'बिग डेटा' डेटा के बहुत बड़े सेट को प्रोसेस करने के लिए विशेष तकनीकों और तकनीकों का अनुप्रयोग है। ये डेटा सेट अक्सर इतने बड़े और जटिल होते हैं कि ऑन-हैंड डेटाबेस प्रबंधन टूल का उपयोग करके इसे प्रोसेस करना मुश्किल हो जाता है।
सूचना प्रौद्योगिकी के क्रांतिकारी विकास ने उद्योग में कई पूरक स्थितियों को जन्म दिया है। सबसे लगातार और यकीनन सबसे वर्तमान परिणामों में से एक, बिग डेटा की उपस्थिति है। बिग डेटा शब्द एक पकड़-वाक्यांश है जिसे भारी मात्रा में डेटा की उपस्थिति का वर्णन करने के लिए गढ़ा गया था। इतनी बड़ी मात्रा में डेटा होने का परिणाम डेटा एनालिटिक्स है।
डेटा एनालिटिक्स बिग डेटा को संरचित करने की प्रक्रिया है। बिग डेटा के भीतर, अलग-अलग पैटर्न और सहसंबंध होते हैं जो डेटा एनालिटिक्स के लिए डेटा की बेहतर गणना करने के लिए संभव बनाते हैं। यह डेटा विश्लेषण को सूचना प्रौद्योगिकी के सबसे महत्वपूर्ण भागों में से एक बनाता है।
इसलिए, यहां मैं 26 बिग डेटा एनालिटिक्स तकनीकों को सूचीबद्ध कर रहा हूं। यह सूची किसी भी तरह से संपूर्ण नहीं है।
-
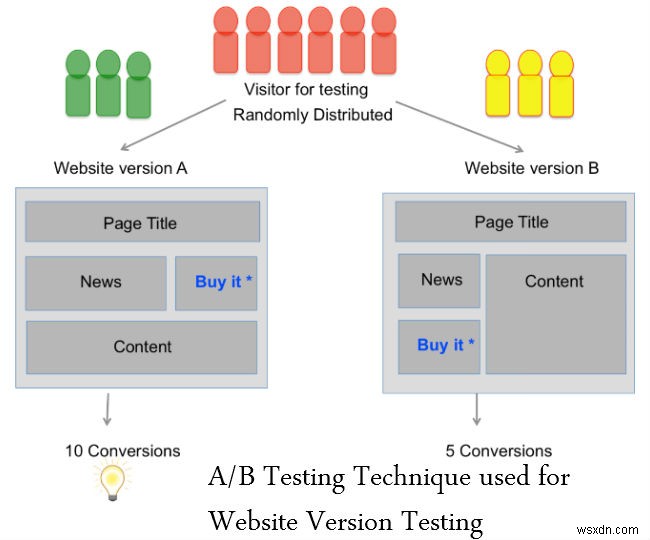
A/B परीक्षण
A/B परीक्षण यह पहचानने के लिए एक मूल्यांकन उपकरण है कि वेबपेज या ऐप का कौन सा संस्करण किसी संगठन या व्यक्ति को व्यावसायिक लक्ष्य को अधिक प्रभावी ढंग से पूरा करने में मदद करता है। यह निर्णय यह तुलना करके लिया जाता है कि किसी चीज़ का कौन सा संस्करण बेहतर प्रदर्शन करता है। A/B परीक्षण का उपयोग आमतौर पर वेब डेवलपमेंट में यह सुनिश्चित करने के लिए किया जाता है कि वेबपेज या पेज घटक में परिवर्तन डेटा द्वारा संचालित होते हैं न कि व्यक्तिगत राय से।
इसे स्पिल्ड टेस्टिंग या बकेट टेस्टिंग भी कहा जाता है।
-
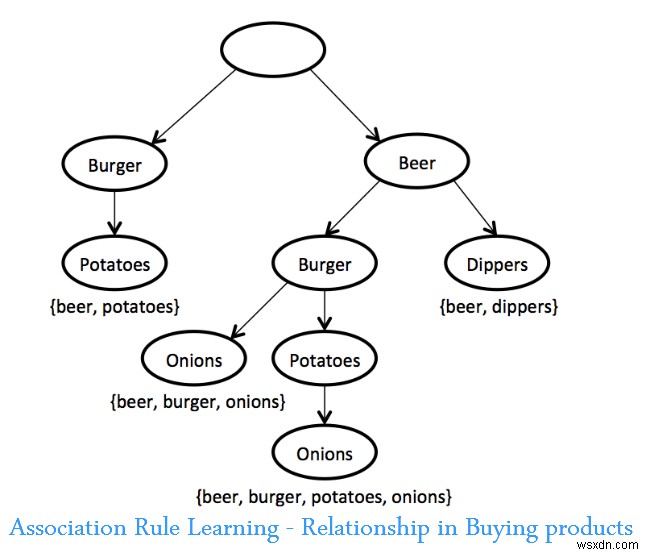
एसोसिएशन रूल लर्निंग
बड़े डेटाबेस में वेरिएबल्स के बीच दिलचस्प रिश्तों, यानी, "एसोसिएशन रूल्स" की खोज के लिए तकनीकों का एक सेट। इन तकनीकों में संभावित नियमों को उत्पन्न करने और उनका परीक्षण करने के लिए विभिन्न प्रकार के एल्गोरिदम शामिल हैं।
एक एप्लिकेशन मार्केट बास्केट विश्लेषण है, जिसमें एक खुदरा विक्रेता यह निर्धारित कर सकता है कि कौन से उत्पाद अक्सर एक साथ खरीदे जाते हैं और मार्केटिंग के लिए इस जानकारी का उपयोग करते हैं। (आमतौर पर उद्धृत उदाहरण यह खोज है कि नाचोस खरीदने वाले कई सुपरमार्केट खरीदार बीयर भी खरीदते हैं।)
-
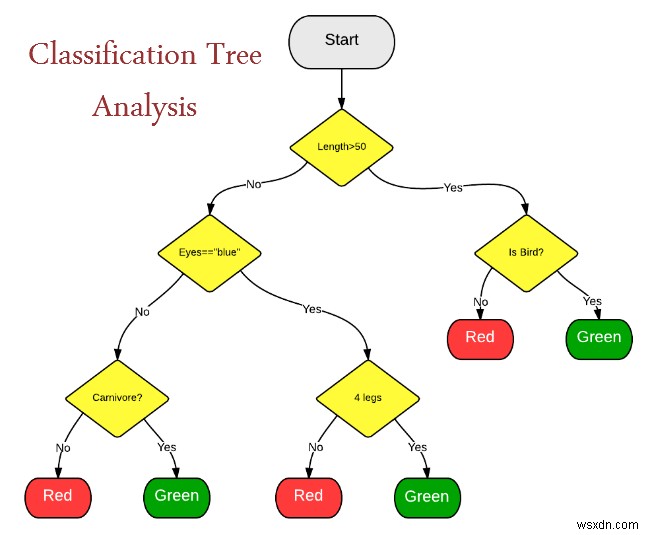
वर्गीकरण वृक्ष विश्लेषण
सांख्यिकीय वर्गीकरण उन श्रेणियों की पहचान करने का एक तरीका है जो एक नए अवलोकन से संबंधित हैं। इसके लिए सही ढंग से पहचाने गए अवलोकनों के प्रशिक्षण सेट की आवश्यकता होती है - दूसरे शब्दों में ऐतिहासिक डेटा।
सांख्यिकीय वर्गीकरण का उपयोग इसके लिए किया जा रहा है:
<उल शैली ="पाठ्य-संरेखण:औचित्य;"> - श्रेणियों को स्वचालित रूप से दस्तावेज़ असाइन करें
- जीवों को समूहों में वर्गीकृत करें
- ऑनलाइन पाठ्यक्रम लेने वाले छात्रों की प्रोफाइल विकसित करें
-
क्लस्टर विश्लेषण
वस्तुओं को वर्गीकृत करने के लिए एक सांख्यिकीय विधि जो एक विविध समूह को समान वस्तुओं के छोटे समूहों में विभाजित करती है, जिनकी समानता की विशेषताएं पहले से ज्ञात नहीं होती हैं। क्लस्टर विश्लेषण का एक उदाहरण लक्षित विपणन के लिए उपभोक्ताओं को स्व-समान समूहों में विभाजित करना है। डाटा माइनिंग के लिए उपयोग किया जाता है।
-
क्राउडसोर्सिंग
क्राउडसोर्सिंग में, अति सूक्ष्म अंतर है, एक कार्य या नौकरी आउटसोर्स की जाती है, लेकिन एक निर्दिष्ट पेशेवर या संगठन के लिए नहीं बल्कि एक खुली कॉल के रूप में आम जनता के लिए। क्राउडसोर्सिंग एक ऐसी तकनीक है जिसे टेक्स्ट मैसेज, सोशल मीडिया अपडेट, ब्लॉग आदि जैसे विभिन्न स्रोतों से डेटा इकट्ठा करने के लिए तैनात किया जा सकता है। यह एक प्रकार का जन सहयोग और वेब का उपयोग करने का एक उदाहरण है।
-
डेटा फ्यूजन और डेटा इंटिग्रेशन
परिशोधित स्थिति प्राप्त करने, अनुमानों की पहचान करने और स्थितियों का पूर्ण और समय पर आकलन करने के लिए एकल और एकाधिक स्रोतों से संबद्धता, सहसंबंध, डेटा और जानकारी के संयोजन से निपटने वाली एक बहु-स्तरीय प्रक्रिया, खतरे और उनका महत्व।
डेटा फ़्यूज़न तकनीकें कई सेंसरों के डेटा और संबद्ध डेटाबेस से संबंधित जानकारी को जोड़ती हैं ताकि अकेले सेंसर के उपयोग से प्राप्त की जा सकने वाली सटीकता और अधिक विशिष्ट अनुमान प्राप्त किए जा सकें।
पी>-
डेटा माइनिंग
डेटा माइनिंग पैटर्न की पहचान करने और संबंध स्थापित करने के लिए डेटा को छांटना है। डेटा माइनिंग को सामूहिक डेटा निष्कर्षण तकनीकों के रूप में संदर्भित किया जाता है जो बड़ी मात्रा में डेटा पर की जाती हैं। डेटा माइनिंग पैरामीटर्स में एसोसिएशन, अनुक्रम विश्लेषण, वर्गीकरण, क्लस्टरिंग और पूर्वानुमान शामिल हैं।
अनुप्रयोगों में ग्राहक डेटा की खोज करना शामिल है ताकि किसी ऑफ़र का जवाब देने की सबसे अधिक संभावना वाले सेगमेंट का निर्धारण किया जा सके, सबसे सफल कर्मचारियों की विशेषताओं की पहचान करने के लिए मानव संसाधन डेटा का खनन किया जा सके, या खरीद व्यवहार को मॉडल करने के लिए बाज़ार टोकरी विश्लेषण शामिल किया जा सके ग्राहकों की।
-
सीखने को समेकित करें
यह मॉडल की स्थिरता और भविष्य कहनेवाला शक्ति में सुधार करने के लिए सीखने के एल्गोरिदम के विविध सेट को एक साथ जोड़ने की एक कला है। यह एक प्रकार की पर्यवेक्षित शिक्षा है।
-
जेनेटिक एल्गोरिथम
इष्टतमीकरण तकनीकें जो प्राकृतिक विकास की अवधारणाओं के आधार पर एक डिजाइन में आनुवंशिक संयोजन, उत्परिवर्तन और प्राकृतिक चयन जैसी प्रक्रियाओं का उपयोग करती हैं। जेनेटिक एल्गोरिदम ऐसी तकनीकें हैं जिनका उपयोग सबसे अधिक देखे जाने वाले वीडियो, टीवी शो और मीडिया के अन्य रूपों की पहचान करने के लिए किया जाता है। एक विकासवादी पैटर्न है जो अनुवांशिक एल्गोरिदम के उपयोग से किया जा सकता है। जेनेटिक एल्गोरिद्म के इस्तेमाल से वीडियो और मीडिया एनालिटिक्स किया जा सकता है।
-
Machine Learning
मशीन लर्निंग एक अन्य तकनीक है जिसका उपयोग श्रेणियों के लिए किया जा सकता है और डेटा के एक विशिष्ट सेट के संभावित परिणाम का निर्धारण किया जा सकता है। मशीन लर्निंग एक ऐसे सॉफ़्टवेयर को परिभाषित करता है जो घटना के एक निश्चित सेट के संभावित परिणामों को निर्धारित करने में सक्षम हो सकता है। इसलिए इसका उपयोग भविष्य कहनेवाला विश्लेषण में किया जाता है। भविष्य कहनेवाला विश्लेषण का एक उदाहरण कानूनी मामले जीतने की संभावना या कुछ प्रस्तुतियों की सफलता है।
-
नेचुरल लैंग्वेज प्रोसेसिंग
कंप्यूटर विज्ञान (ऐतिहासिक रूप से "कृत्रिम बुद्धि" कहे जाने वाले क्षेत्र के भीतर) और भाषाविज्ञान की एक उप-विशेषता से तकनीकों का एक सेट जो मानव (प्राकृतिक) भाषा का विश्लेषण करने के लिए कंप्यूटर एल्गोरिदम का उपयोग करता है। कई एनएलपी तकनीकें मशीन लर्निंग के प्रकार हैं। एनएलपी का एक अनुप्रयोग यह निर्धारित करने के लिए सोशल मीडिया पर भावना विश्लेषण का उपयोग कर रहा है कि ब्रांडिंग अभियान पर संभावित ग्राहक कैसी प्रतिक्रिया दे रहे हैं।
-
तंत्रिका नेटवर्क
गैर-रैखिक भविष्य कहनेवाला मॉडल जो प्रशिक्षण के माध्यम से सीखते हैं और संरचना में जैविक तंत्रिका नेटवर्क के समान होते हैं। उनका उपयोग पैटर्न की पहचान और अनुकूलन के लिए किया जा सकता है। कुछ तंत्रिका नेटवर्क अनुप्रयोगों में पर्यवेक्षित शिक्षण शामिल होता है और अन्य में अप्रशिक्षित शिक्षण शामिल होता है। अनुप्रयोगों के उदाहरणों में उच्च-मूल्य वाले ग्राहकों की पहचान करना शामिल है जो किसी विशेष कंपनी को छोड़ने और धोखाधड़ी वाले बीमा दावों की पहचान करने के जोखिम में हैं।
-
ऑप्टिमाइज़ेशन
संख्यात्मक तकनीकों का एक पोर्टफ़ोलियो जिसका उपयोग जटिल प्रणालियों और प्रक्रियाओं को एक या अधिक वस्तुपरक उपायों (जैसे, लागत, गति, या विश्वसनीयता) के अनुसार उनके प्रदर्शन को बेहतर बनाने के लिए फिर से डिज़ाइन करने के लिए किया जाता है। अनुप्रयोगों के उदाहरणों में शेड्यूलिंग, रूटिंग और फ्लोर लेआउट जैसी परिचालन प्रक्रियाओं में सुधार करना और उत्पाद रेंज रणनीति, लिंक्ड निवेश विश्लेषण और आर एंड डी पोर्टफोलियो रणनीति जैसे सामरिक निर्णय लेना शामिल है। जेनेटिक एल्गोरिदम एक अनुकूलन तकनीक का एक उदाहरण है।
अपने अगले ब्लॉग में, मैं शेष 13 बिग डेटा एनालिटिक्स तकनीकों का वर्णन करूंगा।
-
-
-
-
-
-
-
-
-
-
-


