इस खंड में हम बहुआयामी सरणियों का एक और प्रतिनिधित्व देखेंगे। यहां हम Arrays के प्रतिनिधित्व का Array देखेंगे। इस रूप में, हमारे पास एक सरणी है, जो कई सरणियों के शुरुआती पते रखती है। प्रतिनिधित्व इस तरह दिखेगा।
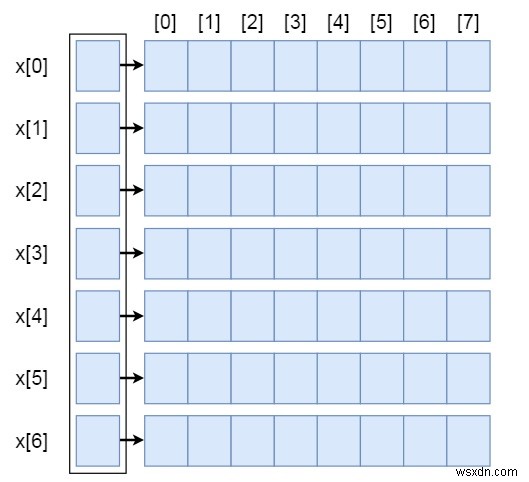
यह एक द्वि-आयामी सरणी x आकार [7 x 8] है। प्रत्येक पंक्ति को एकल एकआयामी सरणी के रूप में दर्शाया जाता है। प्रारंभिक सरणी इन एकल सरणियों के पते धारण कर रही है। वे पतों की सरणी हैं, इसलिए हम कह सकते हैं कि, यह पॉइंटर्स की एक सरणी है। प्रत्येक सूचक दूसरे सरणियों के पते धारण कर रहा है।
इस प्रकार की सरणी बनाएं, हम नीचे दिए गए जैसे नए कीवर्ड का उपयोग कर सकते हैं -
int [][] x = new int[7][8];
स्थिति x[i, j] पर मौजूद तत्व को पुनः प्राप्त करने के लिए, यह पहले x[i] का उपयोग करके पता ढूंढेगा, फिर उस सरणी में jth अनुक्रमणिका में चला जाएगा।


