Tensorflow एक मशीन लर्निंग फ्रेमवर्क है जो Google द्वारा प्रदान किया जाता है। यह एक ओपन-सोर्स फ्रेमवर्क है जिसका उपयोग पायथन के संयोजन में एल्गोरिदम, गहन शिक्षण अनुप्रयोगों और बहुत कुछ को लागू करने के लिए किया जाता है। इसका उपयोग अनुसंधान और उत्पादन उद्देश्यों के लिए किया जाता है। इसमें अनुकूलन तकनीकें हैं जो जटिल गणितीय कार्यों को शीघ्रता से करने में मदद करती हैं।
कोड की निम्न पंक्ति का उपयोग करके विंडोज़ पर 'टेंसरफ़्लो' पैकेज स्थापित किया जा सकता है -
pip install tensorflow
Tensor एक डेटा संरचना है जिसका उपयोग TensorFlow में किया जाता है। यह प्रवाह आरेख में किनारों को जोड़ने में मदद करता है। इस प्रवाह आरेख को 'डेटा प्रवाह ग्राफ' के रूप में जाना जाता है। टेंसर और कुछ नहीं बल्कि एक बहुआयामी सरणी या एक सूची है।
केरस को प्रोजेक्ट ONEIROS (ओपन-एंडेड न्यूरो-इलेक्ट्रॉनिक इंटेलिजेंट रोबोट ऑपरेटिंग सिस्टम) के लिए अनुसंधान के एक भाग के रूप में विकसित किया गया था। केरस एक डीप लर्निंग एपीआई है, जिसे पायथन में लिखा गया है। यह एक उच्च-स्तरीय एपीआई है जिसमें एक उत्पादक इंटरफ़ेस है जो मशीन सीखने की समस्याओं को हल करने में मदद करता है। यह Tensorflow ढांचे के शीर्ष पर चलता है। इसे त्वरित तरीके से प्रयोग में मदद करने के लिए बनाया गया था। यह आवश्यक सार तत्व और बिल्डिंग ब्लॉक्स प्रदान करता है जो मशीन लर्निंग सॉल्यूशंस को विकसित करने और इनकैप्सुलेट करने के लिए आवश्यक हैं।
केरस पहले से ही Tensorflow पैकेज में मौजूद है। इसे कोड की नीचे दी गई लाइन का उपयोग करके एक्सेस किया जा सकता है।
import tensorflow from tensorflow import keras
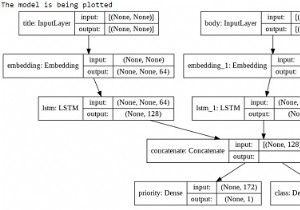
केरस कार्यात्मक एपीआई ऐसे मॉडल बनाने में मदद करता है जो अनुक्रमिक एपीआई का उपयोग करके बनाए गए मॉडल की तुलना में अधिक लचीले होते हैं। कार्यात्मक एपीआई उन मॉडलों के साथ काम कर सकता है जिनमें गैर-रेखीय टोपोलॉजी है, परतों को साझा कर सकते हैं और कई इनपुट और आउटपुट के साथ काम कर सकते हैं। एक डीप लर्निंग मॉडल आमतौर पर एक निर्देशित एसाइक्लिक ग्राफ (DAG) होता है जिसमें कई परतें होती हैं। कार्यात्मक एपीआई परतों का ग्राफ बनाने में मदद करता है।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है। मॉडल को प्रशिक्षित करने के लिए कोड स्निपेट निम्नलिखित है -
उदाहरण
print("Sample input data")
title_data = np.random.randint(num_words, size=(1280, 10))
body_data = np.random.randint(num_words, size=(1280, 100))
tags_data = np.random.randint(2, size=(1280, num_tags)).astype("float32")
print("Sample target data")
priority_targets = np.random.random(size=(1280, 1))
dept_targets = np.random.randint(2, size=(1280, num_classes))
print("The model is being fit to the data")
model.fit(
{"title": title_data, "body": body_data, "tags": tags_data},
{"priority": priority_targets, "class": dept_targets},
epochs=2,
batch_size=32,
) कोड क्रेडिट - https://www.tensorflow.org/guide/keras/functional
आउटपुट
Sample input data Sample target data The model is being fit to the data Epoch 1/2 40/40 [==============================] - 5s 43ms/step - loss: 1.2738 - priority_loss: 0.7043 - class_loss: 2.8477 Epoch 2/2 40/40 [==============================] - 2s 44ms/step - loss: 1.2720 - priority_loss: 0.6997 - class_loss: 2.8612 <tensorflow.python.keras.callbacks.History at 0x7f48d0809e80>
स्पष्टीकरण
-
नमूना इनपुट और लक्ष्य डेटा उत्पन्न होते हैं।
-
मॉडल को इनपुट और लक्ष्य की एक नम्पी सरणी पास करके प्रशिक्षित किया जाता है।