मूल रूप से Tricore द्वारा प्रकाशित:11 जुलाई, 2017
Apache™ Hadoop® पर इस दो-भाग श्रृंखला के भाग 1 में, हमने Hadoopecosystem और Hadoop ढांचे को पेश किया। भाग 2 में, हम Hadoop ढांचे के अधिक मुख्य घटकों को शामिल करते हैं, जिनमें क्वेरी, बाहरी एकीकरण, डेटा विनिमय, समन्वय और प्रबंधन शामिल हैं। हम एक मॉड्यूल भी पेश करते हैं जो Hadoop क्लस्टर की निगरानी करता है।
क्वेरी करना
इस श्रृंखला के भाग 1 ने Apache Pig™ को एक स्क्रिप्टिंग टूल के रूप में पेश किया। पिग लैटिन में लिखा गया, पिग को निष्पादन योग्य MapReduce नौकरियों में अनुवादित किया गया है। यह कई लाभ प्रदान करता है जिनके बारे में आप भाग 1 में अधिक जान सकते हैं।
हालाँकि, कुछ डेवलपर अभी भी SQL पसंद करते हैं। यदि आप जो जानते हैं उसके साथ जाना चाहते हैं, तो आप इसके बजाय Hadoop के साथ SQL का उपयोग कर सकते हैं।
हाइव
Apache Hive™ एक वितरित डेटा वेयरहाउस है जो बड़ी मात्रा में डेटा को प्रबंधित और व्यवस्थित करता है। यह गोदाम HadoopDistributed File System (HDFS™) के शीर्ष पर बनाया गया है। Hive क्वेरी भाषा, HiveQL, SQL शब्दार्थ पर आधारित है। रनटाइम इंजन HiveQL को MapReduce नौकरियों में परिवर्तित करता है जो डेटा को क्वेरी करता है।
हाइव निम्नलिखित क्षमताएं प्रदान करता है:
-
बड़ी मात्रा में कच्चे डेटा को रखने के लिए एक योजनाबद्ध डेटा स्टोर।
-
HDFS में अपरिष्कृत डेटा पर विश्लेषण और क्वेरी निष्पादित करने के लिए SQL जैसा वातावरण।
-
बाहरी संबंधपरक डेटाबेस प्रबंधन प्रणाली (आरडीबीएमएस) अनुप्रयोगों के साथ एकीकरण।
निम्न छवि Hadoop पारिस्थितिकी तंत्र की वास्तुकला की कल्पना करती है:
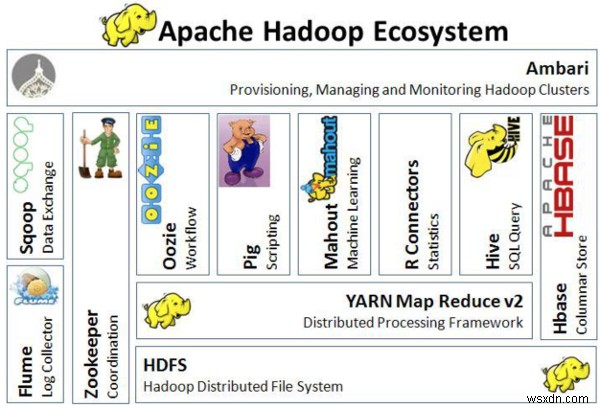 Hadoop पारिस्थितिकी तंत्र की वास्तुकला
Hadoop पारिस्थितिकी तंत्र की वास्तुकला बाहरी एकीकरण
Apache Flume™ एक वितरित, विश्वसनीय और उपलब्ध सेवा है जो बड़ी मात्रा में लॉग डेटा को HDFS में कुशलता से एकत्रित करने, एकत्र करने और स्थानांतरित करने के लिए है। Flume एक स्ट्रीमिंग डेटाफ़्लो आर्किटेक्चर का उपयोग करके बड़ी मात्रा में ईवेंट डेटा को स्थानांतरित करता है जो दोष सहिष्णु और फ़ेलओवर पुनर्प्राप्ति के लिए तैयार है।
Flume निम्नलिखित क्षमताएं भी प्रदान करता है:
-
बड़ी मात्रा में इवेंट डेटा जैसे नेटवर्क ट्रैफ़िक, लॉग और ईमेल संदेशों को ट्रांसपोर्ट करता है।
-
कई स्रोतों से डेटा को एचडीएफएस में स्ट्रीम करता है।
-
Hadoop अनुप्रयोगों के लिए विश्वसनीय, रीयल-टाइम डेटा स्ट्रीमिंग की गारंटी देता है।
डेटा एक्सचेंज
Apache Sqoop™ को Hadoop और बाहरी डेटा स्टोर जैसे रिलेशनल डेटाबेस और एंटरप्राइज़ डेटा वेयरहाउस के बीच बल्क डेटा को कुशलतापूर्वक स्थानांतरित करने के लिए डिज़ाइन किया गया है। Sqoop संबंधपरक डेटाबेस जैसे TeradataDatabase, IBM® Netezza, Oracle® Database, MySQL™, औरPostgreSQL® के साथ काम करता है। ज्यादातर कंपनियों में स्कूप का व्यापक रूप से उपयोग किया जाता है जो बड़े डेटा का विश्लेषण करते हैं।
Sqoop निम्नलिखित कार्यक्षमता प्रदान करता है:
-
डेटाबेस के आधार पर, यह आयातित डेटा के लिए स्कीमा का वर्णन करने की अधिकांश प्रक्रिया को स्वचालित कर सकता है।
-
यह डेटा आयात और निर्यात करने के लिए MapReduce ढांचे का उपयोग करता है। यह Sqoop को समानांतर तंत्र और दोष सहनशीलता प्रदान करने में सक्षम बनाता है।
-
यह सभी प्रमुख RDBMS डेटाबेस के लिए कनेक्टर प्रदान करता है।
-
यह पूर्ण और वृद्धिशील भार, समानांतर निर्यात और डेटा के आयात और डेटा संपीड़न का समर्थन करता है।
-
यह Kerberos सुरक्षा एकीकरण का समर्थन करता है।
समन्वय
अपाचे ज़ूकीपर™ वितरित अनुप्रयोगों के लिए एक समन्वय सेवा है जो एक क्लस्टर में सिंक्रनाइज़ेशन को सक्षम बनाता है। यह एक केंद्रीकृत भंडार प्रदान करता है जहां वितरित अनुप्रयोग डेटा को संग्रहीत और पुनर्प्राप्त कर सकते हैं।
ज़ुकीपर एक प्रशासनिक हडूप उपकरण है जिसका उपयोग क्लस्टर में नौकरियों का प्रबंधन करने के लिए किया जाता है। कुछ डेवलपर इस टूल को "वॉच गार्ड" के रूप में संदर्भित करते हैं क्योंकि एक नोड में डेटा में कोई भी परिवर्तन अन्य नोड्स को सूचित किया जाता है।
Hadoop क्लस्टर का प्रावधान, प्रबंधन और निगरानी
Apache Ambari™ Apache Hadoop क्लस्टर के प्रावधान, प्रबंधन और निगरानी के लिए एक वेब-आधारित उपकरण है। इसमें उपकरण स्थापित करने और प्रबंधन, कॉन्फ़िगरेशन और निगरानी कार्यों को करने के लिए एक बहुत ही सरल लेकिन अत्यधिक इंटरैक्टिव यूजर इंटरफेस है। अंबारी गर्मी के नक्शे जैसे क्लस्टर स्वास्थ्य पर जानकारी देखने के लिए एक डैशबोर्ड प्रदान करता है। यह आपको सुविधाओं के साथ-साथ अपने MapReduce, Pig, और Hive अनुप्रयोगों को देखने में भी सक्षम बनाता है ताकि आप उनकी प्रदर्शन विशेषताओं का आसानी से निदान कर सकें।
अंबारी निम्नलिखित क्षमताएं भी प्रदान करता है:
-
नोड्स के साथ मास्टर सेवा मानचित्रण।
-
उन सेवाओं को चुनने की क्षमता जिन्हें आप इंस्टॉल करना चाहते हैं।
-
सरल कस्टम स्टैक चयन।
-
एक क्लीनर इंटरफ़ेस।
-
सुव्यवस्थित स्थापना, निगरानी और प्रबंधन।
निष्कर्ष
Hadoop उन कंपनियों के लिए एक बहुत ही प्रभावी समाधान है जो भारी मात्रा में डेटा का भंडारण और विश्लेषण करना चाहती हैं। वितरित प्रणालियों में डेटा प्रबंधन के लिए यह एक बहुत ही मांग वाला उपकरण है। क्योंकि यह खुला स्रोत है, यह कंपनियों के लिए लाभ उठाने के लिए स्वतंत्र रूप से उपलब्ध है। Hadoop के बारे में अधिक जानने के लिए, Apache Software Foundation की वेबसाइट पर आधिकारिक दस्तावेज देखें।
क्या आपने हडोप का इस्तेमाल किया है? कोई टिप्पणी करने या प्रश्न पूछने के लिए प्रतिक्रिया टैब का उपयोग करें।