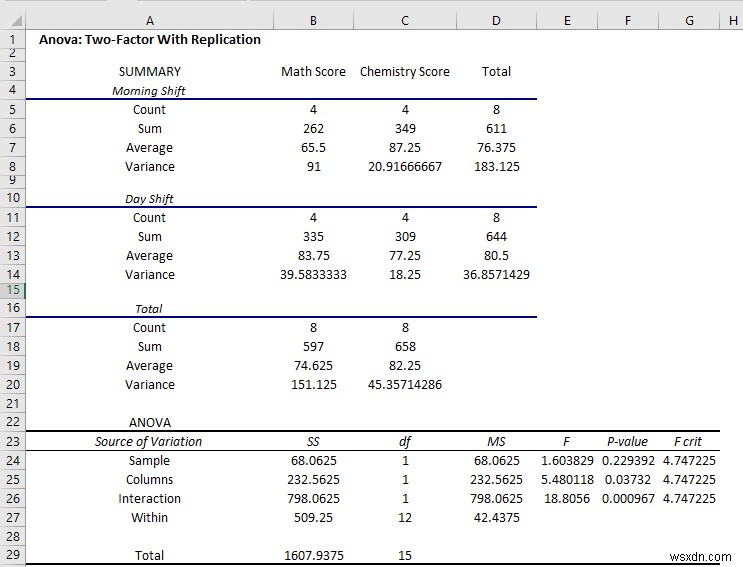
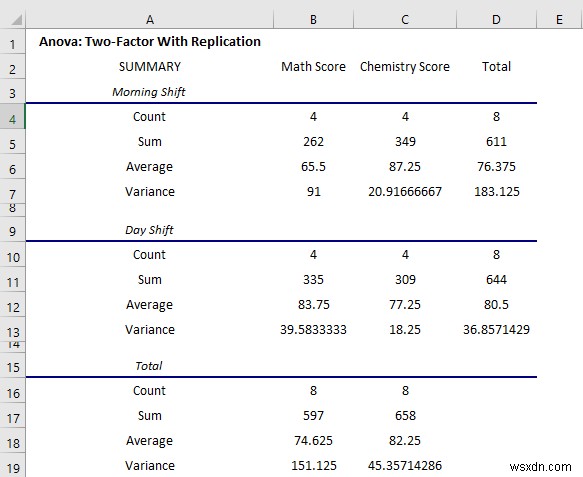
परिणाम की व्याख्या:
यहां, पहले टेबल, शिफ्ट का सारांश दिखा रहे हैं। संक्षेप में:
- सुबह का औसत स्कोर गणित के स्कोर में बदलाव है 65.5 लेकिन दिन . में शिफ्ट 83.75 . है
- लेकिन जब रसायन विज्ञान की परीक्षा में, सुबह . में औसत अंक शिफ्ट है 87.25, लेकिन दिन . में शिफ्ट है 77.25 ।
- वेरिएंस सुबह . में 91 पर बहुत अधिक है गणित की परीक्षा में बदलाव.
- आपको सारांश में डेटा का पूरा अवलोकन मिलेगा।
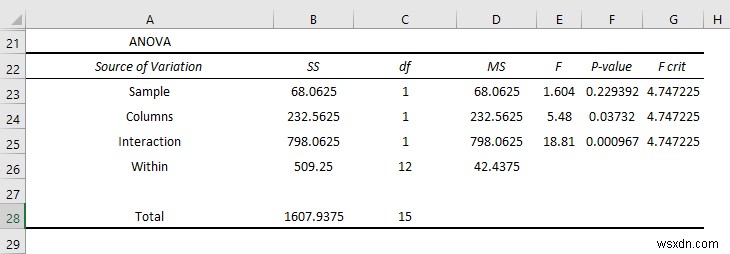
इसी तरह, आप अनोवा भाग में बातचीत और व्यक्तिगत प्रभावों को संक्षेप में बता सकते हैं। संक्षेप में:
- द पी-मान कॉलम . में से 0 . है .037 जो सांख्यिकीय रूप से महत्वपूर्ण है इसलिए आप कह सकते हैं कि परीक्षा में छात्रों के प्रदर्शन पर बदलाव का प्रभाव पड़ता है। लेकिन मान करीब . है 0.05 का अल्फा मान इसलिए प्रभाव कम महत्वपूर्ण . है ।
- लेकिन इंटरैक्शन का P-मान है 0.000967 जो अल्फ़ा मान से बहुत कम है इसलिए यह सांख्यिकीय रूप से महत्वपूर्ण . है और आप कह सकते हैं कि दोनों परीक्षाओं पर शिफ्ट का प्रभाव बहुत अधिक है।
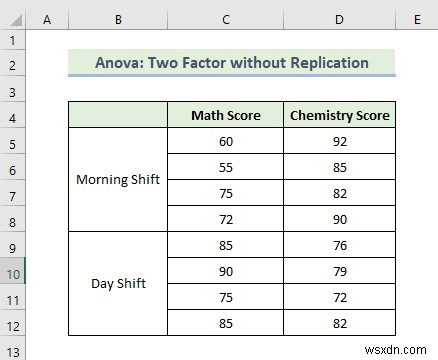
1.3 अनोवा:बिना प्रतिकृति के दो कारक
अब, हम एनोवा विश्लेषण की प्रतिकृति के बिना दो कारकों की विधि का पालन करके विचरण विश्लेषण करने जा रहे हैं। हम मान लेते हैं कि आपके पास एक स्कूल के विभिन्न परीक्षा अंकों के बारे में कुछ आंकड़े हैं। उस स्कूल में दो शिफ्ट होती हैं। एक सुबह की शिफ्ट के लिए है तो दूसरी दिन की शिफ्ट के लिए। आप दो पाली के छात्रों के अंकों के बीच संबंध खोजने के लिए तैयार डेटा का डेटा विश्लेषण करना चाहते हैं। आइए प्रतिकृति विश्लेषण के बिना दो कारक एनोवा को डॉट करने के चरणों के माध्यम से चलते हैं।
📌 चरण:
- सबसे पहले, डेटा पर जाएं शीर्ष रिबन में टैब।
- फिर, डेटा विश्लेषण . चुनें उपकरण।
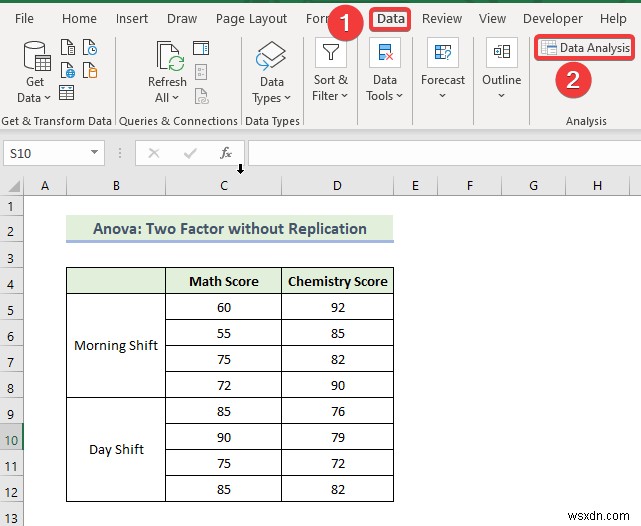
- जब डेटा विश्लेषण विंडो प्रकट होती है, "अनोवा:प्रतिकृति के बिना दो-कारक . चुनें "विकल्प।
- फिर, ठीक . पर क्लिक करें ।
<मजबूत> 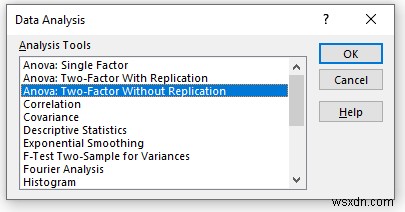
- अब, एक नई विंडो दिखाई देगा।
- डेटा को इनपुट रेंज में प्रदान करें बॉक्स, जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर एनोवा विश्लेषण निर्धारित करना चाहते हैं।
- आउटपुट रेंज . में बॉक्स में, वह डेटा श्रेणी प्रदान करें जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर अपने परिकलित डेटा को संग्रहीत करना चाहते हैं। या आप नई वर्कशीट प्लाई . का चयन करके नई वर्कशीट में आउटपुट दिखा सकते हैं और आप नई कार्यपुस्तिका . का चयन करके नई कार्यपुस्तिका में आउटपुट भी देख सकते हैं ।
- अगला, आपको लेबल . की जांच करनी होगी यदि इनपुट डेटा लेबल के साथ है।
- फिर, ठीक . पर क्लिक करें ।
- परिणामस्वरूप, आप एक नई वर्कशीट तैयार होते देखेंगे।
- परिणामस्वरूप, आपको दोतरफा एनोवा परिणाम मिलेगा जैसा कि नीचे दिखाया गया है।
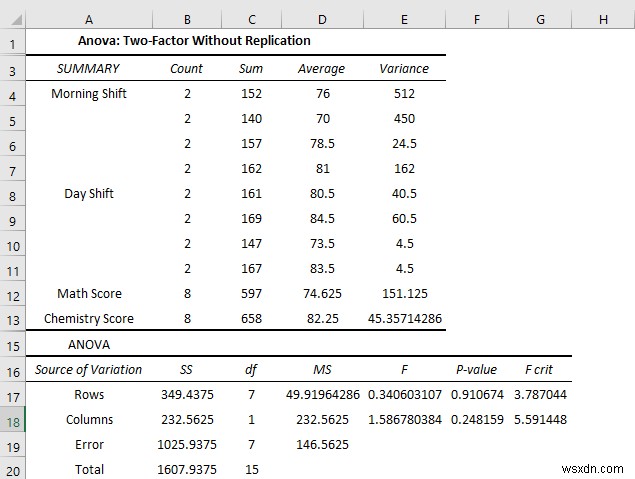
परिणाम की व्याख्या:
- सुबह का औसत स्कोर गणित के स्कोर में बदलाव 65 . है .5 लेकिन दिन . में शिफ्ट 83.75 . है
- लेकिन जब रसायन विज्ञान की परीक्षा में, सुबह . में औसत अंक शिफ्ट है 87 लेकिन दिन . में शिफ्ट 77.25. . है
- द पी-मान कॉलम . में से है 0.24 जो सांख्यिकीय रूप से महत्वपूर्ण है इसलिए आप कह सकते हैं कि परीक्षा में छात्रों के प्रदर्शन पर बदलाव का प्रभाव पड़ता है। लेकिन मान करीब . है 0.05 का अल्फा मान इसलिए प्रभाव कम महत्वपूर्ण . है ।
और पढ़ें: एक्सेल में डेटा विश्लेषण कैसे जोड़ें (2 त्वरित चरणों के साथ)
<एच3>2. सहसंबंध विश्लेषणअब, हम एक सहसंबंध डेटा विश्लेषण करने जा रहे हैं जो एक्सेल डेटा विश्लेषण टूलपैक की एक बड़ी विशेषता है। आँकड़ों में, सहसंबंध या सहसंबंध गुणांक दूसरे की निरंतर उतार-चढ़ाव वाली मात्रा के जवाब में दो चर के बीच सुसंगतता दिखाने के लिए पैरामीटर है। इसका मान -1 . के बीच होता है करने के लिए +1 . इसलिए, इसमें परिवर्तनशील संबंधों को परिभाषित करने की तीन अवस्थाएँ हैं। वे हैं:
- -1 एक नकारात्मक सहसंबंध दर्शाता है जिसका अर्थ है कि चर विपरीत दिशा में बदलते हैं।
- +1 एक सकारात्मक सहसंबंध दर्शाता है जिसका अर्थ है कि चर एक ही दिशा में बदलते हैं।
- 0 कोई सहसंबंध नहीं दर्शाता है जिसका अर्थ है कि अन्य चरों के मूल्यों को बदलने पर एक चर की किसी भी दिशा में कोई स्पष्ट गति नहीं है।
यहां, हमारे पास एक डेटासेट है जिसमें अलग-अलग समय अवधि में दो स्टॉक मूल्य हैं। आइए सहसंबंध डेटा विश्लेषण करने के चरणों के माध्यम से चलते हैं।
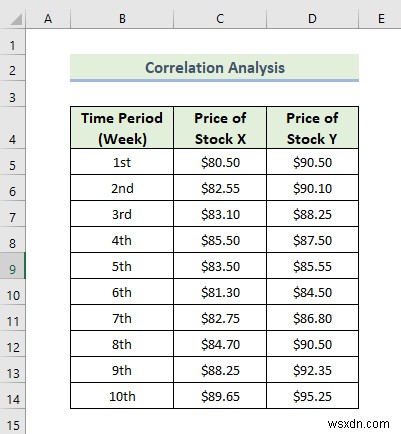
📌 चरण:
- सबसे पहले, डेटा पर जाएं शीर्ष रिबन में टैब।
- फिर, डेटा विश्लेषण . चुनें उपकरण।
- जब डेटा विश्लेषण विंडो प्रकट होती है, सहसंबंध . चुनें विकल्प।
- अगला, ठीक पर क्लिक करें ।
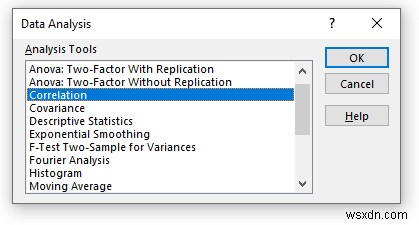
- अब, एक नई विंडो दिखाई देगा।
- डेटा को इनपुट रेंज में प्रदान करें बॉक्स, जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर सहसंबंध की गणना करना चाहते हैं।
- अब, आपको कॉलम की जांच करनी होगी द्वारा समूहीकृत . में विकल्प विकल्प।
- आउटपुट रेंज . में बॉक्स में, वह डेटा श्रेणी प्रदान करें जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर अपने परिकलित डेटा को संग्रहीत करना चाहते हैं। या आप नई वर्कशीट प्लाई . का चयन करके नई वर्कशीट में आउटपुट दिखा सकते हैं और आप नई कार्यपुस्तिका . का चयन करके नई कार्यपुस्तिका में आउटपुट भी देख सकते हैं ।
- अगला, आपको पहली पंक्ति में लेबल . की जांच करनी होगी यदि इनपुट डेटा लेबल के साथ है।
- फिर, ठीक . पर क्लिक करें ।
- परिणामस्वरूप, आपको निम्नलिखित सहसंबंध परिणाम प्राप्त होंगे।
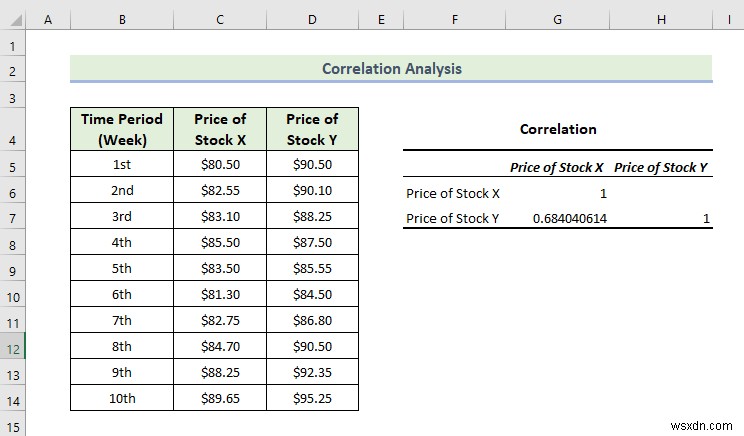
उपरोक्त गणना से, हम एक सकारात्मक सहसंबंध देख सकते हैं जिसका अर्थ है कि चर एक ही दिशा में बदलते हैं।
और पढ़ें: एक्सेल में टाइम सीरीज डेटा का विश्लेषण कैसे करें (आसान चरणों के साथ)
<एच3>3. सहप्रसरण विश्लेषणअब, हम सहप्रसरण डेटा विश्लेषण करने जा रहे हैं जो एक्सेल डेटा विश्लेषण टूलपैक की एक बड़ी विशेषता है। दो चरों का सहप्रसरण इस बात का माप है कि उनमें से एक दूसरे को कैसे प्रभावित करता है। स्पष्ट रूप से, यह दो चरों के बीच विचलन का एक आवश्यक मूल्यांकन है। इसके अलावा, चर, एक दूसरे पर निर्भर होने की जरूरत नहीं है। आइए सहप्रसरण डेटा विश्लेषण करने के चरणों के माध्यम से चलते हैं।
📌 चरण:
- सबसे पहले, डेटा पर जाएं शीर्ष रिबन में टैब।
- फिर, डेटा विश्लेषण . चुनें उपकरण।
- जब डेटा विश्लेषण विंडो प्रकट होती है, सहप्रसरण . चुनें विकल्प।
- फिर, दर्ज करें press दबाएं ।
- फिर, ठीक . पर क्लिक करें ।
- अब, एक नई विंडो दिखाई देगा।
- डेटा को इनपुट रेंज में प्रदान करें बॉक्स, जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर सहप्रसरण की गणना करना चाहते हैं।
- अब, आपको कॉलम की जांच करनी होगी द्वारा समूहीकृत . में विकल्प अनुभाग।
- आउटपुट रेंज . में बॉक्स में, वह डेटा श्रेणी प्रदान करें जिसे आप कॉलम या पंक्ति के माध्यम से खींचकर अपने परिकलित डेटा को संग्रहीत करना चाहते हैं। या आप नई वर्कशीट प्लाई . का चयन करके नई वर्कशीट में आउटपुट दिखा सकते हैं और आप नई कार्यपुस्तिका . का चयन करके नई कार्यपुस्तिका में आउटपुट भी देख सकते हैं ।
- अगला, आपको पहली पंक्ति में लेबल . की जांच करनी होगी यदि इनपुट डेटा लेबल के साथ है।
- फिर, ठीक . पर क्लिक करें ।
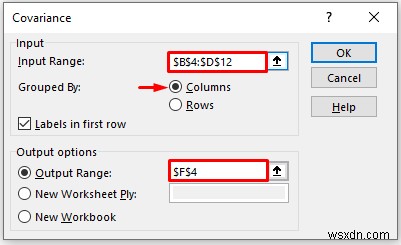
- परिणामस्वरूप, आपको निम्नलिखित सहप्रसरण परिणाम प्राप्त होंगे।
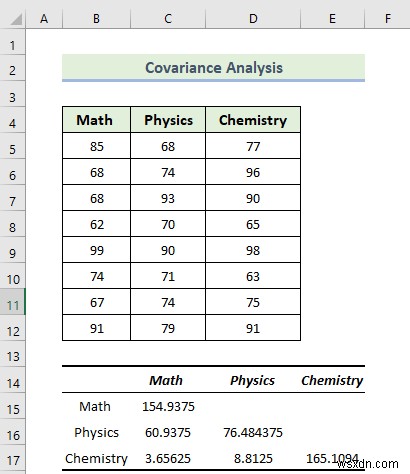
परिणाम की व्याख्या:
सहसंबंध मैट्रिक्स हमें कई चर और एकल चर के बीच संबंधों का आकलन करने की अनुमति देता है। निम्न छवि से हाइलाइट अनुभाग प्रत्येक विषय के लिए भिन्नता को इंगित करता है।
- गणित का विचरण 154.9375 है और भौतिकी का प्रसरण 76.484375 है . इसके बाद, रसायन विज्ञान का प्रसरण 154.9375 है।
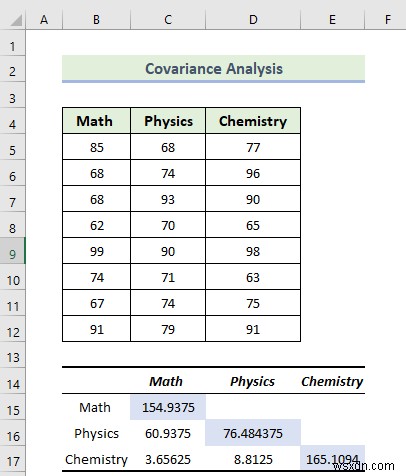
निम्न छवि से हाइलाइट अनुभाग दो विषयों के बीच भिन्नता के मूल्यों को इंगित करता है। गणित और भौतिकी, गणित और रसायन विज्ञान, और भौतिकी और इतिहास का विचरण मान क्रमशः 60.9375 है , 3.65625, और 8.8125. जब सहप्रसरण, इस मामले में, धनात्मक होता है, तो यह इंगित करता है कि चर समानुपाती हैं, जिसका अर्थ है कि जब एक बढ़ता है, तो दूसरा उसके साथ ऊपर उठता है।
और पढ़ें: [फिक्स्ड:] डेटा विश्लेषण एक्सेल में नहीं दिख रहा है (2 प्रभावी समाधान)
<एच3>4. वर्णनात्मक सांख्यिकी विश्लेषणअब, हम यह प्रदर्शित करने जा रहे हैं कि वर्णनात्मक सांख्यिकी विश्लेषण कैसे किया जाता है। एक्सेल डेटा विश्लेषण टूलपैक हमें इसकी विशेषताओं को निर्धारित करने के लिए डेटासेट का विश्लेषण करने के लिए एक वर्णनात्मक सांख्यिकी विश्लेषण करने की अनुमति देता है। यहां, हमारे पास एक डेटासेट है जिसमें प्रत्येक छात्र के लिए भौतिकी स्कोर है। आइए सहसंबंध डेटा विश्लेषण करने के चरणों के माध्यम से चलते हैं।
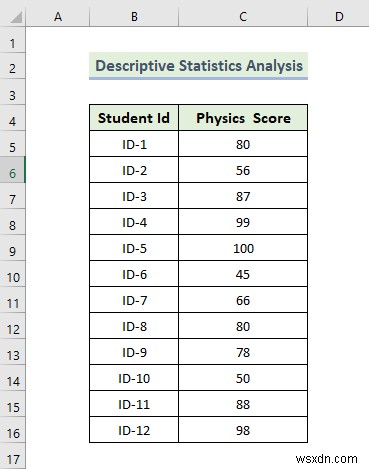
📌 चरण:
- सबसे पहले, डेटा पर जाएं tab in the top ribbon.
- Then, select the Data Analysis tool.
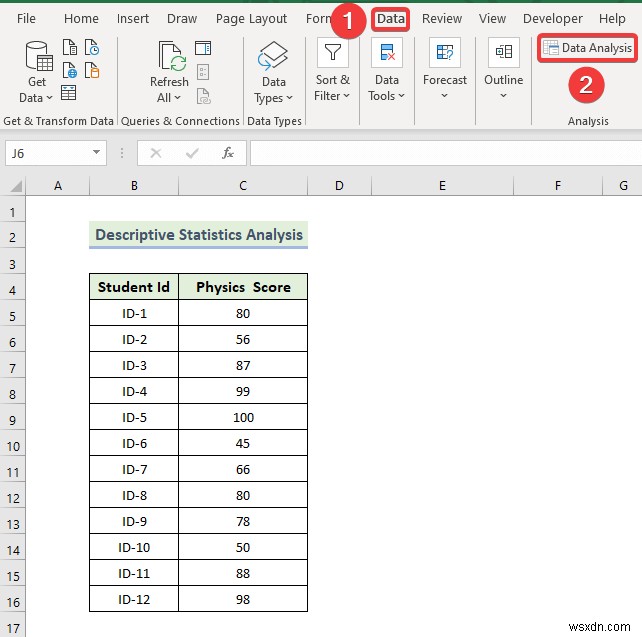
- When the Data Analysis window appears, select the Descriptive Statistics विकल्प।
- Then, click on OK ।
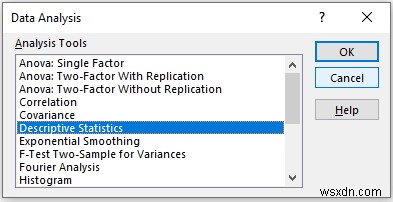
- Now, a new window दिखाई देगा।
- Provide data in the Input Range box, that you want to calculate the descriptive statistics by dragging through the column or row.
- Now, you have to check the Columns option in the Grouped By अनुभाग।
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Then, check the Summary statistics ।
- Then, click on OK ।
- As a consequence, you will get the following covariance result.
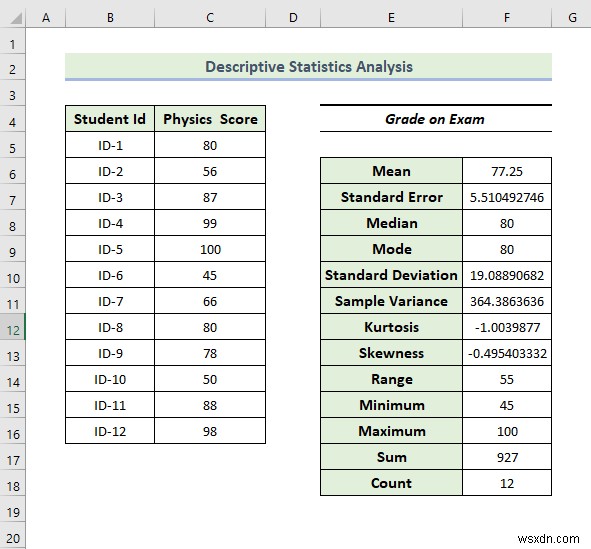
- The above result gives us the characteristics of two variables, i.e. mean, median, standard deviation, and maximum and minimum value of the dataset, which are respectively 77.25, 80, 19.088, 45, and 100.
और पढ़ें: How to Use Analyze Data in Excel (5 Easy Methods)
5. Exponential Smoothing Analysis
Now, we are going to demonstrate how to do an exponential smoothing analysis. The Excel data analysis toolpak allows us to do exponential smoothing in order to make appropriate decisions regarding business volume. Here, we have a dataset containing a number of items sold in different weeks by a manufacturing company. Let’s walk through the steps to do an exponential smoothing data analysis.
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the Exponential Smoothing option.
- Then, click on OK ।
- Now, a new window दिखाई देगा।
- Provide data in the Input Range box, that you want to calculate the exponential smoothing by dragging through the column or row.
- Now, you have to enter 0.9 in the Damping factor डिब्बा। Here, we damping 1-alpha
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels if the input data range with the label.
- Then, check the Chat Output ।
- Then, click on OK ।
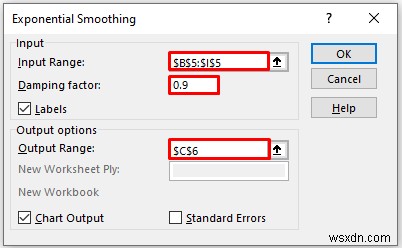
- As a consequence, you will get the following exponential smoothing result and chart for 0.1 alpha.
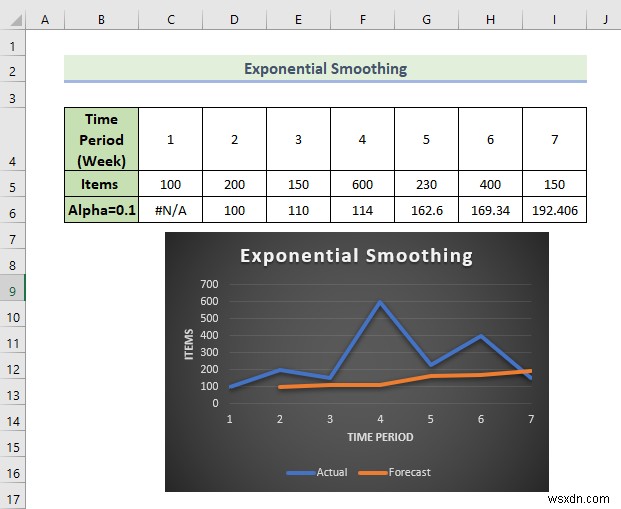
Here, from the above result, we can say that Excel can not provide data for the first value in this method. If we use a large damping factor, we will get more smooth peaks and valleys.
<एच3>6. F-Test Two-Sample for Variances AnalysisNow, we are going to do an F-test for two sample variances. Using the variance of two variables, the F-test provides statistical analysis in Excel. Here, we have a dataset containing two items’ sales prices in different weeks by a manufacturing company. Let’s walk through the steps to do an f-test for two sample variances.
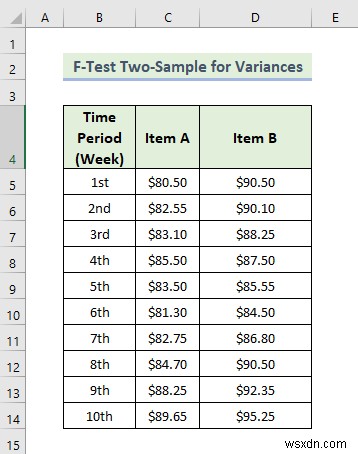
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the F-Test Two-Sample for Variances विकल्प।
- Then, click on OK ।
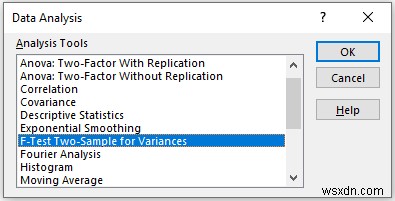
- Now, a new window दिखाई देगा।
- Provide data in the Input Range box, that you want to calculate the F-test by dragging through the column or row.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels if the input data range with the label.
- Then, click on OK ।
- As a consequence, you will get the following result of an F-test for two sample variances.
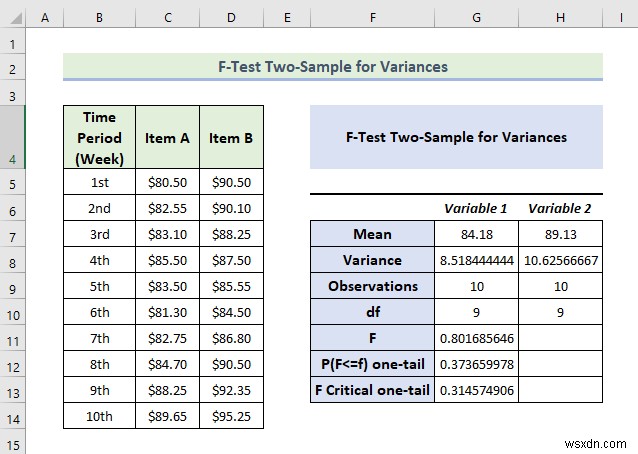
Explanation of the Result:
- From the above data, we can see that the mean value of variable 2 is greater than variable 1.
- We also know that if the value F is greater than F Critical one-tail value, in this case, we can say it doesn’t follow null hypothesis. In the above data, the value of F is .8016 and the value of F Critical one-tail is 0.3145 which indicates F is much greater than F critical one-tail. In other words, the variances between two variables don’t match.
Now, we are going to do a moving average analysis which is one of the best features of Excel data analysis toolpak.. The moving average means the time period of the average is the same but it keeps moving when new data is added. Am moving average smooths out any irregularities (peaks and valleys) from data to easily recognize trends. The larger the interval period is to calculate the moving average, the more fluctuations smoothing occurs. As more data points are included in each calculated average. Here, we have a dataset containing a number of items sold in different weeks by a manufacturing company. Let’s walk through the steps to do a moving average analysis.
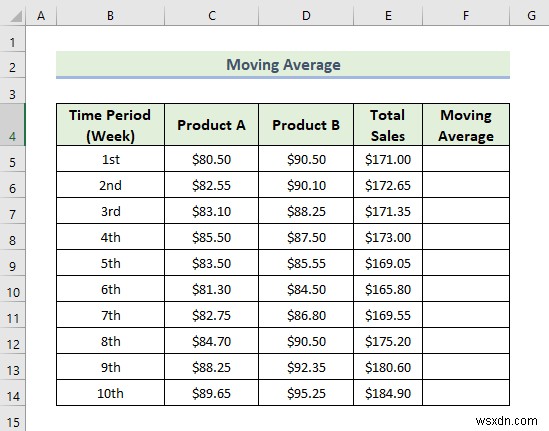
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the Moving Average विकल्प।
- Then, click on OK ।
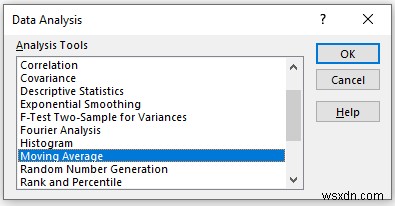
In the Moving Average pop-up box,
- Provide data in the Input Range box, that you want to calculate the moving average by dragging through the column or row.
- Write the number of intervals the Interval ।
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- If you want to see the trendline of your data with a chart then check the Chart Output otherwise leave it.
- Next, you have to check the Labels in the first row if the input data range with the label.
- Then, click on OK ।
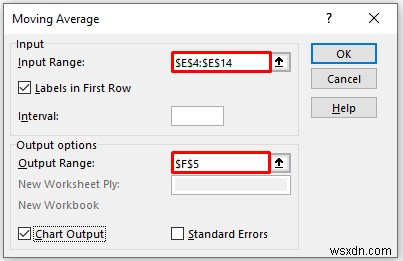
- As a consequence, you will get the moving average of the data along with an Excel trendline showing both the original data and the moving average value with smoothed fluctuations.
समान रीडिंग
- How to Analyze Quantitative Data in Excel (with Easy Steps)
- Analyze Large Data Sets in Excel (6 Effective Methods)
- एक्सेल में लिकर्ट स्केल डेटा का विश्लेषण कैसे करें (त्वरित चरणों के साथ)
- Excel में प्रश्नावली से गुणात्मक डेटा का विश्लेषण करें
8. Random Number Generation
Now, we are going to generate a random number. The Excel data analysis toolpak allows us to generate random numbers with different criteria. Let’s walk through the steps to do a moving average analysis.
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the Descriptive Statistics विकल्प।
- Then, click on OK ।
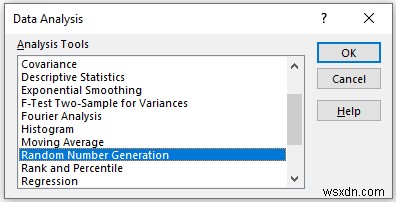
In the Random Number Generation pop-up box,
- Provide data on the Number of Variables which indicates the number of columns of random numbers that you want in your worksheet. Here, we enter 2 as we want 2 columns.
- Next, you have to provide data in the Number of Random Numbers which refers to the number of rows that you want in your worksheet. Here, enter 7 which means we want 7 rows in our worksheet.
- Then, select the uniform in the Distribution Here, Distribution means which kinds of distribution of random numbers you want.
- Here, parameters indicate the boundaries of your distribution. In this example, we 40 to 60.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Then, click on OK ।
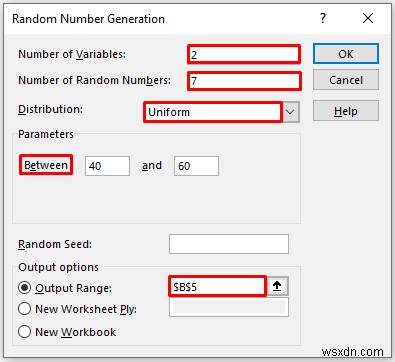
- As a consequence, you will be able to generate random numbers with some specified criteria as shown below.
9. Rank and Percentile Analysis
Now, we are going to do rank and percentile analysis. Here, we have a dataset containing students’ ID and their Math exam scores. We are going to calculate the rank and percentile of each student’s math exam score. Let’s walk through the steps to do rank and percentile analysis.
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the Rank and Percentile विकल्प।
- Then, click on OK ।
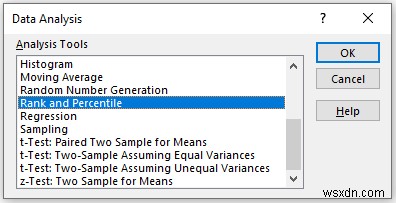
In the Rank and Percentile pop-up box,
- Provide data in the Input Range box, that you want to calculate the moving average by dragging through the column or row.
- Now, you have to check the Columns option in the Grouped By अनुभाग।
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels in the first row if the input data range with the label.
- Then, click on OK ।
- As a consequence, you will get the rank and percentile for each student’s exam score as shown below.
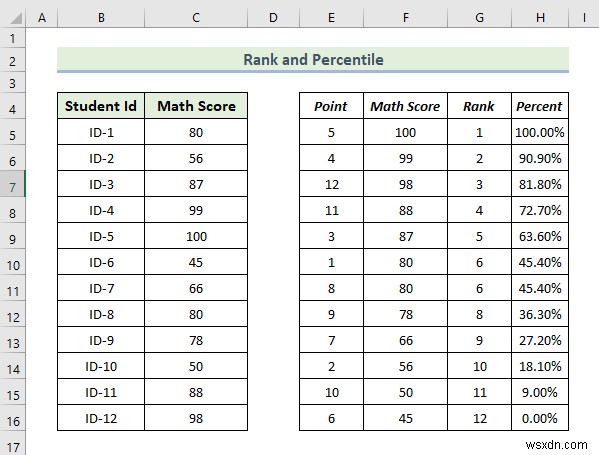
From the above result, we can see that we are able to calculate the rank and percentile of each student’s mark. Here, the Rank 1 mark is 100 which is ID-5’s math score, and the last rank mark is 45 which is ID-6’s math score.
<एच3>10. Regression AnalysisNow, we are going to do regression analysis. Regression analysis is a part of statistics that helps to predict values depending on two or more variables. Here, we have a dataset containing the player name, the number of matches played by each player, and the number of goals given by each player. Let’s walk through the steps to do regression analysis.
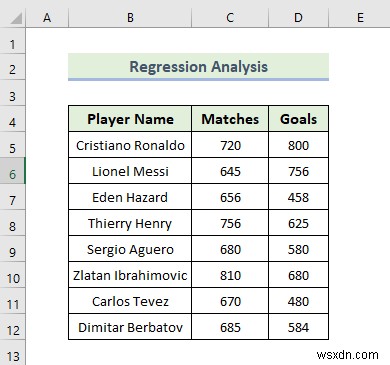
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
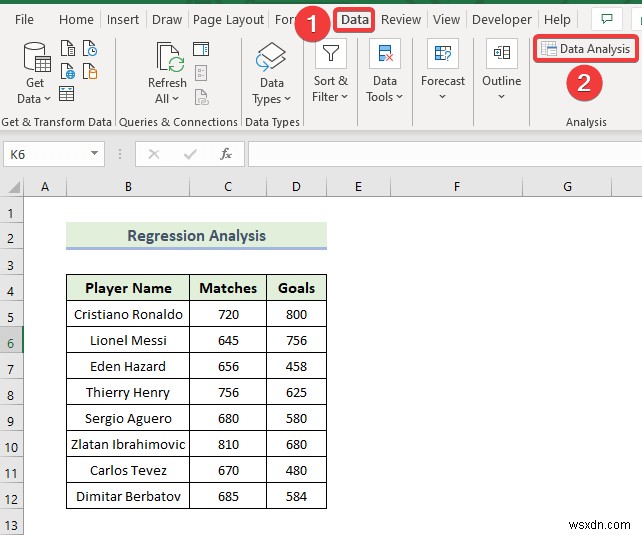
- When the Data Analysis window appears, select the Regression विकल्प।
- Then, click on OK ।
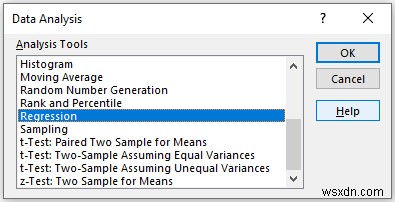
In the Regression pop-up box,
- Provide data in the Input Range box, and provide the data ranges in the Input X Range and Input Y Range boxes.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels if the input data range with the label.
- You also have to check the Residuals option to get the output value.
- Then, click on OK ।
- As a consequence, you will get the following result of the regression analysis.
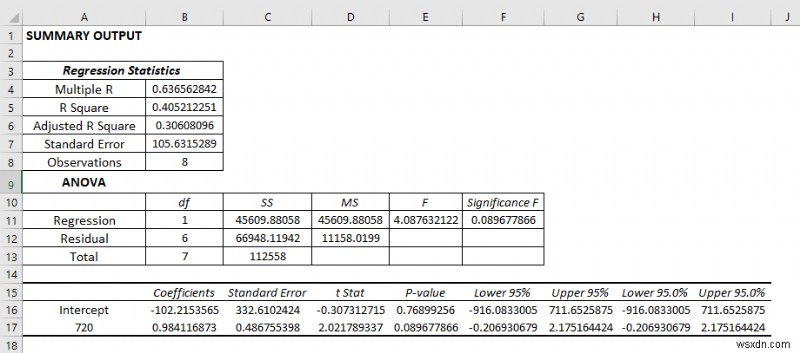
Explanation of the Regression Analysis Result:
Regression Statistics:
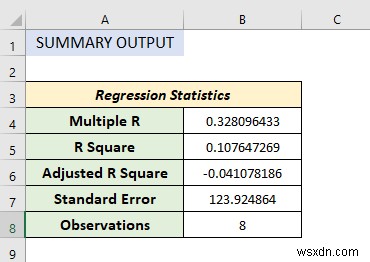
Regression statistics is an array of various parameters that describe how well the measured linear regression is.
- Multiple R is a correlation coefficient parameter that indicates the correlation between variables. Its value ranges from -1 to +1. The bigger the value, the stronger the correlative relationships are.
- R Square symbolizes the coefficient of determination. It indicates the scale by how well the data model fits the regression analysis.
- The adjusted R square is used in multiple variables in regression analysis.
- Standard Error is another parameter that shows a healthy fit of any regression analysis. The smaller the standard error the more accurate the linear regression equation. It shows the average distance of data points from the linear equation.
Anova:
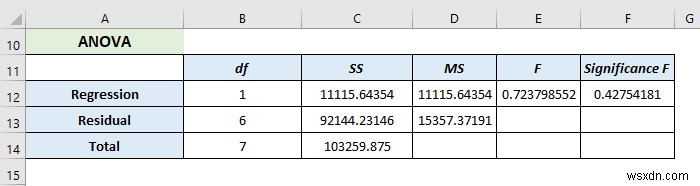
It analyses the variance of the data model.
- Here, df represents the degree of freedom.
- SS( sum of squares) symbolizes the good-to-fit parameter.
- MS means the Mean Square.
- F refers to the Null Hypothesis. It tests the overall significance of the regression model
- Significance of F means the P-value of F.
Co-efficient Outcome:
<मजबूत> 
It helps to determine Y values easily.
Residual Output:
<मजबूत> 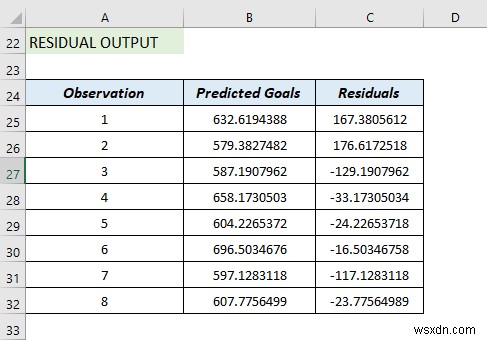
So, it compares the estimated value with the calculated value.
11. t-Test Analysis
Now, we are going to do a T-Test analysis of the dataset. The T-Test is of three types:
- Paired two samples for means
- Two samples assuming equal variances
- Two- samples using unequal variances
This section provides extensive details on the three types of t-Test analysis. You can use either one for your purpose, they have a wide range of flexibility when it comes to customization.
11.1 t-Test:Paired Two Sample for Means
Now, we are going to do a t-Test:Paired Two Sample for Means. Here, we have a dataset containing the Students’ IDs and each student’s Math and Physics scores. Let’s walk through the steps to do a t-Test:Paired Two Sample for Means analysis.
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the t-Test:Paired Two Samples for Means विकल्प।
- Then, click on OK ।
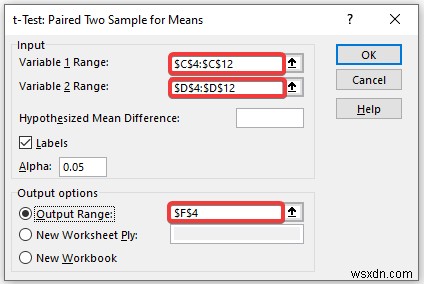
In the t-Test:Paired Two Sample for Means pop-up box,
- Provide data in the Input box, and provide the data ranges in the Variable 1 Range and Variable 2 Range boxes.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels if the input data range with the label.
- Then, click on OK ।
- As a consequence, you will get the following result of the t-Test:Paired Two Sample for Means ।
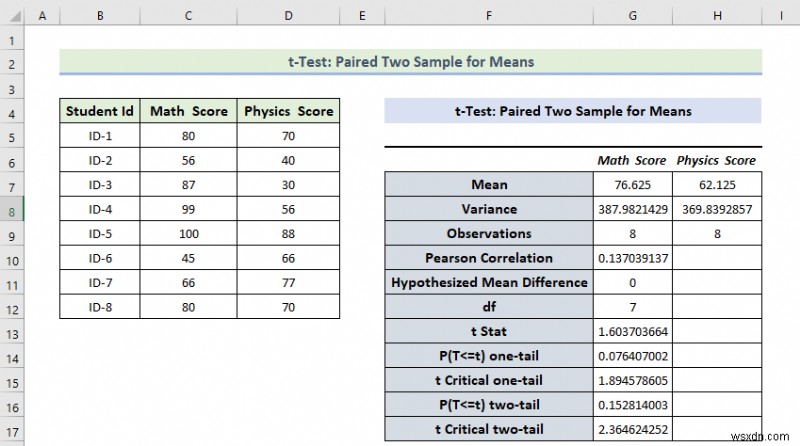
Explanation of the Result:
- Here, we can see that the Mean Value of the Math Score is greater than the mean value of the Physics Score.
- The variance of the Math Score is also greater than the variance of the Physics Score.
- If t Stat is greater than t Critical two-tail, in this condition we can’t eliminate null hypothesis. In the above calculation, we can see that t Stat is and t Critical two-tail value is respectively 1.603 and 2.36464 . That means 1.603<2.36464 , it doesn’t match the null hypothesis. In other words, the variances between two variables don’t match.
11.2 t-Test Two-Sample Assuming Equal Variances
Now, we are going to do a t-Test:Two-Sample Equal Variances . Here, we have a dataset containing the Students’ IDs and each student’s Math and Physics scores. Here, equal variance means that we have taken our data from regular distribution populations. Let’s walk through the steps to do a t-Test:Two-Sample Equal Variances analysis.
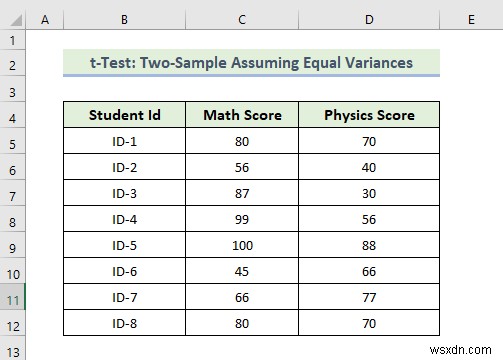
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
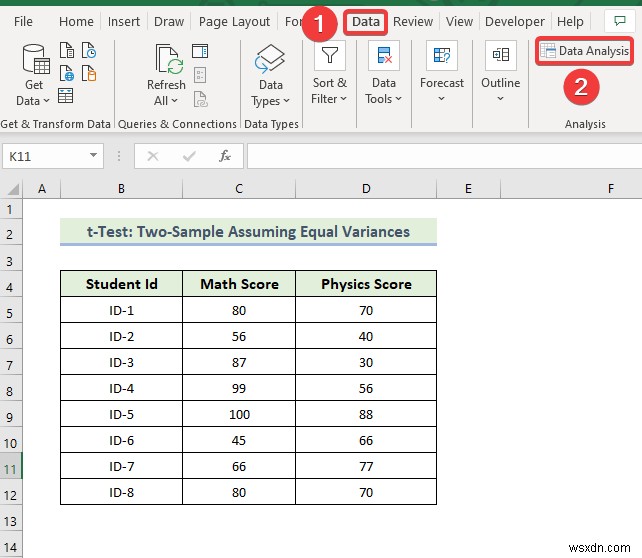
- When the Data Analysis window appears, select the t-Test:Two-Sample Equal Variances विकल्प।
- Then, click on OK ।
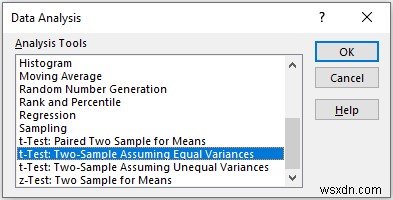
In the t-Test:Paired Two Sample Equal Variances pop-up box,
- Provide data in the Input box, and provide the data ranges in the Variable 1 Range and Variable 2 Range boxes.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels if the input data range with the label.
- Then, click on OK ।
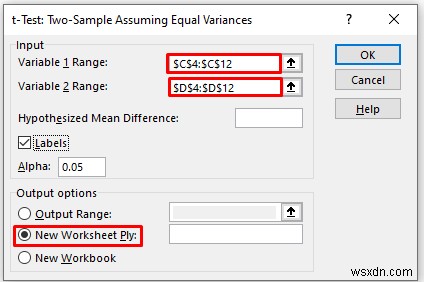
- As a consequence, you will get the following result of the t-Test:Two-Sample Equal Variances ।
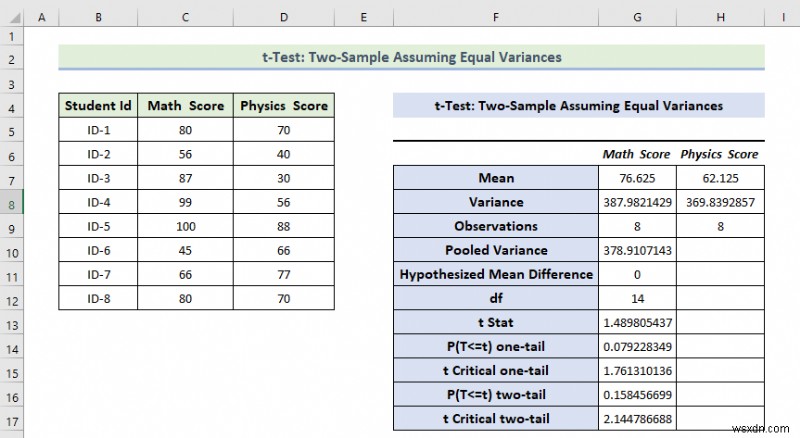
Explanation of the Result:
- Here, we can see that the Mean Value of the Math Score is greater than the mean value of the Physics Score.
- The variance of the Math Score is also greater than the variance of the Physics Score.
- If t Stat is greater than t Critical two-tail, in this condition we can’t eliminate the null hypothesis. In the above calculation, we can see that t Stat is and t Critical two-tail value is respectively 1.48 and 2.144 . That means 1.48<2.144 , it doesn’t match the null hypothesis. In other words, the variances between two variables don’t match.
11.3 t-Test:Two-Sample Assuming Unequal Variances
Now, we are going to do a t-Test:Two-Sample Unequal Variances. Here, we have a dataset containing the Students’ IDs and each student’s Math and Physics scores. Here, unequal variance means that we have taken our data from irregular distribution populations. Let’s walk through the steps to do a t-Test:Two-Sample Unequal Variances analysis.
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the t-Test:Two-Sample Unequal Variances विकल्प।
- Then, click on OK ।
In the t-Test:Paired Two Sample Unequal Variances pop-up box,
- Provide data in the Input box, and provide the data ranges in the Variable 1 Range and Variable 2 Range boxes.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- Next, you have to check the Labels if the input data range with the label.
- Then, click on OK ।
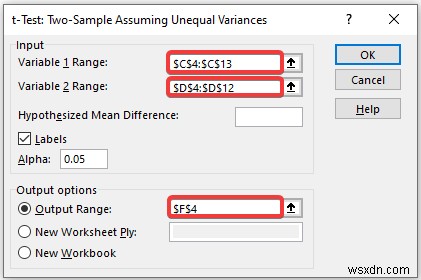
- As a consequence, you will get the following result of the t-Test:Two-Sample Unequal Variances.
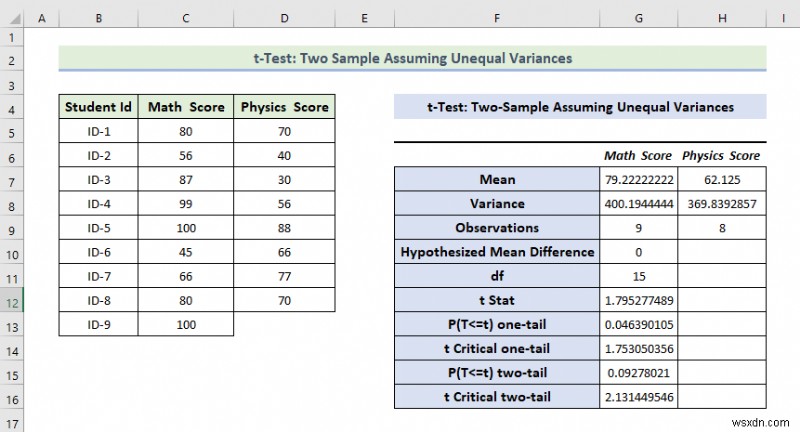
Explanation of the Result:
- Here, we can see that the Mean Value of the Math Score is greater than the mean value of the Physics Score.
- From the above result, we can see the variance of the Math Score is also greater than the variance of the Physics Score.
- If t Stat is greater than t Critical two-tail, in this condition we can’t eliminate null hypothesis. In the above calculation, we can see that t Stat is and t Critical two-tail value is respectively 79 and 2.131 . That means 1.79<2.131 , it doesn’t match the null hypothesis. In other words, the variances between two variables don’t match.
12. z-Test:Two Sample for Means
Now, we are going to do a z-Test:Two-Sample Means. Here, we have a dataset containing the Students’ IDs and each student’s Math and Physics scores. Here we will use the VAR.P function to calculate the variance of both variables of the following dataset. Let’s walk through the steps to do a z-Test:Two-Sample Means analysis.
📌 चरण:
- First of all, to calculate the variance of the Math score, we will use the following formula in the cell D14:
=VAR.P(C5:C12)
- फिर, दर्ज करें press दबाएं ।
- As a consequence, you will get the following variance of Match Score.
<मजबूत> 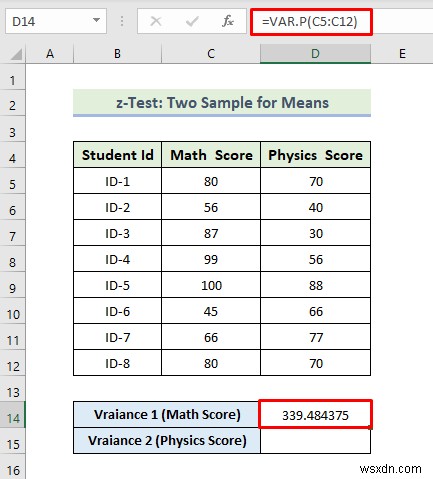
- Next, to calculate the variance of the Physics score, we will use the following formula in the cell D15:
=VAR.P(D5:D12)
- फिर, दर्ज करें press दबाएं ।
- As a consequence, you will get the following variance of Physics Score.
<मजबूत> 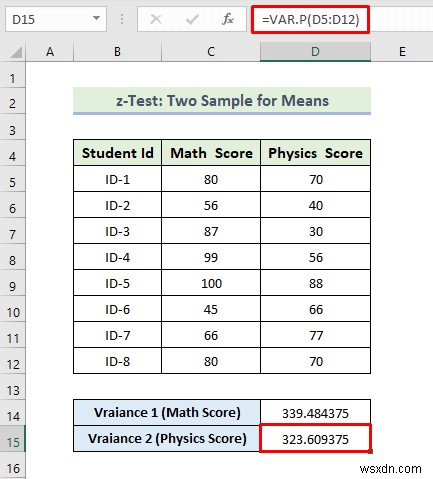
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the z-Test:Two-Sample Means विकल्प।
- Then, click on OK ।
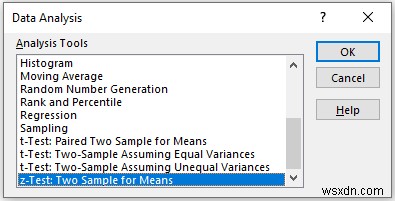
In the z-Test:Two-Sample Means pop-up box,
- Provide data in the Input box, and provide the data ranges in the Variable 1 Range and Variable 2 Range boxes.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- You have to enter the value variance of Math and Physics Score respectively in the Variable 1 Variance (known) and Variable 2 Variance (known)
- Next, you have to check the Labels if the input data range with the label.
- Then, click on OK ।
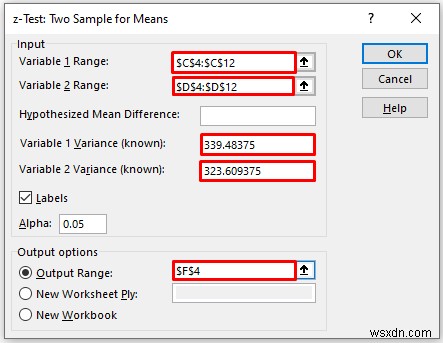
- As a consequence, you will get the following result of the z-Test:Two-Sample Means विकल्प।
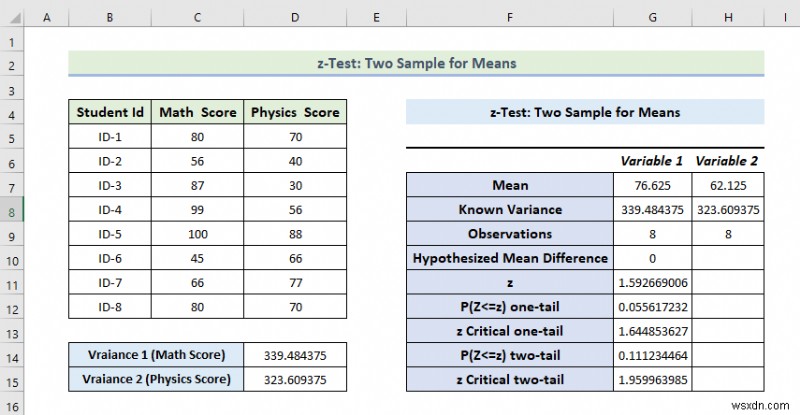
Explanation of the Result:
- Here, we can see that the Mean Value of the Math Score is greater than the mean value of the Physics Score.
- From the above result, we can see the variance of the Math Score is also greater than the variance of the Physics Score.
- If Z is less than Z critical two-tall, in this condition we can’t eliminate null hypothesis. In the above calculation, we can see that z and z Critical two-tail value is respectively 52 and 1.95 . That means 1.52 <1.95 , which matches the null hypothesis. In other words, the variances between two variables match.
और पढ़ें: How to Perform Case Study Using Excel Data Analysis
13. Sampling Analysis
Now, we are going to do a sampling analysis which is one of the best features of the Excel data analysis toolpak. Here, we have a dataset containing two items individual sales and total sales value for different time periods. Let’s walk through the steps to do sampling analysis.
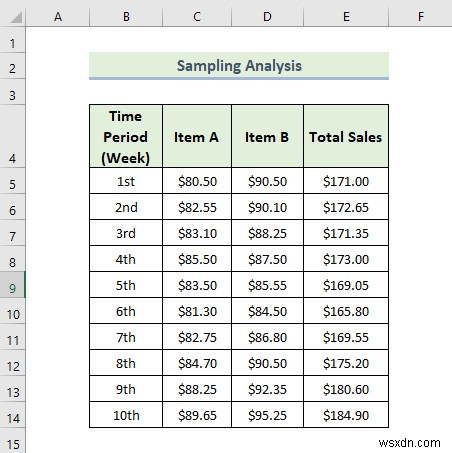
📌 चरण:
- First, go to the Data tab in the top ribbon.
- Then, select the Data Analysis tool.
- When the Data Analysis window appears, select the Sampling विकल्प।
- Then, click on OK ।
In the Sampling pop-up box,
- Provide data in the Input Range box, that you want to calculate the moving average by dragging through the column or row.
- In the Output Range box, provide the data range that you want your calculated data to store by dragging through the column or row. Or you can show the output in the new worksheet by selecting New Worksheet Ply and you can also see the output in the new workbook by selecting New Workbook ।
- You have to enter data in the Number of Samples विकल्प।
- Next, you have to check the Labels if the input data range with the label.
- Then, click on OK ।
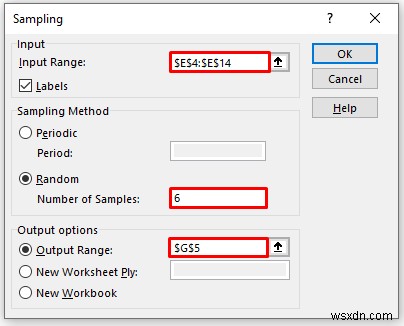
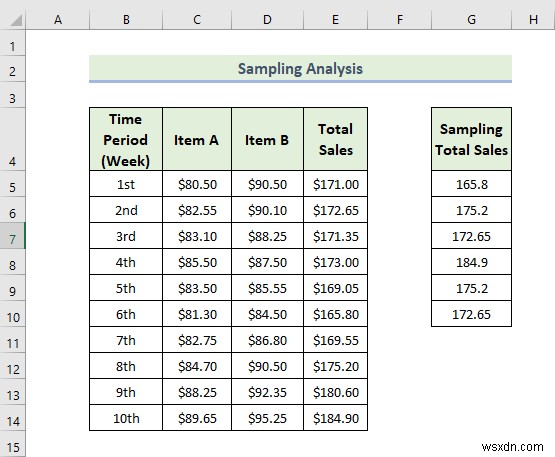
- As a consequence, you will get the following result of the Sampling विश्लेषण। In the following picture, we are able to pick up six samples from the Total Sales कॉलम। If you want to pick up more sample data from this column, you have to enter more numbers in the Number of Samples box when the Sampling विंडो प्रकट होती है।
और पढ़ें: How to Analyze Sales Data in Excel (10 Easy Ways)
निष्कर्ष
यह आज के सत्र का अंत है। Here, we demonstrate thirteen suitable examples to use the data analysis toolpak. I strongly believe that from now, you may be able to use data analysis toolpak in Excel. यदि आपके कोई प्रश्न या सुझाव हैं, तो कृपया उन्हें नीचे टिप्पणी अनुभाग में साझा करें।
हमारी वेबसाइट को देखना न भूलें Exceldemy.com एक्सेल से संबंधित विभिन्न समस्याओं और समाधानों के लिए। नए तरीके सीखते रहें और बढ़ते रहें!
संबंधित लेख
- पिवट टेबल (9 उपयुक्त उदाहरण) का उपयोग करके एक्सेल में डेटा का विश्लेषण कैसे करें
- एक्सेल में समय के हिसाब से डेटा का विश्लेषण करें (आसान चरणों के साथ)
- एक्सेल में गुणात्मक डेटा का विश्लेषण कैसे करें (आसान चरणों के साथ)
- Analyze qPCR Data in Excel (2 Easy Methods)
- Excel में टेक्स्ट डेटा का विश्लेषण कैसे करें (5 उपयुक्त तरीके)