डेटा विश्लेषण के लिए, खोजपूर्ण डेटा विश्लेषण (ईडीए) आपका पहला कदम होना चाहिए। खोजपूर्ण डेटा विश्लेषण हमें −
. में मदद करता है-
डेटा सेट में अंतर्दृष्टि देने के लिए।
-
अंतर्निहित संरचना को समझें।
-
महत्वपूर्ण पैरामीटर और उनके बीच संबंध निकालें।
-
अंतर्निहित मान्यताओं का परीक्षण करें।
नमूना डेटा सेट का उपयोग करके EDA को समझना
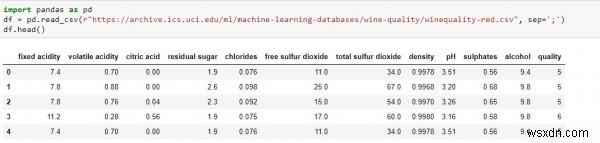
पायथन का उपयोग करके ईडीए को समझने के लिए, हम नमूना डेटा सीधे किसी भी वेबसाइट से या आपकी स्थानीय डिस्क से ले सकते हैं। मैं यूसीआई मशीन लर्निंग रिपोजिटरी से नमूना डेटा ले रहा हूं जो सार्वजनिक रूप से वाइन क्वालिटी डेटा सेट के लाल संस्करण में उपलब्ध है और ईडीए का उपयोग करके डेटा सेट में अधिक अंतर्दृष्टि प्राप्त करने का प्रयास करता है।
pddf =pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")df.head()<के रूप में आयात करें /पूर्व>
ज्यूपिटर नोटबुक में स्क्रिप्ट के ऊपर चल रहा है, आउटपुट कुछ नीचे जैसा देगा -
आरंभ करने के लिए,
-
सबसे पहले, मामले में आवश्यक पुस्तकालय, पांडा आयात करें।
-
पांडा पुस्तकालय के read_csv () फ़ंक्शन का उपयोग करके सीएसवी फ़ाइल पढ़ें और प्रत्येक डेटा को सीमांकक ";" द्वारा अलग किया जाता है दिए गए डेटा सेट में।
-
पांडा पुस्तकालय द्वारा प्रदान किए गए ".head" फ़ंक्शन की सहायता से डेटा सेट से पहले पांच अवलोकन लौटाएं। हम पांडा पुस्तकालय के ".tail ()" फ़ंक्शन का उपयोग करके इसी तरह अंतिम पांच अवलोकन प्राप्त कर सकते हैं।
हम नीचे की तरह ".shape" का उपयोग करके डेटा सेट से पंक्तियों और स्तंभों की कुल संख्या प्राप्त कर सकते हैं -
df.shape

जानकारी () फ़ंक्शन की सहायता से यह पता लगाने के लिए कि इसमें कौन से कॉलम हैं, किस प्रकार के हैं और यदि उनमें कोई मान है या नहीं।
df.info()
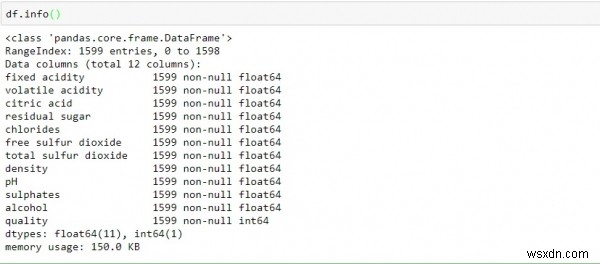
उपरोक्त डेटा को देखकर, हम निष्कर्ष निकाल सकते हैं -
-
डेटा में केवल एक पूर्णांक मान फ़्लोट होता है।
-
सभी कॉलम वेरिएबल गैर-शून्य (कोई-खाली या अनुपलब्ध मान) नहीं हैं।
पांडा द्वारा प्रदान किया गया एक अन्य उपयोगी कार्य वर्णन () है जो गणना, माध्य, मानक विचलन, न्यूनतम और अधिकतम मान और डेटा की मात्रा प्रदान करता है।
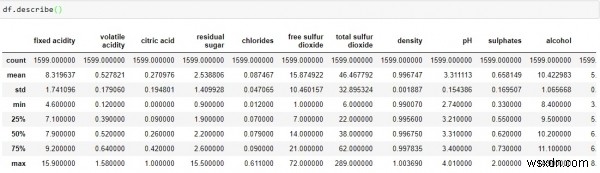
df.describe()
-
उपरोक्त डेटा से, हम यह निष्कर्ष निकाल सकते हैं कि प्रत्येक कॉलम का माध्य मान इंडेक्स कॉलम में माध्य मान (50%) से कम है।
-
भविष्यवाणियों "अवशिष्ट चीनी", "मुक्त सल्फर डाइऑक्साइड" और "कुल सल्फर डाइऑक्साइड" के 75% और अधिकतम मूल्यों के बीच बहुत बड़ा अंतर है।
-
उपरोक्त दो अवलोकनों से यह संकेत मिलता है कि हमारे डेटा सेट में चरम मान- विचलन हैं।
आश्रित चरों से हमें प्राप्त होने वाली प्रमुख अंतर्दृष्टि के जोड़े इस प्रकार हैं -
df.quality.unique()

-
“क्वालिटी” स्कोर स्केल में, 1 सबसे नीचे आता है। गरीब और 10 सबसे ऊपर आता है यानी। सबसे अच्छा।
-
ऊपर से हम यह निष्कर्ष निकाल सकते हैं कि कोई भी अवलोकन स्कोर 1(खराब), 2 और 9, 10(सर्वश्रेष्ठ) स्कोर नहीं है। सभी स्कोर 3 से 8 के बीच हैं।
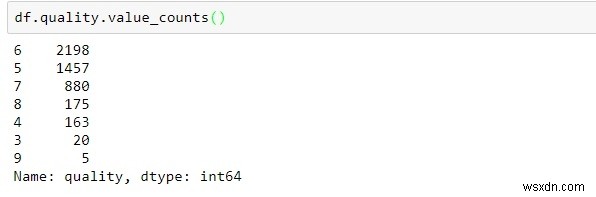
df.quality.value_counts()
-
उपरोक्त संसाधित डेटा प्रत्येक गुणवत्ता स्कोर के लिए अवरोही क्रम में वोट गणना के बारे में जानकारी प्रदान करता है।
-
अधिकांश गुणवत्ता 5-7 की सीमा में हैं।
-
3 और 6 श्रेणियों में सबसे कम अवलोकन देखे गए हैं।
डेटा विज़ुअलाइज़ेशन
गुम मानों की जांच करने के लिए -
हम सीबॉर्न लाइब्रेरी की मदद से अपने व्हाइट-व्हिस्की सीएसवी डेटा सेट में लापता मूल्यों की जांच कर सकते हैं। इसे पूरा करने के लिए कोड नीचे दिया गया है -
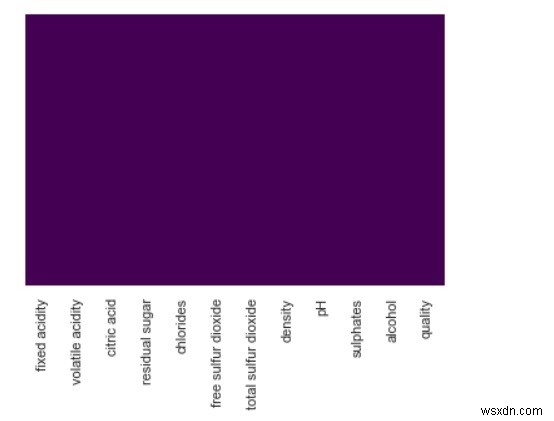
पंडों को pdimport numpy के रूप में npimport समुद्री के रूप में snsimport matplotlib.pyplot के रूप में plt%matplotlib inlinesns.set()df =pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning- के रूप में आयात करें- databases/wine-quality/winequality-white.csv", sep=";")sns.heatmap(df.isnull(), cbar=False, yticklabels=False, cmap='viridis') आउटपुट
-
ऊपर से हम देख सकते हैं कि डेटासेट में कोई गुम मान नहीं है। यदि कोई हो, तो हम बैंगनी पृष्ठभूमि पर अलग-अलग रंग की छाया द्वारा दर्शाए गए चित्र को देखेंगे।
-
अलग-अलग डेटासेट के साथ जहां गुम मान हैं और आप अंतर देखेंगे।
सहसंबंध जांचने के लिए
डेटासेट के विभिन्न मानों के बीच सहसंबंध की जांच करने के लिए, हमारे मौजूदा डेटासेट में नीचे कोड डालें -
plt.figure(figsize=(8,4))sns.heatmap(df.corr(),cmap='Greens',annot=False)
आउटपुट
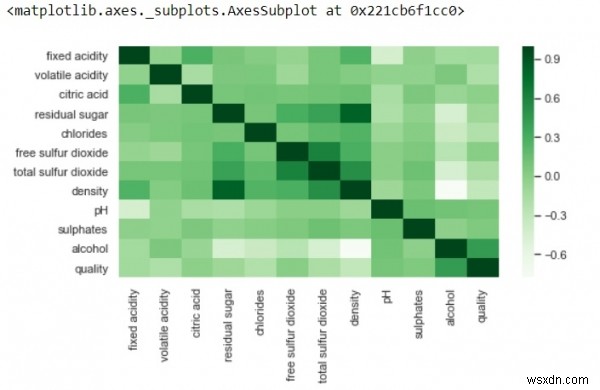
-
ऊपर, सकारात्मक सहसंबंध गहरे रंगों द्वारा दर्शाया गया है और नकारात्मक सहसंबंध हल्के रंगों द्वारा दर्शाया गया है।
-
annot=True का मान बदलता है, और आउटपुट आपको वे मान दिखाएगा जिनके द्वारा ग्रिड-सेल में सुविधाएँ एक-दूसरे से सहसंबद्ध होती हैं।
हम annot=True के साथ एक और सहसंबंध मैट्रिक्स उत्पन्न कर सकते हैं। हमारे मौजूदा कोड में कोड की नीचे की पंक्तियों को जोड़कर अपना कोड संशोधित करें -
k =12cols =df.corr().nसबसे बड़ा(k, 'गुणवत्ता')['गुणवत्ता'].indexcm =df[cols].corr()plt.figure(figsize=(8,6))sns .heatmap(cm, annot=True, cmap ='viridis')
आउटपुट
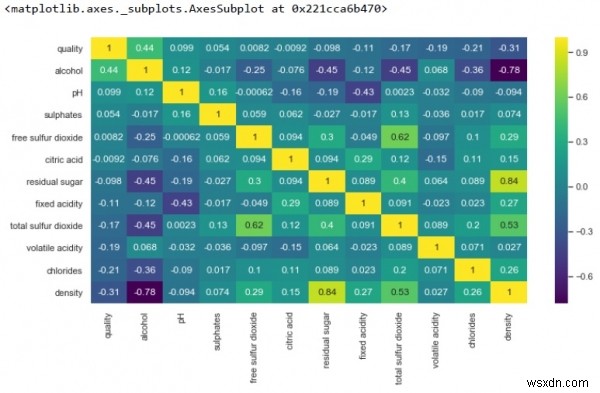
-
ऊपर से हम देख सकते हैं, अवशिष्ट चीनी के साथ घनत्व का एक मजबूत सकारात्मक संबंध है। हालांकि, घनत्व और अल्कोहल का एक मजबूत नकारात्मक सहसंबंध।
-
साथ ही, मुक्त सल्फर डाइऑक्साइड और गुणवत्ता के बीच कोई संबंध नहीं है।