पांडा डेटा साइंस और एनालिटिक्स के लिए सबसे लोकप्रिय पायथन लाइब्रेरी में से एक है। पांडा पुस्तकालय का उपयोग डेटा हेरफेर, विश्लेषण और सफाई के लिए किया जाता है। यह निम्न-स्तरीय NumPy पर एक उच्च-स्तरीय अमूर्त है जो विशुद्ध रूप से C में लिखा गया है। इस खंड में, हम कुछ सबसे महत्वपूर्ण (अक्सर उपयोग की जाने वाली) चीजों को शामिल करेंगे जिन्हें हमें एक विश्लेषक या डेटा वैज्ञानिक के रूप में जानना आवश्यक है।
लाइब्रेरी स्थापित करना
हम पाइप का उपयोग करके आवश्यक पुस्तकालय स्थापित कर सकते हैं, बस अपने कमांड टर्मिनल पर कमांड के नीचे चलाएँ:
pip intall pandas
डेटाफ़्रेम और सीरीज़
सबसे पहले हमें पंडों की दो मुख्य बुनियादी डेटा संरचना को समझने की जरूरत है। डेटाफ़्रेम और श्रृंखला। पंडों में महारत हासिल करने के लिए हमें इन दो डेटा संरचना की ठोस समझ होनी चाहिए।
श्रृंखला
सीरीज एक ऐसी वस्तु है जो पाइथन बिल्ट-इन टाइप लिस्ट के समान है लेकिन इससे अलग है क्योंकि इसमें प्रत्येक तत्व या इंडेक्स के साथ जुड़ा हुआ है।
>>> import pandas as pd >>> my_series = pd.Series([12, 24, 36, 48, 60, 72, 84]) >>> my_series 0 12 1 24 2 36 3 48 4 60 5 72 6 84 dtype: int64
उपरोक्त आउटपुट में, 'इंडेक्स' बाईं ओर है और 'वैल्यू' दाईं ओर है। साथ ही प्रत्येक सीरीज ऑब्जेक्ट में डेटा प्रकार (dtype) होता है, हमारे मामले में यह int64 होता है।
हम तत्वों को उनकी अनुक्रमणिका संख्या द्वारा पुनः प्राप्त कर सकते हैं:
>>> my_series[6] 84
अनुक्रमणिका (लेबल) की व्याख्या प्रदान करने के लिए, उपयोग करें:
>>> my_series = pd.Series([12, 24, 36, 48, 60, 72, 84], index =['ind0', 'ind1', 'ind2', 'ind3', 'ind4', 'ind5', 'ind6']) >>> my_series ind0 12 ind1 24 ind2 36 ind3 48 ind4 60 ind5 72 ind6 84 dtype: int64
साथ ही कई तत्वों को उनकी अनुक्रमणिका द्वारा पुनर्प्राप्त करना या समूह असाइनमेंट करना बहुत आसान है:
>>> my_series[['ind0', 'ind3', 'ind6']] ind0 12 ind3 48 ind6 84 dtype: int64 >>> my_series[['ind0', 'ind3', 'ind6']] = 36 >>> my_series ind0 36 ind1 24 ind2 36 ind3 36 ind4 60 ind5 72 ind6 36 dtype: int64
फ़िल्टरिंग और गणित संचालन भी आसान हैं:
>>> my_series[my_series>24] ind0 36 ind2 36 ind3 36 ind4 60 ind5 72 ind6 36 dtype: int64 >>> my_series[my_series < 24] * 2 Series([], dtype: int64) >>> my_series ind0 36 ind1 24 ind2 36 ind3 36 ind4 60 ind5 72 ind6 36 dtype: int64 >>>
नीचे सीरीज पर कुछ अन्य सामान्य ऑपरेशन दिए गए हैं।
>>> #Work as dictionaries
>>> my_series1 = pd.Series({'a':9, 'b':18, 'c':27, 'd': 36})
>>> my_series1
a 9
b 18
c 27
d 36
dtype: int64
>>> #Label attributes
>>> my_series1.name = 'Numbers'
>>> my_series1.index.name = 'letters'
>>> my_series1
letters
a 9
b 18
c 27
d 36
Name: Numbers, dtype: int64
>>> #chaning Index
>>> my_series1.index = ['w', 'x', 'y', 'z']
>>> my_series1
w 9
x 18
y 27
z 36
Name: Numbers, dtype: int64
>>> डेटाफ़्रेम
DataFrame एक टेबल की तरह काम करता है क्योंकि इसमें रो और कॉलम होते हैं। डेटाफ़्रेम में प्रत्येक स्तंभ एक श्रृंखला वस्तु है और पंक्तियों में श्रृंखला के अंदर के तत्व होते हैं।
DataFrame को बिल्ट-इन Python dicts का उपयोग करके बनाया जा सकता है:
>>> df = pd.DataFrame({
'Country': ['China', 'India', 'Indonesia', 'Pakistan'],
'Population': [1420062022, 1368737513, 269536482, 204596442],
'Area' : [9388211, 2973190, 1811570, 770880]
})
>>> df
Area Country Population
0 9388211 China 1420062022
1 2973190 India 1368737513
2 1811570 Indonesia 269536482
3 770880 Pakistan 204596442
>>> df['Country']
0 China
1 India
2 Indonesia
3 Pakistan
Name: Country, dtype: object
>>> df.columns
Index(['Area', 'Country', 'Population'], dtype='object')
>>> df.index
RangeIndex(start=0, stop=4, step=1)
>>> तत्वों को एक्सेस करना
पंक्ति अनुक्रमणिका स्पष्ट रूप से प्रदान करने के कई तरीके हैं।
>>> df = pd.DataFrame({
'Country': ['China', 'India', 'Indonesia', 'Pakistan'],
'Population': [1420062022, 1368737513, 269536482, 204596442],
'Landarea' : [9388211, 2973190, 1811570, 770880]
}, index = ['CHA', 'IND', 'IDO', 'PAK'])
>>> df
Country Landarea Population
CHA China 9388211 1420062022
IND India 2973190 1368737513
IDO Indonesia 1811570 269536482
PAK Pakistan 770880 204596442
>>> df.index = ['CHI', 'IND', 'IDO', 'PAK']
>>> df.index.name = 'Country Code'
>>> df
Country Landarea Population
Country Code
CHI China 9388211 1420062022
IND India 2973190 1368737513
IDO Indonesia 1811570 269536482
PAK Pakistan 770880 204596442
>>> df['Country']
Country Code
CHI China
IND India
IDO Indonesia
PAK Pakistan
Name: Country, dtype: object अनुक्रमणिका का उपयोग करके पंक्ति पहुंच कई तरीकों से की जा सकती है
- .loc का उपयोग करना और अनुक्रमणिका लेबल प्रदान करना
- .iloc का उपयोग करना और अनुक्रमणिका संख्या प्रदान करना
>>> df.loc['IND'] Country India Landarea 2973190 Population 1368737513 Name: IND, dtype: object >>> df.iloc[1] Country India Landarea 2973190 Population 1368737513 Name: IND, dtype: object >>> >>> df.loc[['CHI', 'IND'], 'Population'] Country Code CHI 1420062022 IND 1368737513 Name: Population, dtype: int64
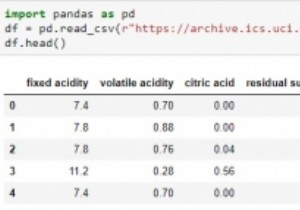
फ़ाइलें पढ़ना और लिखना
पांडा सीएसवी, एक्सएमएल, एचटीएमएल, एक्सेल, एसक्यूएल, जेएसओएन सहित कई लोकप्रिय फ़ाइल स्वरूपों का समर्थन करता है। आमतौर पर CSV फ़ाइल स्वरूप का उपयोग किया जाता है।
csv फ़ाइल पढ़ने के लिए, बस दौड़ें:
>>> df = pd.read_csv('GDP.csv', sep = ',') नामांकित तर्क sep GDP.csv नामक CSV फ़ाइल में विभाजक वर्ण की ओर इशारा करता है।
एकत्रीकरण और समूहीकरण
पांडा में डेटा को समूहबद्ध करने के लिए हम .groupby विधि का उपयोग कर सकते हैं। पंडों में समुच्चय और समूहीकरण के उपयोग को प्रदर्शित करने के लिए मैंने टाइटैनिक डेटासेट का उपयोग किया है, आप इसे नीचे दिए गए लिंक से पा सकते हैं:
https://yadi.sk/d/TfhJdE2k3EyALt
>>> titanic_df = pd.read_csv('titanic.csv')
>>> print(titanic_df.head())
PassengerID Name PClass
Age \
0 1 Allen, Miss Elisabeth Walton 1st
29.00
1 2 Allison, Miss Helen Loraine 1st
2.00
2 3 Allison, Mr Hudson Joshua Creighton 1st
30.00
3 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st
25.00
4 5 Allison, Master Hudson Trevor 1st 0.92
Sex Survived SexCode
0 female 1 1
1 female 0 1
2 male 0 0
3 female 0 1
4 male 1 0
>>> आइए गणना करें कि कितने यात्री (महिला और पुरुष) बच गए और कितने नहीं बचे, हम .groupby
का उपयोग करेंगे।>>> print(titanic_df.groupby(['Sex', 'Survived'])['PassengerID'].count()) Sex Survived female 0 154 1 308 male 0 709 1 142 Name: PassengerID, dtype: int64
केबिन वर्ग के आधार पर उपरोक्त डेटा:
>>> print(titanic_df.groupby(['PClass', 'Survived'])['PassengerID'].count()) PClass Survived * 0 1 1st 0 129 1 193 2nd 0 160 1 119 3rd 0 573 1 138 Name: PassengerID, dtype: int64
पांडा का उपयोग करके समय श्रृंखला विश्लेषण
पंडों को समय श्रृंखला डेटा का विश्लेषण करने के लिए बनाया गया था। उदाहरण के लिए, मैंने अमेज़ॅन 5 साल के स्टॉक की कीमतों का उपयोग किया है। आप इसे नीचे दिए गए लिंक से डाउनलोड कर सकते हैं,
https://finance.yahoo.com/quote/AMZN/history?period1=1397413800.2=1555180200&interval=1mo&filter=history&frequency=1mo
>>> import pandas as pd
>>> amzn_df = pd.read_csv('AMZN.csv', index_col='Date', parse_dates=True)
>>> amzn_df = amzn_df.sort_index()
>>> print(amzn_df.info())
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 62 entries, 2014-04-01 to 2019-04-12
Data columns (total 6 columns):
Open 62 non-null object
High 62 non-null object
Low 62 non-null object
Close 62 non-null object
Adj Close 62 non-null object
Volume 62 non-null object
dtypes: object(6)
memory usage: 1.9+ KB
None ऊपर हमने दिनांक कॉलम द्वारा डेटाटाइम इंडेक्स के साथ डेटाफ्रेम बनाया है और फिर इसे सॉर्ट करें।
और औसत समापन मूल्य है,
>>> amzn_df.loc['2015-04', 'Close'].mean() 421.779999
विज़ुअलाइज़ेशन
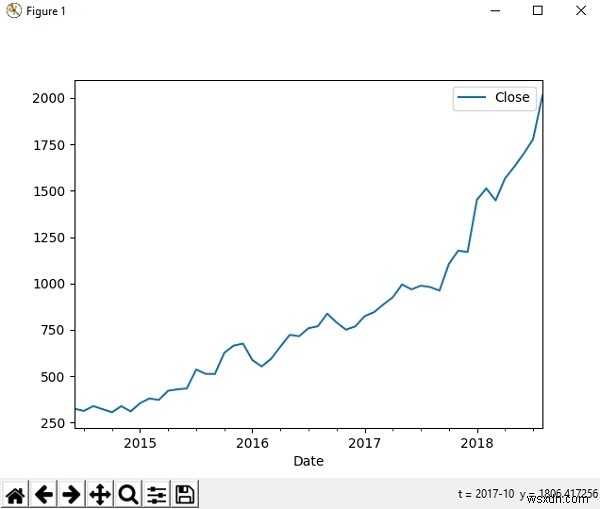
हम पांडा की कल्पना करने के लिए matplotlib लाइब्रेरी का उपयोग कर सकते हैं। आइए हमारे अमेज़ॅन स्टॉक ऐतिहासिक डेटासेट को लें और ग्राफ पर विशिष्ट समय अवधि के मूल्य आंदोलन को देखें।
>>> import matplotlib.pyplot as plt
>>> df = pd.read_csv('AMZN.csv', index_col = 'Date' , parse_dates = True)
>>> new_df = df.loc['2014-06':'2018-08', ['Close']]
>>> new_df=new_df.astype(float)
>>> new_df.plot()
<matplotlib.axes._subplots.AxesSubplot object at 0x0B9B8930>
>>> plt.show()