Tensorflow एक मशीन लर्निंग फ्रेमवर्क है जो Google द्वारा प्रदान किया जाता है। यह एक ओपन-सोर्स फ्रेमवर्क है जिसका उपयोग एल्गोरिदम, गहन शिक्षण अनुप्रयोगों और बहुत कुछ को लागू करने के लिए पायथन के साथ संयोजन में किया जाता है। कोड की निम्न पंक्ति का उपयोग करके विंडोज़ पर 'टेंसरफ़्लो' पैकेज स्थापित किया जा सकता है -
pip install tensorflow
Tensor एक डेटा संरचना है जिसका उपयोग TensorFlow में किया जाता है। यह प्रवाह आरेख में किनारों को जोड़ने में मदद करता है। इस प्रवाह आरेख को 'डेटा प्रवाह ग्राफ' के रूप में जाना जाता है। टेंसर और कुछ नहीं बल्कि एक बहुआयामी सरणी या एक सूची है।
प्रतिगमन समस्या के पीछे का उद्देश्य एक निरंतर या असतत चर के उत्पादन की भविष्यवाणी करना है, जैसे कि मूल्य, संभावना, बारिश होगी या नहीं और इसी तरह।
हमारे द्वारा उपयोग किए जाने वाले डेटासेट को 'ऑटो एमपीजी' डेटासेट कहा जाता है। इसमें 1970 और 1980 के दशक के ऑटोमोबाइल की ईंधन दक्षता शामिल है। इसमें वजन, अश्वशक्ति, विस्थापन आदि जैसे गुण शामिल हैं। इसके साथ, हमें विशिष्ट वाहनों की ईंधन दक्षता की भविष्यवाणी करने की आवश्यकता है।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है।
निम्नलिखित कोड स्निपेट है -
उदाहरण
print("Separating the label from features")
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
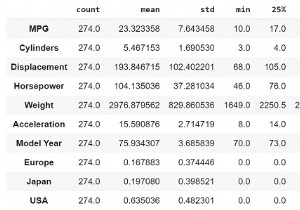
print("The mean and standard deviation of the training dataset : ")
train_dataset.describe().transpose()[['mean', 'std']]
print("Normalize the features since they use different scales")
print("Creating the normalization layer")
normalizer = preprocessing.Normalization()
normalizer.adapt(np.array(train_features))
print(normalizer.mean.numpy())
first = np.array(train_features[3:4])
print("Every feature has been individually normalized")
with np.printoptions(precision=2, suppress=True):
print('First example is :', first)
print()
print('Normalized data :', normalizer(first).numpy()) कोड क्रेडिट - https://www.tensorflow.org/tutorials/keras/regression
आउटपुट
Separating the label from features The mean and standard deviation of the training dataset : Normalize the features since they use different scales Creating the normalization layer [ 5.467 193.847 104.135 2976.88 15.591 75.934 0.168 0.197 0.635] Every feature has been individually normalized First example is : [[ 4. 105. 63. 2125. 14.7 82. 0. 0. 1. ]] Normalized data : [[−0.87 −0.87 −1.11 −1.03 −0.33 1.65 −0.45 −0.5 0.76]]
स्पष्टीकरण
-
लक्ष्य मान (लेबल) को सुविधाओं से अलग किया जाता है।
-
लेबल वह मान है जिसे होने वाली भविष्यवाणियों के लिए प्रशिक्षित करने की आवश्यकता होती है।
-
सुविधाओं को सामान्यीकृत किया जाता है ताकि प्रशिक्षण स्थिर रहे।
-
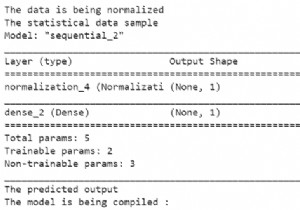
Tensorflow में 'सामान्यीकरण' फ़ंक्शन डेटा को प्रीप्रोसेस करता है।
-
पहली परत बनाई जाती है, और इस परत में माध्य और प्रसरण संग्रहीत किए जाते हैं।
-
जब इस परत को कॉल किया जाता है, तो यह इनपुट डेटा लौटाता है जहां हर सुविधा को सामान्य किया गया है।