मूल रूप से Tricore द्वारा प्रकाशित:2 अगस्त, 2017
हालांकि MongoDB के साथ शुरुआत करना आसान है, जब आप एप्लिकेशन बना रहे होते हैं तो अधिक जटिल मुद्दे सामने आते हैं। हो सकता है कि आप खुद को कुछ इस तरह से हैरान कर दें:
- मैं किसी रेप्लिका सदस्य को रेप्लिका सेट में फिर से कैसे सिंक करूं?
- दुर्घटना के बाद मैं MongoDB कैसे पुनर्प्राप्त कर सकता हूं?
- फ़ाइलों को संग्रहीत और पुनर्प्राप्त करने के लिए मुझे MongoDB के GridFS विनिर्देश का उपयोग कब करना चाहिए?
- मैं दूषित डेटा को कैसे ठीक करूं?
जब आप MongoDB का उपयोग कर रहे हों, तो यह ब्लॉग पोस्ट इन स्थितियों से निपटने के लिए कुछ सुझाव साझा करता है।
युक्ति 1:अपना डेटा पुनर्प्राप्त करने के लिए मरम्मत आदेश पर निर्भर न रहें
यदि आपका डेटाबेस क्रैश हो जाता है और आप –journal . के साथ नहीं चल रहे हैं ध्वज, उस सर्वर के डेटा का उपयोग न करें।
MongoDB की repair आदेश प्रत्येक दस्तावेज़ के माध्यम से जाता है जो इसे ढूंढ सकता है और इसकी एक साफ प्रति बनाता है। हालांकि, ध्यान रखें कि यह प्रक्रिया समय लेने वाली है, बहुत सारे डिस्क स्थान का उपयोग करती है (उसी स्थान का वर्तमान में उपयोग किया जा रहा है), और किसी भी दूषित रिकॉर्ड को छोड़ देता है। चूंकि MongoDB की प्रतिकृति प्रक्रिया दूषित डेटा को ठीक नहीं कर सकती है, इसलिए आपको पुन:समन्वयित करने से पहले संभावित रूप से दूषित डेटा को मिटा देना सुनिश्चित करना होगा।
टिप 2:प्रतिकृति सेट के सदस्य को फिर से सिंक करें
प्रतिकृति सेट के सदस्य को फिर से सिंक करने के लिए, सुनिश्चित करें कि कम से कम एक माध्यमिक सदस्य और एक प्राथमिक सदस्य ऊपर और चल रहे हैं। फिर, सुनिश्चित करें कि आपने Oracle नाम के उपयोगकर्ता के रूप में लॉग इन किया है और MongoDB सेवा बंद कर दी है।
MongoDB नाम के उपयोगकर्ता के रूप में लॉग इन करें और सभी डेटा फ़ाइलों को बैकअपफ़ोल्डर में स्थानांतरित करें ताकि यदि आप किसी समस्या में भाग लेते हैं तो आप उन्हें पुनर्स्थापित कर सकते हैं। यदि पुरानी फ़ाइलें बैकअप फ़ोल्डर में मौजूद हैं, तो आप उन्हें हटा सकते हैं। यदि आप सुनिश्चित नहीं हैं कि डेटा फ़ाइलें कहाँ मिलेंगी, तो /etc/mongod.conf में एक नज़र डालें। .Oracle नाम के उपयोगकर्ता के रूप में, MongoDB सेवा प्रारंभ करें।
सत्यापित करने के लिए डेटाबेस में लॉग इन करें। जब तक सदस्य प्रतिकृति सेट में समन्वयित नहीं हो जाता, तब तक आपको डेटाबेस तक पहुँचने के लिए प्रमाणित करने की आवश्यकता नहीं है।
प्रतिकृति प्रक्रिया पूरी होने के बाद, स्थिति बदल जाएगीSTARTUP2 से SECONDARY ।
टिप 3:छोटे, बाइनरी डेटा के लिए GridFS का उपयोग न करें
MongoDB बड़ी फ़ाइलों को संग्रहीत और पुनर्प्राप्त करने के लिए GridFS विनिर्देश का उपयोग करता है। Innessence, GridFS बड़ी बाइनरी वस्तुओं को डेटाबेस में संग्रहीत करने से पहले तोड़ देता है। ग्रिडएफएस को दो प्रश्नों की आवश्यकता होती है:एक फ़ाइल का मेटाडेटा प्राप्त करने के लिए और दूसरा उसकी सामग्री प्राप्त करने के लिए। इसलिए, यदि आप छोटी फ़ाइलों को संग्रहीत करने के लिए ग्रिडएफएस का उपयोग करते हैं, तो आप उन प्रश्नों की संख्या को दोगुना कर रहे हैं जो आपके एप्लिकेशन को करना है।
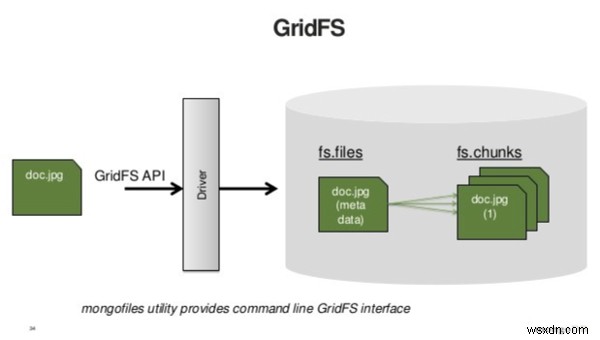
स्रोत:https://www.slideshare.net
ग्रिडएफएस को बड़े डेटा को स्टोर करने के लिए डिज़ाइन किया गया है, जिसका अर्थ है कि डेटा जो एक दस्तावेज़ में फ़िट होने के लिए बहुत बड़ा है। एक नियम के रूप में, क्लाइंट में लोड करने के लिए बहुत बड़ा कुछ भी शायद ऐसा कुछ नहीं है जिसे आप एक बार में सर्वर पर लोड करना चाहते हैं। विकल्प स्ट्रीमिंग है। आप जो कुछ भी क्लाइंट को स्ट्रीम करने की योजना बना रहे हैं वह ग्रिडएफएस के लिए एक अच्छा उम्मीदवार है।
युक्ति 4:डिस्क का उपयोग कम से कम करें
डेवलपर्स जानते हैं कि RAM से डेटा एक्सेस करना तेज़ है और डिस्क से डेटा एक्सेस करना धीमा है।
जबकि आप जानते होंगे कि डिस्क एक्सेस की संख्या को कम करना एक महान अनुकूलन तकनीक है, हो सकता है कि आप यह नहीं जानते कि इस कार्य को कैसे पूरा किया जाए।
एक तरीका सॉलिड-स्टेट ड्राइव (SSD) का उपयोग करना है। SSDs पारंपरिक हार्ड डिस्क ड्राइव (HDDs) की तुलना में बहुत तेजी से कई कार्य करते हैं। वे मोंगोडीबी के साथ भी बहुत अच्छी तरह से काम करते हैं। दूसरी ओर, वे अक्सर छोटे और अधिक महंगे होते हैं।
निम्न छवि SSDs और HDDs की तुलना करती है।

स्रोत:https://www.serverintellect.com
डिस्क एक्सेस की संख्या को कम करने का दूसरा तरीका अधिक RAM जोड़ना है। हालाँकि, यह दृष्टिकोण आपको केवल इतना ही आगे ले जाएगा, क्योंकि अंततः आपका RAM आपके डेटा के आकार को समायोजित करने में सक्षम नहीं होगा।
सवाल यह है कि, हम डिस्क पर डेटा के टेराबाइट्स या पेटाबाइट्स को कैसे स्टोर करते हैं, एक ऐसे एप्लिकेशन को प्रोग्राम करते हैं जो ज्यादातर बार-बार अनुरोध किए गए डेटा को मेमोरी में एक्सेस करेगा, और डेटा को डिस्क से मेमोरी में जितना संभव हो सके ले जाएगा?
यदि आप अपने सभी डेटा को वास्तविक समय में बेतरतीब ढंग से एक्सेस करते हैं, तो इसका उत्तर यह है कि आपको बहुत अधिक RAM की आवश्यकता होगी। हालांकि, अधिकांश एप्लिकेशन इस तरह से काम नहीं करते हैं। हाल के डेटा को पुराने डेटा की तुलना में अधिक बार एक्सेस किया जाता है, कुछ उपयोगकर्ता दूसरों की तुलना में अधिक सक्रिय होते हैं, और कुछ क्षेत्रों में दूसरों की तुलना में अधिक ग्राहक होते हैं। इस विवरण में फिट होने वाले एप्लिकेशन को कुछ दस्तावेज़ों को स्मृति में रखने के लिए डिज़ाइन किया जा सकता है। और डिस्क पर बहुत कम पहुंचें।
टिप 5:डेटाबेस क्रैश के बाद सामान्य रूप से MongoDB प्रारंभ करें
यदि आप जर्नलिंग चलाते हैं और आपका सिस्टम पुनर्प्राप्ति योग्य तरीके से क्रैश हो जाता है, तो आप डेटाबेस को सामान्य रूप से पुनरारंभ कर सकते हैं। सुनिश्चित करें कि आप अपने सभी सामान्य विकल्पों का उपयोग कर रहे हैं, विशेष रूप से -- dbpath (ताकि यह जर्नल फाइलों को ढूंढ सके) और--journal ।
कनेक्शन स्वीकार करना शुरू करने से पहले MongoDB आपके डेटा को स्वचालित रूप से ठीक कर देगा। बड़े डेटा सेट के लिए इस प्रक्रिया में कुछ मिनट लग सकते हैं, लेकिन बड़े डेटा सेट पर मरम्मत चलाने में लगने वाले समय की तुलना में बहुत कम समय लगता है।
जर्नल फ़ाइलें journal . में संग्रहित की जाती हैं निर्देशिका। इन फ़ाइलों को न हटाएं।
टिप 6:रिपेयर कमांड का उपयोग करके डेटाबेस को संकुचित करें
रिपेयर कमांड अनिवार्य रूप से एक mongodump करता है और फिर एकmongorestore , अपने डेटा की एक साफ प्रतिलिपि बनाना। इस प्रक्रिया में, यह आपकी डेटा फ़ाइलों में किसी भी खाली "छेद" को भी हटा देता है।
रिपेयर कमांड ऑपरेशन को ब्लॉक कर देता है और आपके डेटाबेस में वर्तमान में चल रहे डिस्क स्थान से दुगने स्थान की आवश्यकता होती है। हालाँकि, यदि आपके पास कोई अन्य मशीन है, तो आप mongodump . का उपयोग करके उसी प्रक्रिया को मैन्युअल रूप से निष्पादित कर सकते हैं औरmongorestore ।
प्रक्रिया को मैन्युअल रूप से पूरा करने के लिए, निम्न चरणों का उपयोग करें:
-
Hyd1 मशीन को नीचे करें और
fsyncऔरlock:rs.stepDown() db.runCommand({fsync : 1, lock : 1}) -
फ़ाइल को Hyd2 पर डंप करें:
Hyd2$ mongodump --host Hyd1 -
Hyd1 में डेटा फ़ाइल की एक प्रति बनाएँ, ताकि आपके पास अभी भी यह बैकअप के रूप में रहे। फिर, मूल डेटा फ़ाइल हटाएं और Hyd1 को खाली डेटा के साथ पुनरारंभ करें।
-
इसे Hyd2 से पुनर्स्थापित करें। डेटा फ़ाइल को पुनर्स्थापित करने के लिए, निम्न आदेश दर्ज करें:
Hyd2$ mongorestore --host Hyd1 --port 10000 # specify port if it's not 27017
निष्कर्ष
इन परिवर्तनों ने हमारे MongoDB प्रदर्शन को उल्लेखनीय रूप से बढ़ाया है। यदि आप MongoDB का उपयोग करने की योजना बना रहे हैं, तो हो सकता है कि आप इस लेख को बुकमार्क करना चाहें, फिर उस पर वापस आएं और अगली बार जब आप कोई नया प्रोजेक्ट शुरू करें तो प्रत्येक टिप की जांच करें।
इस दो-भाग श्रृंखला के भाग 2 में, हम कुछ युक्तियां साझा करेंगे जो बड़े उद्यमों को उपयोगी MongoDB सुविधाओं को ठीक से डिज़ाइन, अनुकूलित और कार्यान्वित करने में मदद करती हैं।
कोई टिप्पणी करने या प्रश्न पूछने के लिए प्रतिक्रिया टैब का उपयोग करें।


