परिचय..
स्कैटर-प्लॉट दो आयामों के साथ डेटा का प्रतिनिधित्व करते समय यह सत्यापित करने के लिए बहुत उपयोगी होते हैं कि दो चर के बीच कोई संबंध है या नहीं। स्कैटर प्लॉट वह चार्ट होता है जहां डेटा को X और Y मानों वाले बिंदुओं के रूप में दर्शाया जाता है।
इसे कैसे करें..
1. आदेश का पालन करके matplotlib स्थापित करें।
pip install matplotlib
2. आयात matplotlib
import matplotlib.pyplot as plt
tennis_stats = (('Federer', 20),('Nadal', 20),('Djokovic', 17),('Sampras', 14),('Emerson', 12),('laver', 11),('Murray', 3),('Wawrinka', 3),('Zverev', 0),('Theim', 1),('Medvedev',0),('Tsitsipas', 0),('Dimitrov', 0),('Rublev', 0)) 3. अगला कदम डेटा को किसी भी सरणी प्रारूप में तैयार करना है। हम डेटाबेस या स्प्रेडशीट से भी डेटा पढ़ सकते हैं और डेटा को नीचे दिए गए प्रारूप में प्रारूपित कर सकते हैं।
titles = [title for player, title in tennis_stats] players = [player for player, title in tennis_stats]
4. .scatter के पैरामीटर, matplotlib के अन्य तरीकों की तरह, X और Y मानों की एक सरणी की आवश्यकता होती है।
*नोट -* X और Y दोनों मान एक ही आकार के होने चाहिए और साथ ही डेटा डिफ़ॉल्ट रूप से एक फ्लोट में परिवर्तित हो जाता है।
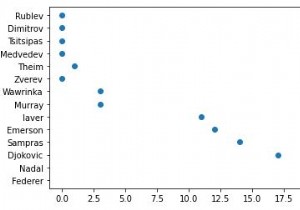
plt.scatter(titles, players)
<matplotlib.collections.PathCollection at 0x28df3684ac0>. पर
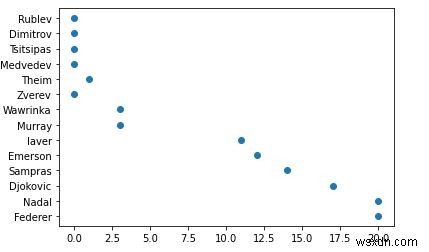
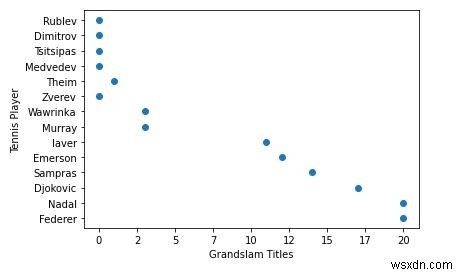
5. ओह, एक्स-एक्सिस पर प्लॉट किए गए मेरे ग्रैंडस्लैम खिताब एक फ्लोट हैं। मैं उन्हें पूर्णांक में बदल दूंगा और नीचे दिए गए फ़ंक्शन में एक्स-अक्ष और वाई-अक्ष के लिए एक शीर्षक भी जोड़ूंगा। अक्ष फ़ॉर्मेटर को .set_major_formatter के साथ अधिलेखित कर दिया जाएगा।
from matplotlib.ticker import FuncFormatter
def format_titles(title, pos):
return '{}'.format(int(title))
plt.gca().xaxis.set_major_formatter(FuncFormatter(format_titles))
plt.xlabel('Grandslam Titles')
plt.ylabel('Tennis Player')
plt.scatter(titles, players)
6. स्कैटर प्लॉट को केवल 2डी चार्ट न समझें, स्कैटर प्लॉट एक तीसरा (क्षेत्र) और यहां तक कि चौथा आयाम (रंग) भी जोड़ सकता है। मुझे थोड़ा समझाएं कि मैं नीचे क्या करने वाला हूं।
पहले हम आपकी पसंद के रंगों को परिभाषित करेंगे और फिर बेतरतीब ढंग से रंगों को उठाकर और इसे टूर वैल्यू के आधार पर लूप करेंगे।
अल्फा मान प्रत्येक बिंदु को अर्धपारदर्शी बनाता है, जिससे हमें यह देखने की अनुमति मिलती है कि वे कहां ओवरलैप करते हैं। यह मान जितना अधिक होगा, अंक उतने ही कम पारदर्शी होंगे।
import random # define your own color scale. random_colors = ['#FF0000', '#FFFF00', '#FFFFF0', '#FFFFFF', '#00000F'] # set the number of colors similar to our data values color = [random.choice(random_colors) for _ in range(len(titles))] plt.scatter(titles, players, c=color, alpha=0.5)
<matplotlib.collections.PathCollection at 0x28df2242d00>
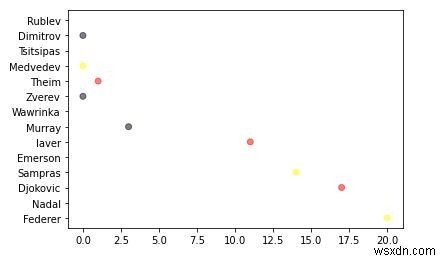
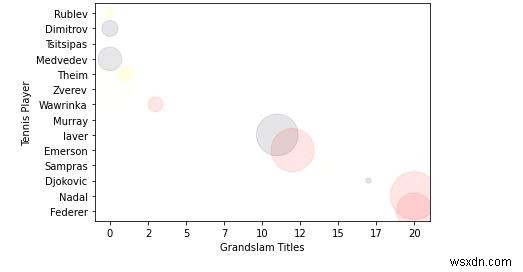
7. अब मैं, निरूपण के आकार/क्षेत्र को थोड़ा बड़ा करता हूँ।
import random
# define your own color scale.
random_colors = ['#FF0000', '#FFFF00', '#FFFFF0', '#FFFFFF', '#00000F']
# set the number of colors similar to our data values
color = [random.choice(random_colors) for _ in range(len(titles))]
# set the size
size = [(50 * random.random()) ** 2 for _ in range(len(titles))]
plt.gca().xaxis.set_major_formatter(FuncFormatter(format_titles))
plt.xlabel('Grandslam Titles')
plt.ylabel('Tennis Player')
plt.scatter(titles, players, c=color, s=size, alpha=0.1)
<matplotlib.collections.PathCollection at 0x28df22e2430>. पर
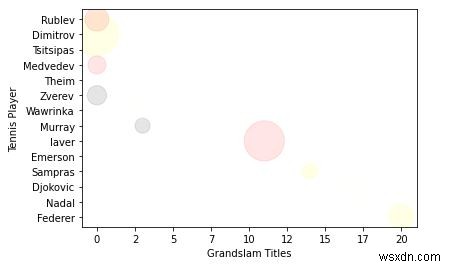
याद रखें, ग्राफ़ का अंतिम लक्ष्य डेटा को समझने में आसान बनाना है।
मैंने स्कैटर प्लॉट्स के साथ आप क्या कर सकते हैं, इसकी मूल बातें दिखायी हैं। उदाहरण के लिए, आप और भी अधिक कर सकते हैं, एक ही आकार के सभी बिंदुओं को समान रंग बनाने के लिए रंग को आकार पर निर्भर बनाते हुए, जो हमें डेटा के बीच अंतर करने में मदद कर सकता है।
अधिक एक्सप्लोर करें - https://matplotlib.org/।
अंत में, सब कुछ एक साथ रखना।
उदाहरण
# imports
import matplotlib.pyplot as plt
import random
# preparing data..
tennis_stats = (('Federer', 20),('Nadal', 20),('Djokovic', 17),('Sampras', 14),('Emerson', 12),('laver', 11),('Murray', 3),('Wawrinka', 3),('Zverev', 0),('Theim', 1),('Medvedev',0),('Tsitsipas', 0),('Dimitrov', 0),('Rublev', 0))
titles = [title for player, title in tennis_stats]
players = [player for player, title in tennis_stats]
# custom function
from matplotlib.ticker import FuncFormatter
def format_titles(title, pos):
return '{}'.format(int(title))
# define your own color scale.
random_colors = ['#FF0000', '#FFFF00', '#FFFFF0', '#FFFFFF', '#00000F']
# set the number of colors similar to our data values
color = [random.choice(random_colors) for _ in range(len(titles))]
# set the size
size = [(50 * random.random()) ** 2 for _ in range(len(titles))]
plt.gca().xaxis.set_major_formatter(FuncFormatter(format_titles))
plt.xlabel('Grandslam Titles')
plt.ylabel('Tennis Player')
plt.scatter(titles, players, c=color, s=size, alpha=0.1)
<matplotlib.collections.PathCollection at 0x2aa7676b670>. पर