<पी> एक सॉफ़्टवेयर एप्लिकेशन केवल उतना ही मूल्यवान है जितना वह अपने ग्राहकों की ज़रूरतों को पूरा कर सकता है। जब हम ग्राहकों की जरूरतों पर विचार करते हैं, तो पहली मांग जो हमारे सामने आती है वह है आवेदन की गति और डेटा विश्वसनीयता। हालाँकि, जैसे-जैसे अनुप्रयोग बढ़ते हैं और वैश्विक स्तर पर विस्तार करते हैं, SQL डेटाबेस अक्सर बढ़ी हुई क्वेरी वॉल्यूम, उच्च विलंबता और भौगोलिक रूप से फैले उपयोगकर्ता आधारों के कारण प्रदर्शन बाधा बन जाते हैं। <पी> जब एप्लिकेशन बढ़ता है तो इन समस्याओं का समाधान करने के लिए, बार-बार पूछे जाने वाले प्रश्नों के लिए प्राथमिक डेटाबेस पर लोड को कम करने और उपयोगकर्ताओं द्वारा प्रश्न सबमिट करने पर विलंबता को कम करने के लिए कैशिंग पहला समाधान है। जब हम कैश के बारे में बात करते हैं, तो हममें से प्रत्येक के दिमाग में एक ही टूल आता है, है ना? हाँ, वह रेडिस है। रेडिस लोड को कम करने और एप्लिकेशन को तेज़ बनाने के लिए डेटा को कैशिंग करने के लिए एक आदर्श उपकरण है। अपस्टैश विश्व स्तर पर वितरित रेडिस प्रतिकृति भी प्रदान करता है, जो अनुप्रयोगों को नियमित कैश से भी अधिक तेज़ बना देगा। <पी> इस ब्लॉग में, हम ग्लोबल रेडिस को SQL डेटाबेस के साथ एकीकृत करने के तकनीकी लाभों का पता लगाएंगे, विलंबता और स्केलेबिलिटी पर इसके प्रभाव पर चर्चा करेंगे, और PostgreSQL और MySQL के साथ ग्लोबल रेडिस का उपयोग करने के लिए व्यावहारिक उदाहरण प्रदान करेंगे। कैशिंग के लाभ
<पी> आइए पहले देखें कि हमें कैशिंग का उपयोग क्यों करना चाहिए। <पी> कैशिंग के दो मुख्य लाभ हैं जिनका मैं इस ब्लॉग में उल्लेख करना चाहूंगा:डेटाबेस लोड को कम करना और उपयोगकर्ताओं के लिए विलंबता को कम करना। डेटाबेस लोड कम करना
<पी> SQL डेटाबेस संरचित डेटा और जटिल प्रश्नों को प्रबंधित करने में उत्कृष्ट हैं, लेकिन भारी भार के तहत, वे एक बाधा बन सकते हैं। एक ही डेटा के लिए बार-बार की जाने वाली क्वेरीज़ की उच्च मात्रा - जैसे उत्पाद विवरण, उपयोगकर्ता प्रोफ़ाइल, या बार-बार एक्सेस की गई सेटिंग्स - महत्वपूर्ण CPU और I/O संसाधनों का उपभोग करती हैं। इन परिणामों को कैश करने से, डेटाबेस में आने वाले प्रश्नों की संख्या काफी कम हो जाती है, जिससे डेटाबेस को लेनदेन प्रसंस्करण और अपडेट जैसे अधिक महत्वपूर्ण कार्यों पर ध्यान केंद्रित करने की अनुमति मिलती है। <पी> उदाहरण के लिए: - कैशिंग के बिना:किसी वेबसाइट पर एक लोकप्रिय सुविधा प्रतिदिन लाखों समान डेटाबेस क्वेरी उत्पन्न करती है, जिससे अन्य कार्यों के लिए प्रदर्शन धीमा हो जाता है।
- कैशिंग के साथ:बार-बार एक्सेस किए गए क्वेरी परिणाम रेडिस जैसे हाई-स्पीड कैश में संग्रहीत होते हैं, जिससे डेटाबेस क्वेरी दर 90% से अधिक कम हो जाती है।
विलंबता को कम करना
<पी> डेटा विश्वसनीयता सुनिश्चित करने के लिए डेटाबेस लोड कम करना सिस्टम स्वास्थ्य के लिए था। कैशिंग से उपयोगकर्ता के अनुरोधों और प्रश्नों में लगने वाले समय में भी सुधार होता है। <पी> जब एप्लिकेशन एक ही डेटा के लिए डेटाबेस से बार-बार पूछताछ करते हैं, तो डेटा पुनर्प्राप्ति में हमेशा लंबा समय लगेगा। विशेषकर यदि ये क्वेरीज़ डेटाबेस पर बड़ा भार पैदा करती हैं, तो ये सभी विलंब और भी बढ़ सकते हैं। यह उन अनुप्रयोगों के लिए विशेष रूप से समस्याग्रस्त है, जिन्हें वास्तविक समय डेटा एक्सेस या उच्च क्वेरी वॉल्यूम को संभालने की आवश्यकता होती है, जहां छोटी देरी भी प्रदर्शन को महत्वपूर्ण रूप से प्रभावित कर सकती है। <पी> कैशिंग बार-बार एक्सेस किए गए डेटा को मेमोरी में संग्रहीत करके इस समस्या को हल करता है, जो डेटाबेस को क्वेरी करने की तुलना में पुनर्प्राप्त करने में बहुत तेज़ है। बार-बार अनुरोधों के लिए डेटाबेस प्रश्नों पर निर्भरता को कम करके, कैशिंग नेटवर्क यात्रा को कम करता है और जटिल प्रश्नों को निष्पादित करने के कम्प्यूटेशनल ओवरहेड से बचाता है। परिणामस्वरूप, प्रतिक्रिया समय में नाटकीय रूप से सुधार हुआ है, जिससे एप्लिकेशन भारी लोड के तहत या वितरित वातावरण में भी तेज़, अधिक सुसंगत प्रदर्शन देने में सक्षम हो गए हैं। सामान्य कैशिंग रणनीतियाँ
<पी> एप्लिकेशन प्रदर्शन अनुकूलन में उपयोग की जाने वाली दो प्राथमिक कैशिंग रणनीतियों को समझना भी महत्वपूर्ण है:कैश-एक तरफ और के माध्यम से लिखें . एप्लिकेशन की आवश्यकताओं के आधार पर प्रत्येक दृष्टिकोण के अपने उपयोग के मामले और ट्रेड-ऑफ़ होते हैं। <पी> कैश-एक तरफ सबसे आम कैशिंग तकनीक है. इस तकनीक में, एप्लिकेशन पहले डेटा के लिए कैशे की जांच करता है। यदि डेटा कैश में नहीं है (कैश मिस), तो यह डेटाबेस से डेटा पुनर्प्राप्त करता है और इसे भविष्य में उपयोग के लिए कैश में लिखता है। <पी> यहां एक सरल आरेख है जो दिखाता है कि कैश-एसाइड कैसे काम करता है, हो सकता है कि आप सभी ने इस ब्लॉग पर आने से पहले ही इसे कहीं न कहीं देखा हो। <पी>  <पी> इस कैशिंग का लाभ यह है कि कैश आकार को अनुकूलित किया जाता है, और उपयोगकर्ताओं द्वारा आवश्यकता पड़ने पर कैश डेटा को पुनः लोड किया जाता है। दूसरी ओर, नुकसान यह है कि टीटीएल खत्म होने पर कैश साफ़ होने के बाद डेटा उपलब्ध नहीं होगा। उस समय, जब उपयोगकर्ता उस डेटा का अनुरोध करेगा तो कैश पुनः लोड किया जाएगा। इस स्थिति में, उस उपयोगकर्ता को क्वेरी पूरी होने तक प्रतीक्षा करनी होगी। लेकिन निश्चित रूप से, अगले अनुरोध कैश से डेटा फिर से प्राप्त करने में सक्षम होंगे। <पी> एराइट-थ्रूमें रणनीति, डेटाबेस में प्रत्येक लिखने का ऑपरेशन तुरंत कैश में भी लिखा जाता है। यह सुनिश्चित करता है कि कैश हमेशा डेटाबेस के नवीनतम डेटा के साथ अद्यतित रहता है। <पी> यहां राइट-थ्रू कैशिंग का एक सरल आरेख है: <पी>
<पी> इस कैशिंग का लाभ यह है कि कैश आकार को अनुकूलित किया जाता है, और उपयोगकर्ताओं द्वारा आवश्यकता पड़ने पर कैश डेटा को पुनः लोड किया जाता है। दूसरी ओर, नुकसान यह है कि टीटीएल खत्म होने पर कैश साफ़ होने के बाद डेटा उपलब्ध नहीं होगा। उस समय, जब उपयोगकर्ता उस डेटा का अनुरोध करेगा तो कैश पुनः लोड किया जाएगा। इस स्थिति में, उस उपयोगकर्ता को क्वेरी पूरी होने तक प्रतीक्षा करनी होगी। लेकिन निश्चित रूप से, अगले अनुरोध कैश से डेटा फिर से प्राप्त करने में सक्षम होंगे। <पी> एराइट-थ्रूमें रणनीति, डेटाबेस में प्रत्येक लिखने का ऑपरेशन तुरंत कैश में भी लिखा जाता है। यह सुनिश्चित करता है कि कैश हमेशा डेटाबेस के नवीनतम डेटा के साथ अद्यतित रहता है। <पी> यहां राइट-थ्रू कैशिंग का एक सरल आरेख है: <पी>  <पी> यह रणनीति कैश और डेटाबेस के बीच डेटा स्थिरता सुनिश्चित करती है और किसी भी अनुरोध में उच्च विलंबता का अनुभव नहीं होता है क्योंकि उपयोगकर्ता से अनुरोध की प्रतीक्षा किए बिना डेटा पहले से ही उपलब्ध होगा। हालाँकि, नुकसान यह है कि कैश में सारा डेटा होता है, भले ही इसकी आवश्यकता न हो। इसके अलावा, प्रत्येक लेखन ऑपरेशन में विलंबता प्राप्त होगी क्योंकि डेटा कैश में भी लिखा जाएगा।
<पी> यह रणनीति कैश और डेटाबेस के बीच डेटा स्थिरता सुनिश्चित करती है और किसी भी अनुरोध में उच्च विलंबता का अनुभव नहीं होता है क्योंकि उपयोगकर्ता से अनुरोध की प्रतीक्षा किए बिना डेटा पहले से ही उपलब्ध होगा। हालाँकि, नुकसान यह है कि कैश में सारा डेटा होता है, भले ही इसकी आवश्यकता न हो। इसके अलावा, प्रत्येक लेखन ऑपरेशन में विलंबता प्राप्त होगी क्योंकि डेटा कैश में भी लिखा जाएगा। ग्लोबल रेडिस क्या है? ग्लोबल रेडिस के लाभ
<पी> आइए अब जांच करें कि SQL डेटाबेस के प्रदर्शन को और कैसे बेहतर बनाया जाए। <पी> विलंबता का एक अन्य स्रोत डेटाबेस का स्थान है। अधिकांश मामलों में, प्राथमिक डेटाबेस विशिष्ट क्षेत्रों में स्थित होता है। हालाँकि, डेटा निकटतम स्थान पर पहुंच योग्य होना चाहिए ताकि हम डेटा स्टोर की दूरी के कारण होने वाली देरी को कम कर सकें। <पी> अपस्टैश द्वारा प्रदान की गई विश्व स्तर पर वितरित रेडिस का उपयोग करके इस समस्या को रोका जा सकता है। <पी> ग्लोबल रेडिस एक वितरित कैशिंग समाधान है जो कई भौगोलिक स्थानों पर डेटा की प्रतिकृति बनाता है, जिससे विश्व स्तर पर वितरित अनुप्रयोगों के लिए कम-विलंबता पहुंच सुनिश्चित होती है। <पी> आइए जल्दी से देखें कि वैश्विक रेडिस कैसे बनाया जाए। सबसे पहले, अपस्टैश कंसोल में लॉग इन करें। <पी> लॉगिन करने के बाद, हम यहां एक रेडिस डेटाबेस बना सकते हैं। अपस्टैश पढ़ी गई प्रतिकृतियों का पता लगाने के लिए कई स्थान प्रदान करता है। <पी> 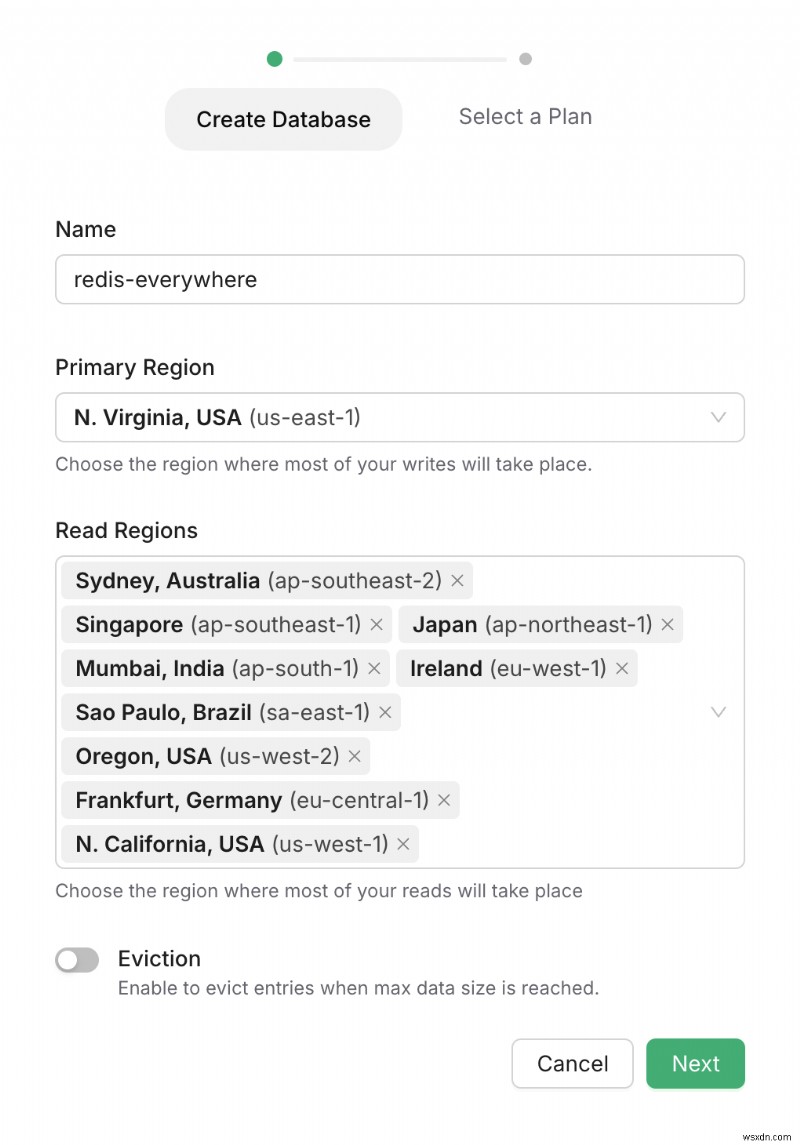 <पी> एक बार पढ़े गए स्थानों का चयन करने के बाद, आप अपनी योजना का चयन कर सकते हैं और अंत में अपना रेडिस डेटाबेस बना सकते हैं। बस इतना ही! <पी> कंसोल में, आप डेटाबेस बनाने के बाद क्षेत्रों को जोड़/हटा भी सकते हैं। <पी>
<पी> एक बार पढ़े गए स्थानों का चयन करने के बाद, आप अपनी योजना का चयन कर सकते हैं और अंत में अपना रेडिस डेटाबेस बना सकते हैं। बस इतना ही! <पी> कंसोल में, आप डेटाबेस बनाने के बाद क्षेत्रों को जोड़/हटा भी सकते हैं। <पी>  <पी> ग्लोबल रेडिस डेटाबेस का उपयोग ज्यादातर उन अनुप्रयोगों द्वारा किया जाता है जो विश्व स्तर पर वितरित हैं और वे अनुप्रयोग जो किनारे पर चल रहे हैं।
<पी> ग्लोबल रेडिस डेटाबेस का उपयोग ज्यादातर उन अनुप्रयोगों द्वारा किया जाता है जो विश्व स्तर पर वितरित हैं और वे अनुप्रयोग जो किनारे पर चल रहे हैं। विश्व स्तर पर वितरित अनुप्रयोगों के लिए कम विलंबता
<पी> विश्व स्तर पर वितरित प्रणालियों में, उपयोगकर्ताओं और केंद्रीय डेटाबेस या कैश के बीच भौतिक दूरी के कारण विलंबता अक्सर एक बाधा बन जाती है। ग्लोबल रेडिस कई भौगोलिक रूप से वितरित नोड्स में डेटा की प्रतिकृति बनाकर इसका समाधान करता है। <पी> जब कोई उपयोगकर्ता डेटा का अनुरोध करता है, तो निकटतम कैश नोड अनुरोध को पूरा करता है, जिससे नेटवर्क यात्रा का समय काफी कम हो जाता है। यह स्थानीयकृत पहुंच उपयोगकर्ता के स्थान की परवाह किए बिना तेज़ प्रतिक्रिया समय और एक सुसंगत उपयोगकर्ता अनुभव सुनिश्चित करती है। <पी> मान लीजिए, यदि कोई उपयोगकर्ता टोक्यो में स्थित है, लेकिन डेटाबेस डबलिन में है, तो दूरी उपयोगकर्ता को प्रतिक्रिया देने में देरी करेगी। यदि यूरोप में अपस्टैश रेडिस की पढ़ी गई प्रतिकृति है, तो अनुरोध को निकटतम पढ़ी गई प्रतिकृति पर भेजा जा सकता है, जो इस मामले में यूरोप में है। एज रनटाइम के लिए कम विलंबता डेटा (उदाहरण के लिए क्लाउडफ़ेयर वर्कर्स)
<पी> एज रनटाइम ऐसे वातावरण हैं जिन्हें अंतिम उपयोगकर्ता के करीब, नेटवर्क के किनारे पर कोड निष्पादित करने के लिए डिज़ाइन किया गया है। एज रनटाइम दुनिया भर में कई किनारे स्थानों पर एप्लिकेशन लॉजिक वितरित करता है। यह आर्किटेक्चर उपयोगकर्ताओं और उनके अनुरोधों के निष्पादन के बीच भौतिक दूरी को कम करता है, विलंबता को काफी कम करता है और प्रदर्शन में सुधार करता है। <पी> जबकि एज रनटाइम गणना को उपयोगकर्ताओं के करीब लाते हैं, फिर भी उन्हें अधिकांश ऑपरेशनों के लिए डेटा तक पहुंच की आवश्यकता होती है, जैसे उपयोगकर्ता-विशिष्ट जानकारी, सत्र टोकन या कॉन्फ़िगरेशन पुनर्प्राप्त करना। कैशिंग परत के बिना, प्रत्येक अनुरोध को अभी भी एक केंद्रीय डेटाबेस के लिए एक राउंड ट्रिप की आवश्यकता होगी, जिससे अधिकांश विलंबता लाभ समाप्त हो जाएगा। यहीं पर ग्लोबल रेडिस एक महत्वपूर्ण भूमिका निभाते हैं, क्योंकि वे कम-विलंबता पहुंच सुनिश्चित करते हुए बार-बार उपयोग किए जाने वाले डेटा को किनारे पर दोहराते हैं। उदाहरण कोड 1:Node.js के साथ PostgreSQL
<पी> वैश्विक रेडिस के साथ कैशिंग उत्तम है। अब, हम एक कोड नमूना देखेंगे जो अपस्टैश रेडिस और पोस्टग्रेस्क्ल डेटाबेस के साथ कैश-असाइड रणनीति को लागू करता है। <पी> हमें पहले एसडीके इंस्टॉल करना चाहिए जिसका उपयोग हम डेटा स्टोर से कनेक्ट करने के लिए करेंगे। npm install pg upstash/redis
<पी> एक बार जब हमारे पास निर्भरताएँ स्थापित हो जाती हैं, तो हम डेटा स्टोर, अपस्टैश रेडिस और पोस्टग्रेज़ से जुड़ सकते हैं। const { Redis } = require('@upstash/redis'); // Upstash Redis SDK
const { Client } = require('pg');
const redis = new Redis({
url: <UPSTASH_REDIS_REST_URL>,
token: <UPSTASH_REDIS_REST_TOKEN>,
})
const client = new Client({
user: 'username',
password: 'password',
host: 'host',
port: 'port_number',
database: 'database_name',
});
client.connect();
<पी> आइए अब अपने डेटा एक्सेस लेयर में फ़ंक्शन लिखें। इस फ़ंक्शन को आपकी आवश्यकताओं के अनुसार संशोधित किया जा सकता है। <पी> मान लीजिए कि हम अपनी वेबसाइट पर यूजर आईडी द्वारा उपयोगकर्ता की जानकारी दिखाना चाहते हैं। इस मामले में, हमारे पास एक फ़ंक्शन होना चाहिए जो उपयोगकर्ता आईडी को पैरामीटर के रूप में प्राप्त करता है async function getUserData(userId) {
// Check cache first
const cachedData = await redis.get(userId);
if (cachedData) {
console.log('Cache hit');
return JSON.parse(cachedData);
}
// Fallback to database
console.log('Cache miss');
const query = 'SELECT * FROM users WHERE id = $1';
const { rows } = await client.query(query, [userId]);
await redis.set(userId, JSON.stringify(rows), { EX: 300 }); // Cache for 5 minutes
return rows;
}
<पी> यह यहाँ है! अब यह फ़ंक्शन पहले जांच करेगा कि उपयोगकर्ता की जानकारी अनुरोधकर्ता के क्षेत्र के निकटतम रेडिस डेटाबेस में उपलब्ध है या नहीं। यदि यह उपलब्ध नहीं है, तो यह Postgresql डेटाबेस से अनुरोधित डेटा को क्वेरी करेगा और लौटाए गए डेटा को अपस्टैश रेडिस प्राथमिक क्षेत्र में लिखेगा। प्राथमिक क्षेत्र में लिखा गया डेटा स्वचालित रूप से सभी पढ़ी गई प्रतिकृतियों में कॉपी हो जाएगा। उदाहरण कोड 2:पायथन के साथ MYSQL
<पी> अब, आइए एक और उदाहरण देखें। इस बार, हम वही कैश कार्यान्वयन करेंगे, लेकिन इस बार मुख्य डेटाबेस MYSQL होगा। साथ ही, हम इस फ़ंक्शन को पायथन में लिखेंगे ताकि यह देख सकें कि यह पायथन-आधारित अनुप्रयोगों में कैसे काम करता है। <पी> हमेशा की तरह, हम पहले उन निर्भरताओं को डाउनलोड करेंगे जिनका उपयोग हम डेटाबेस को जोड़ने के लिए करेंगे। pip install upstash-redis upstash-redis
<पी> अब, हम ग्राहकों को इनिशियलाइज़ कर सकते हैं और उन्हें कनेक्ट कर सकते हैं। import upstash_redis
import mysql.connector
import json
# Initialize Upstash Redis client
redis_client = upstash_redis.Redis(
url='<your-upstash-redis-url>',
token='<your-upstash-token>'
)
# Initialize MySQL client
db = mysql.connector.connect(
host="<your-mysql-host>",
user="<your-mysql-user>",
password="<your-mysql-password>",
database="<your-database-name>"
)
cursor = db.cursor(dictionary=True)
<पी> कनेक्शन तैयार हैं. अब हम वही फ़ंक्शन लागू करेंगे जो हमने पिछले अनुभाग में लागू किया था। def get_user_data(userId):
# Check the cache for the data
cache_data = redis_client.get(key)
if cache_data:
print("Cache hit")
return json.loads(cache_data)
# If cache miss, query the MySQL database
print("Cache miss")
cursor.execute("SELECT * FROM users WHERE key = %s", (userId))
result = cursor.fetchone()
if result:
# Store the data in the cache with a TTL of 1 hour
redis_client.set(key, json.dumps(result), ex=3600)
return result
निष्कर्ष
<पी> ग्लोबल रेडिस को अपने आर्किटेक्चर में एकीकृत करके, आप SQL-आधारित अनुप्रयोगों के लिए महत्वपूर्ण प्रदर्शन लाभ प्राप्त कर सकते हैं, विशेष रूप से विश्व स्तर पर वितरित वातावरण में। कम-विलंबता पहुंच, कम डेटाबेस लोड और एज रनटाइम के साथ अनुकूलता के साथ, ग्लोबल रेडिस SQL डेटाबेस के साथ अनुप्रयोगों की प्रदर्शन चुनौतियों का समाधान कर सकता है। <पी> इस ब्लॉग पोस्ट में, हमने वैश्विक रेडिस के साथ कैशिंग के लाभों के बारे में जाना और कुछ उदाहरणों की जांच की। ये केवल बुनियादी उदाहरण थे जिन्हें आपकी आवश्यकताओं के आधार पर और अधिक बढ़ाया जा सकता है। <पी> मुझे आशा है कि वैश्विक रेडिस की शक्ति का लाभ उठाने के लिए यह ब्लॉग आपके लिए एक अच्छी शुरुआत हो सकता है।