डेटास्टोर चयन के दौरान हमारे पास जो विकल्प और संयोजन उपलब्ध हैं, वे साबित करते हैं कि अब हम एक आकार-सभी डेटास्टोर की दुनिया में नहीं हैं।
आज, आपके SQL डेटास्टोर्स (जैसे MySQL, PostgreSQL, Oracle या SQLServer) को आपके NoSQL डेटास्टोर्स (MongoDB, CouchDB, और Neo4J सहित अन्य) के साथ मिलाने और मिलान करने के लिए मजबूर करने वाले कारण हैं। जबकि Oracle अभी भी रिकॉर्ड की पसंदीदा प्रणाली हो सकती है। उद्यम, यह अब शहर का एकमात्र खेल नहीं है।
डेवलपर्स अपनी समस्याओं को हल करने के लिए SQL और NoSQL के संयोजन का उपयोग करना शुरू कर रहे हैं - कभी-कभी DBA या IT विभागों की इच्छा के विरुद्ध।
नौकरी के लिए सही टूल चुनना
आज की दुनिया में डेटास्टोर्स की पांच व्यापक श्रेणियां हैं:कॉलम-फ़ैमिली, दस्तावेज़, ग्राफ़, की-वैल्यू और रिलेशनल। पॉलीग्लॉट दृढ़ता का शाब्दिक अर्थ है अपने डेटा को स्टोर करने या बनाए रखने के लिए कई भाषाओं का उपयोग करना। अधिक व्यावहारिक शब्दों में इसका मतलब है कि हम एक ही एप्लिकेशन के भीतर से अपने डेटा तक पहुंचने के लिए साइफर, जेएसओएन, एसक्यूएल या कई अन्य क्वेरी भाषाओं का उपयोग कर सकते हैं। इन विभिन्न डेटास्टोर्स का उपयोग करना और उनकी अलग-अलग भाषाएं अधिक प्रमुख होती जा रही हैं क्योंकि डेवलपर्स अपनी दृढ़ता की जरूरतों के समाधान में लेजर के लिए बेहतर टूल ढूंढते हैं।
सैडलेज और फाउलर नोएसक्यूएल डिस्टिल्ड में पॉलीग्लॉट हठ की आवश्यकता को यह कहकर नोट करते हैं:
<ब्लॉकक्वॉट>विभिन्न डेटाबेस विभिन्न समस्याओं को हल करने के लिए डिज़ाइन किए गए हैं। सभी आवश्यकताओं के लिए एकल डेटाबेस इंजन का उपयोग करने से आमतौर पर गैर-निष्पादक समाधान होते हैं; लेन-देन संबंधी डेटा संग्रहीत करना, सत्र की जानकारी कैशिंग, ग्राहकों के ट्रैवर्सिंग ग्राफ़ [एसआईसी] और उनके दोस्तों द्वारा खरीदे गए उत्पाद अनिवार्य रूप से अलग-अलग समस्याएं हैं।
<ब्लॉकक्वॉट>आइए डेटा संबंधों के बारे में सोचते हैं। आरडीबीएमएस समाधान यह लागू करने में अच्छे हैं कि संबंध मौजूद हैं। यदि हम संबंधों की खोज करना चाहते हैं, या एक ही वस्तु से संबंधित विभिन्न तालिकाओं से डेटा ढूंढना है, तो आरडीबीएमएस का उपयोग मुश्किल होना शुरू हो जाता है।
डेटास्टोर की पसंद दो मानदंडों पर आती है:
- संग्रहीत किए जा रहे डेटा की संरचना
- डेटा के साथ इंटरैक्ट करने के लिए इस्तेमाल की जा रही क्वेरी
जिस तरह से हम डेटा को क्वेरी करते हैं, हम उसकी संरचना के तरीके को बदल देते हैं। जैसा कि सैडलेज और फाउलर ऊपर बताते हैं, रिलेशनल डेटास्टोर्स संबंधित संस्थाओं को लागू करने में उत्कृष्टता प्राप्त करते हैं; हालांकि, जैसे ही हमें उन संस्थाओं के बीच अन्य संबंधों की खोज करने की आवश्यकता होती है, वे रास्ते में आ जाते हैं।
नीचे, मैं MongoDB के साथ एक उपयोग के मामले, CraigsList डेटा संग्रह पर चर्चा करता हूं, और अनुमान लगाता हूं कि उन्होंने इसे कैसे पूरा किया होगा।
खिलाड़ी:MongoDB, MySQL और CraigsList
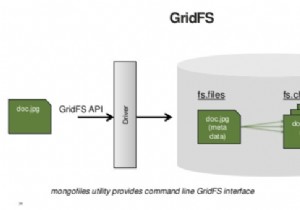
मोंगोडीबी
MongoDB MySQL के लिए एक पसंदीदा NoSQL विकल्प बन गया है। इसके कई लाभों में स्केलेबिलिटी, ऑटो-शेयरिंग और आज की लोकप्रिय प्रोग्रामिंग भाषाओं के लिए देशी बाइंडिंग की उपलब्धता शामिल है। MongoDB और रिलेशनल डेटास्टोर के बीच मुख्य अंतर MongoDB डेटा के बारे में सोचने और संग्रहीत करने का तरीका है। संबंधों को लागू करने के लिए विदेशी कुंजी बाधाओं के साथ तालिकाओं के संग्रह का उपयोग करके, MongoDB में डेटा को दस्तावेज़ों के संग्रह के रूप में दर्शाया जाता है।
दस्तावेज़ डेटा संरचनाओं में पंक्तियों या टुपल्स के अनुरूप (समान नहीं) हैं। दस्तावेज़ डेटास्टोर का वर्गीकरण और नामकरण सीधे डेटा से आता है जिसे संग्रह में समूहित JSON दस्तावेज़ों के रूप में संग्रहीत किया जाता है। इन दस्तावेज़ों की गहराई असीमित और पूरी तरह से निरीक्षण योग्य है प्रश्न या अनुक्रमणिका। आमतौर पर MongoDB के लिए डेटा का एक अच्छा प्रतिनिधित्व डेटा को असामान्य करके प्राप्त किया जा सकता है जो एक रिलेशनल डेटाबेस के लिए उपयुक्त होगा। बेशक, आप जो विशेष प्रश्न करना चाहते हैं, उन्हें इस प्रक्रिया का मार्गदर्शन करना चाहिए।
MongoDB की बारीकियों के बारे में अधिक जानकारी MongoDB की वेबसाइट पर पाई जा सकती है।
MySQL
क्लासिक जिसे हर कोई जानता है और प्यार करता है, MySQL समय की शुरुआत से (समय-सीमा की गणना में) आसपास रहा है और आसानी से सबसे व्यापक रूप से उपयोग किया जाने वाला DBMS है। इसके द्वारा प्रदान की जाने वाली कार्यक्षमता ने अनुप्रयोगों को लगभग एक दशक तक डेटा मॉडल करने और एक सिस्टम के रूप में कार्य करने की अनुमति दी है। कई व्यावसायिक उद्देश्यों के आसपास रिकॉर्ड। इन दिनों जब लोग एक रिलेशनल डेटाबेस के बारे में सोचते हैं तो वे शायद MySQL के बारे में सोचते हैं।
MySQL हमें क्लासिक रिलेशनल डेटा मॉडल का कार्यान्वयन प्रदान करता है। टाइप थ्योरी और सेट थ्योरी का उपयोग करके, इसे 1970 के दशक में E.F. Codd द्वारा विकसित किया गया था। प्रोग्रामेटिक रूप से सामान्यीकृत, नियोजित या आत्मनिरीक्षण करने में सक्षम होने के कारण, रिलेशनल डेटा सिस्टम को बेहद लोकप्रिय बनाते हैं। वास्तव में , इन डेटास्टोर्स को पसंद किया जाना जारी है क्योंकि वे मॉडलिंग डेटा की समस्या को सामान्य तरीके से हल करते हैं।
क्रेगलिस्ट
एक प्रसिद्ध ऑनलाइन व्यवसाय जो MongoDB और MySQL डेटास्टोर दोनों को नियोजित करता है, वह CraigsList है। दो डेटास्टोर को साथ-साथ अपनाने की रूपरेखा एक MongoDB केस स्टडी में दी गई है, लेकिन नीचे एक थंबनेल स्केच है।
नियामक आवश्यकताओं के कारण, क्रेगलिस्ट को अपने क्लासिफाईड के डिजिटल रिकॉर्ड को बनाए रखना पड़ता है। प्रतिदिन एक लाख से अधिक नए क्लासीफाइड्स के साथ, क्रेगलिस्ट को बनाए रखने के लिए यह एक महत्वपूर्ण मात्रा में डेटा है। यह क्लासीफाइड के बारे में सभी सक्रिय जानकारी रखने के लिए एक MySQL डेटास्टोर का उपयोग करता है, जबकि MongoDB का उपयोग संग्रहीत डेटा को संग्रहीत करने के लिए किया जाता है - संभवतः 30 दिनों में कुछ भी। सामान्य व्यावसायिक परिवर्तनों के भाग के रूप में, संग्रहीत डेटा का डेटा स्कीमा बदल जाता है। संग्रहीत डेटा के लिए MongoDB का उपयोग करके, CraigsList अपने डेटा को प्रभावी ढंग से विभाजित करने और समस्याओं को कम करने में सक्षम था स्कीमा माइग्रेशन.
एक विचार प्रयोग के रूप में, मैं एक क्रेगलिस्ट-एस्क एप्लिकेशन में मोंगोडीबी और माईएसक्यूएल साइड-बाय-साइड का उपयोग करने के लिए एक संभावित कार्यान्वयन के बारे में अनुमान लगाना चाहता हूं। यह अत्यधिक संभावना नहीं है कि क्रेगलिस्ट वास्तव में अपना डेटा स्टोरेज कैसे कर रहा है, लेकिन यह एक दिलचस्प है यह देखने का तरीका है कि एक परिचित, अत्यधिक लेन-देन वाली वेबसाइट के लिए कितने डेटास्टोर एक साथ काम कर सकते हैं।
यह कैसे किया जाता है?
डेवलपर्स और इंजीनियरों को अनिवार्य रूप से समस्याओं का सामना करना पड़ता है जब वे एक भारी SQL डेटाबेस पर स्कीमा अपडेट करते हैं। स्कीमा अपडेट लागू होने के बाद "फिक्स अप" करने के लिए कम डेटा होने से इसे टाला जा सकता है। इन माइग्रेशन या स्कीमा अपडेट का दर्द आम तौर पर बढ़ जाता है डेटा की मात्रा के अनुपात में।
हमारे उदाहरण में, मान लें कि क्रेगलिस्ट को आइटम बेचने वाले उपयोगकर्ताओं से एक नई जानकारी की आवश्यकता है। क्योंकि स्कीमा को अपडेट किया जाना चाहिए, क्रेगलिस्ट अपडेट के दर्द को कम करने के लिए प्रभावित डेटा के आकार को कम करना चाहेगी।
इन अभिलेखीय और माइग्रेशन चक्रों में से कुछ के बाद, क्रेगलिस्ट ने विषम डेटा का एक बड़ा संग्रह बनाया होगा जिसके लिए एक ही स्थान पर रहने के लिए एक स्कीमालेस डेटास्टोर की आवश्यकता होती है। MongoDB इस बिल को बहुत अच्छी तरह से फिट करता है।
क्लासीफाइड के लिए एक उदाहरण स्कीमा कुछ इस तरह दिखेगा (बेशर्मी से क्रेगलिस्ट-क्लोन से फिर से लागू):
CREATE TABLE `classifieds` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(75) COLLATE utf8_unicode_ci DEFAULT NULL,
`description` text COLLATE utf8_unicode_ci,
`location` varchar(75) COLLATE utf8_unicode_ci DEFAULT NULL,
`adtype` varchar(1) COLLATE utf8_unicode_ci DEFAULT 'O',
`email` varchar(75) COLLATE utf8_unicode_ci DEFAULT NULL,
`phone` varchar(75) COLLATE utf8_unicode_ci DEFAULT NULL,
`activation_code` varchar(40) COLLATE utf8_unicode_ci DEFAULT NULL,
`status` tinyint(4) DEFAULT '0',
`category_id` int(11) DEFAULT NULL,
`subcategory_id` int(11) DEFAULT NULL,
`city_id` int(11) DEFAULT NULL,
`permalink` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`image_file_name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`image_content_type` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`image_file_size` int(11) DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
`updated_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
बेशक, क्रेगलिस्ट की सबसे अधिक संभावना एक अलग स्कीमा है और बहुत कम से कम कई पुनरावृत्तियों के बाद उनकी वर्तमान स्कीमा की खोज की गई है। साथ ही, वे यह तय कर सकते हैं कि उनका डेटा कैसे व्यवस्थित किया जाता है और भविष्य में उनकी स्कीमा को फिर से बदल सकता है। हम <का उपयोग करना चाहते हैं कोड>बनाया_पर और updated_at यह तय करने के लिए कि हम MySQL में निहित डेटा को कब संग्रहित करने जा रहे हैं।
आइए मान लें कि क्रेगलिस्ट की क्लासीफाइड नीति बताती है कि एक क्लासीफाइड वेबसाइट पर दो सप्ताह तक उपलब्ध रहेगा। इस समय के बाद, वे चाहते हैं कि क्लासीफाइड अभी भी उपलब्ध हो लेकिन जरूरी नहीं कि सक्रिय हो (MySQL में)। इसे पूरा करने के लिए हम SQLAlchemy के संयोजन का उपयोग कर सकते हैं। और पाइमोंगो:
सबसे पहले, हमें अपने MySQL उदाहरण से डेटा प्राप्त करने की आवश्यकता है। हम इसे पूरा करने के लिए SQLAlchemy का उपयोग करेंगे और इसे हमारे स्कीमा का आत्मनिरीक्षण करेंगे (इस कोड को इस उद्देश्य के लिए और अधिक पुन:उपयोग करने योग्य बनाते हैं)।
import sqlalchemy.schema
m = sqlalchemy.schema.MetaData("mysql://root:I'm required why?@192.0.2.3/craigslist")
m.reflect()
print m.tables.keys()
यदि आप अपने डेटाबेस से सफलतापूर्वक जुड़ रहे हैं, तो आप देखेंगे कि आपकी कुंजियाँ (स्तंभ नाम) मानक पायथन फैशन में छपी हुई हैं:[u'classifieds', u'cities', u'subcategories', u'categories' ] .हमें अभी भी इन तालिकाओं से अलग-अलग डेटा आइटम प्राप्त करने की आवश्यकता है। न केवल हम उन्हें देख सकते हैं, बल्कि SQLAlchemy इसे बहुत आसान बनाने के लिए एक सुरुचिपूर्ण इंटरफ़ेस भी प्रदान करता है।
अब हमारे पास आत्मनिरीक्षण से हमारी तालिका परिभाषाएं हैं। यह समय है कि या तो ऑब्जेक्ट मैप बनाएं या उन तालिकाओं को क्वेरी करें जिनमें वे डेटा आइटम प्राप्त करें। नीचे दी गई क्वेरी डेटास्टोर से हमारे क्लासीफाइड को निकालेगी (अन्य तालिकाओं को अभ्यास के रूप में छोड़ दिया गया है पाठक)।
import sqlalchemy.sql
connection = m.bind.connect()
classifieds = m.tables['classifieds']
query = classifieds.select()
result = connection.execute(query)
for row in result:
print dict(row.items())यह स्निपेट सभी क्लासीफाइड के लिए क्वेरी करने के लिए हमारे MySQL कनेक्शन का उपयोग करता है। इसे आसानी से सभी तालिकाओं को संभालने के लिए विस्तारित किया जा सकता है, डेटा को MongoDB की दस्तावेज़ शैली को बेहतर ढंग से फिट करने के लिए डीनॉर्मलाइज़ किया जा सकता है। लेकिन इस प्रदर्शन के उद्देश्य के लिए, हम केवल ध्यान केंद्रित करेंगे क्लासीफाइड टेबल पर। इस बिंदु पर, हमने क्लासीफाइड टेबल में प्रत्येक व्यक्तिगत आइटम को एक डिक्शनरी में बदल दिया है, जो वास्तव में हमें इसे pymongo के माध्यम से MongoDB में डालने की आवश्यकता होगी।
अगला नमूना दिखाता है कि कैसे पाइमोंगो में एक शब्दकोश से जुड़ना और सम्मिलित करना है:
import pymongo
client = pymongo.MongoClient('mongodb://192.0.2.2')
db = client['craigslist']
collection = db['classifieds']
collection.insert({'_id': 1})
अब एकमात्र समस्या यह है कि कैसे SQLAlchemy और MongoDB अपनी आईडी निर्दिष्ट करते हैं। SQLAlchemy id की कुंजी का उपयोग करता है जबकि MongoDB _id . की एक कुंजी का उपयोग करता है .इस प्रकार, हमें उस कुंजी (काफी सरल प्रक्रिया) का अनुवाद करने की आवश्यकता है:classified['_id'] =classified.pop('id') ।
निष्कर्ष
जबकि SQL और NoSQL डेटास्टोर को अक्सर सभी या कुछ नहीं के प्रस्ताव के रूप में चित्रित किया जाता है, यह पता चलता है कि जटिल समस्याओं को हल करने के लिए उनका एक साथ उपयोग किया जा सकता है। इस उदाहरण के माध्यम से, हमने देखा कि एक सिस्टम के लिए बहुत कम कोड की आवश्यकता होती है जो MongoDB और दोनों का उपयोग करता है। MySQL डेटास्टोर। वास्तव में, यह डिमोनाइज्ड होने के बजाय क्रॉन द्वारा संचालित किया जा सकता है।
कई डेटास्टोर का उपयोग करने में कठिनाई अनुवाद कोड या माइग्रेशन कोड के विकास में निहित नहीं है, लेकिन अतिरिक्त सिस्टम का प्रशासन कठिनाई को बढ़ाता है। एक डेटास्टोर को बनाए रखने के लिए पहले से ही विशेषज्ञता (डेटास्टोर ज्ञान के साथ डीबीए या व्यवस्थापक) की आवश्यकता होती है, और यह जैसे-जैसे आप अधिक डेटास्टोर शुरू करते हैं, विशेषज्ञता की मांग बढ़ती जाती है।
व्यवसाय को यह तय करना होगा कि क्या एकाधिक डेटास्टोर चलाना मूल्यवान है। ऐसी प्रौद्योगिकियां हैं जो इन चुनौतियों को कम करने में मदद करेंगी।
शेफ और साल्ट जैसे ऑटोमेशन टेक्नॉलजी के अलावा, इस चुनौती को ऑब्जेक्टरॉकेट, रैकस्पेस द्वारा प्रबंधित मोंगोडीबी सेवा जैसे सेवा विक्रेताओं का लाभ उठाकर कम किया जा सकता है। बढ़ी हुई जटिलता के बावजूद, यदि कोई समस्या एकाधिक डेटास्टोर के उपयोग से लाभान्वित होगी , मान्यताओं को उन समाधानों की खोज करने से न रोकें।