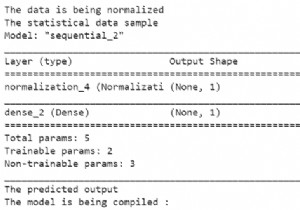
Tensorflow एक मशीन लर्निंग फ्रेमवर्क है जो Google द्वारा प्रदान किया जाता है। यह एक ओपन-सोर्स फ्रेमवर्क है जिसका उपयोग एल्गोरिदम, गहन शिक्षण अनुप्रयोगों और बहुत कुछ को लागू करने के लिए पायथन के साथ संयोजन में किया जाता है। इसका उपयोग अनुसंधान और उत्पादन उद्देश्यों के लिए किया जाता है।
कोड की निम्न पंक्ति का उपयोग करके विंडोज़ पर 'टेंसरफ़्लो' पैकेज स्थापित किया जा सकता है -
pip install tensorflow
Tensor एक डेटा संरचना है जिसका उपयोग TensorFlow में किया जाता है। यह प्रवाह आरेख में किनारों को जोड़ने में मदद करता है। इस प्रवाह आरेख को 'डेटा प्रवाह ग्राफ' के रूप में जाना जाता है। टेंसर कुछ और नहीं बल्कि बहुआयामी सरणी या एक सूची है।
प्रतिगमन समस्या के पीछे का उद्देश्य एक निरंतर या असतत चर के उत्पादन की भविष्यवाणी करना है, जैसे कि मूल्य, संभावना, बारिश होगी या नहीं और इसी तरह।
हमारे द्वारा उपयोग किए जाने वाले डेटासेट को 'ऑटो एमपीजी' डेटासेट कहा जाता है। इसमें 1970 और 1980 के दशक के ऑटोमोबाइल की ईंधन दक्षता शामिल है। इसमें वजन, अश्वशक्ति, विस्थापन आदि जैसे गुण शामिल हैं। इसके साथ, हमें विशिष्ट वाहनों की ईंधन दक्षता की भविष्यवाणी करने की आवश्यकता है।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है। निम्नलिखित कोड स्निपेट है -
उदाहरण
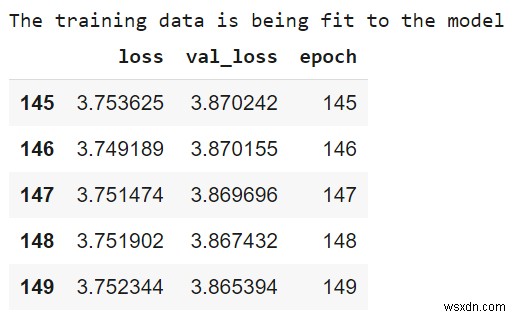
print("The training data is being fit to the model ")
history = hrspwr_model.fit(
train_features['Horsepower'], train_labels,
epochs=150,
verbose=0,
validation_split = 0.3)
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail() कोड क्रेडिट - https://www.tensorflow.org/tutorials/keras/regression
आउटपुट
स्पष्टीकरण
-
डेटा 'फिट' फ़ंक्शन का उपयोग करके मॉडल के लिए उपयुक्त है।
-
चरणों की संख्या 'युग' विशेषता का उपयोग करके निर्धारित की जाती है।
-
'इतिहास' ऑब्जेक्ट इनपुट डेटा से जुड़े आँकड़ों की प्रगति को संग्रहीत करता है।
-
इसे डेटाफ़्रेम में बदल दिया जाता है।
-
डेटा का एक नमूना कंसोल पर प्रदर्शित होता है।
-
डेटा भी विज़ुअलाइज़ किया गया है।