स्किकिट-लर्न, जिसे आमतौर पर स्केलेर के रूप में जाना जाता है, पायथन में एक पुस्तकालय है जिसका उपयोग मशीन लर्निंग एल्गोरिदम को लागू करने के उद्देश्य से किया जाता है।
यह एक ओपन सोर्स लाइब्रेरी है इसलिए इसे मुफ्त में इस्तेमाल किया जा सकता है। शक्तिशाली और मजबूत, क्योंकि यह सांख्यिकीय मॉडलिंग करने के लिए विभिन्न प्रकार के उपकरण प्रदान करता है। इसमें पायथन में एक शक्तिशाली और स्थिर इंटरफ़ेस की मदद से वर्गीकरण, प्रतिगमन, क्लस्टरिंग, आयामीता में कमी और बहुत कुछ शामिल है। यह पुस्तकालय Numpy, SciPy और Matplotlib पुस्तकालयों पर बनाया गया है।
इसे नीचे दिखाए गए अनुसार 'पाइप' कमांड का उपयोग करके स्थापित किया जा सकता है -
pip install scikit-learn
यह पुस्तकालय डेटा मॉडलिंग पर केंद्रित है।
स्किकिट-लर्न में उपयोग किए जाने वाले कई मॉडल हैं, और उनमें से कुछ का सारांश नीचे दिया गया है।
पर्यवेक्षित लर्निंग एल्गोरिदम
पर्यवेक्षित शिक्षण एल्गोरिथ्म को एक निश्चित तरीके से व्यवहार करना सिखाया जाता है। एक निश्चित वांछित आउटपुट को किसी दिए गए इनपुट में मैप किया जाता है जिससे मानव पर्यवेक्षण प्रदान किया जाता है। यह सुविधाओं (इनपुट डेटासेट में मौजूद वेरिएबल) को लेबल करके, डेटा को फ़ीडबैक प्रदान करके (क्या आउटपुट को एल्गोरिदम द्वारा सही ढंग से भविष्यवाणी की गई थी, और यदि नहीं तो सही भविष्यवाणी क्या होनी चाहिए) इत्यादि। पी>
एक बार जब एल्गोरिथ्म इस तरह के इनपुट डेटा पर पूरी तरह से प्रशिक्षित हो जाता है, तो इसे समान प्रकार के डेटा के लिए काम करने के लिए सामान्यीकृत किया जा सकता है। यह पहले कभी नहीं देखे गए इनपुट के परिणामों की भविष्यवाणी करने की क्षमता हासिल करेगा यदि प्रशिक्षित मॉडल में अच्छा प्रदर्शन मेट्रिक्स है। यह एक महंगा सीखने वाला एल्गोरिदम है क्योंकि मनुष्यों को इनपुट डेटासेट को भौतिक रूप से लेबल करने की आवश्यकता होती है जिससे अतिरिक्त लागतें जुड़ती हैं।
Sklearn लीनियर रिग्रेशन सपोर्ट वेक्टर मशीन, डिसीजन ट्री वगैरह को लागू करने में मदद करता है।
अनपर्यवेक्षित लर्निंग
यह पर्यवेक्षित शिक्षण के विपरीत है, अर्थात इनपुट डेटा सेट को लेबल नहीं किया गया है, जिससे शून्य मानव पर्यवेक्षण का संकेत मिलता है। एल्गोरिथ्म ऐसे बिना लेबल वाले डेटा से सीखता है, पैटर्न निकालता है, भविष्यवाणियां करता है, डेटा में अंतर्दृष्टि देता है और अपने आप अन्य ऑपरेशन करता है। अधिकांश समय, वास्तविक दुनिया का डेटा असंरचित और बिना लेबल वाला होता है।
Sklearn क्लस्टरिंग, कारक विश्लेषण, प्रमुख घटक विश्लेषण, तंत्रिका नेटवर्क आदि को लागू करने में मदद करता है।
क्लस्टरिंग
इसी तरह के डेटा को एक संरचना में समूहीकृत किया जाता है और कोई भी शोर (बाहरी या असामान्य डेटा) इस क्लस्टर के बाहर आ जाएगा जिसे बाद में समाप्त या अवहेलना किया जा सकता है।
क्रॉस सत्यापन
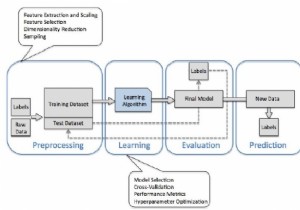
यह एक ऐसी प्रक्रिया है जिसमें मूल डेटासेट को दो भागों में विभाजित किया जाता है- 'प्रशिक्षण डेटासेट' और 'परीक्षण डेटासेट'। क्रॉस-सत्यापन का उपयोग करने पर 'सत्यापन डेटासेट' की आवश्यकता समाप्त हो जाती है। 'क्रॉस-वैलिडेशन' पद्धति के कई रूप हैं। सबसे अधिक इस्तेमाल की जाने वाली क्रॉस-वेलिडेशन विधि 'k' फोल्ड क्रॉस-वेलिडेशन है।
आयाम में कमी
आयाम में कमी उन तकनीकों के बारे में बताती है जिनका उपयोग किसी डेटासेट में सुविधाओं की संख्या को कम करने के लिए किया जाता है। यदि किसी डेटासेट में सुविधाओं की संख्या अधिक है, तो एल्गोरिथम को मॉडल करना अक्सर मुश्किल होता है। यदि इनपुट डेटासेट में बहुत अधिक चर हैं, तो मशीन लर्निंग एल्गोरिदम का प्रदर्शन काफी हद तक कम हो सकता है।
फीचर स्पेस में बड़ी संख्या में आयामों के लिए बड़ी मात्रा में मेमोरी की आवश्यकता होती है, और इसका मतलब है कि सभी डेटा को स्पेस (डेटा की पंक्तियों) पर उपयुक्त रूप से प्रदर्शित नहीं किया जा सकता है। इसका मतलब है, मशीन लर्निंग एल्गोरिदम का प्रदर्शन प्रभावित होगा, और इसे 'आयाम का अभिशाप' भी कहा जाता है। इसलिए डेटासेट में इनपुट सुविधाओं की संख्या को कम करने का सुझाव दिया गया है। इसलिए नाम 'आयामीता में कमी'।