<पी> क्या आपने कभी देखा है कि जैसे ही आप टाइप करते हैं तो खोज बॉक्स कैसे शब्द सुझाते हैं? पता चला, इनमें से अधिकतर सुझाव सरल वर्णमाला क्रम में दिखाई देते हैं और बहुत उपयोगी नहीं हैं। <पी> लेकिन क्या होगा यदि एक खोज बॉक्स समय के साथ और अधिक स्मार्ट हो जाए? <पी> लोग वास्तव में किस पर क्लिक करते हैं उससे सीखना और सबसे लोकप्रिय परिणाम पहले दिखाना? <पी> हम यही बनाएंगे: <पी> हम देखेंगे कि रेडिस सॉर्टेड सेट एक बुद्धिमान स्वत:पूर्ण प्रणाली को कैसे शक्ति प्रदान कर सकता है जो उपयोगकर्ता के व्यवहार से सीखता है और समय के साथ अधिक सटीक (पहले लोकप्रिय परिणाम दिखाता है) बन जाता है। स्मार्ट ऑटोकम्प्लीट सिस्टम का विचार
<पी> कौन सा परिणाम पहले दिखाना है यह तय करने के लिए एक बुनियादी खोज बॉक्स उपसर्ग मिलान नामक विधि का उपयोग करेगा। <पी> जैसे ही आप टाइप करते हैं, यह A-Z क्रम में मिलान दिखाता है। यह वास्तव में इसकी परवाह नहीं करता कि लोग वास्तव में किस परिणाम पर सबसे अधिक क्लिक करते हैं। <पी> हम इसे और अधिक स्मार्ट बनाने जा रहे हैं। हमारा खोज बॉक्स इससे सीखेगा कि लोग क्या चुनते हैं . जब लोग किसी खोज परिणाम पर क्लिक करेंगे, तो हम अगली बार सबसे पहले वह परिणाम दिखाएंगे। <पी> इसका मतलब है कि हमारी खोज समय के साथ सबसे लोकप्रिय परिणामों को शीर्ष पर स्वचालित रूप से दिखाकर बेहतर और अधिक उपयोगी हो जाती है। यह खोज अनुप्रयोगों के लिए क्यों महत्वपूर्ण है
<पी> मूवी खोज एप्लिकेशन पर विचार करें:जब उपयोगकर्ता "int" टाइप करते हैं। वे देख सकते हैं: - "इंटरसेप्टर"
- "अंतरराज्यीय 60"
- "इंटरस्टेलर"
<पी> एक "पारंपरिक" प्रणाली में, ये वर्णानुक्रम में दिखाई देंगे। हालाँकि, यदि उपयोगकर्ता लगातार "इंटरस्टेलर" पर क्लिक करते हैं, तो हम इसे स्वत:पूर्ण सुझावों के शीर्ष पर प्रचारित करना चाहेंगे। <पी> 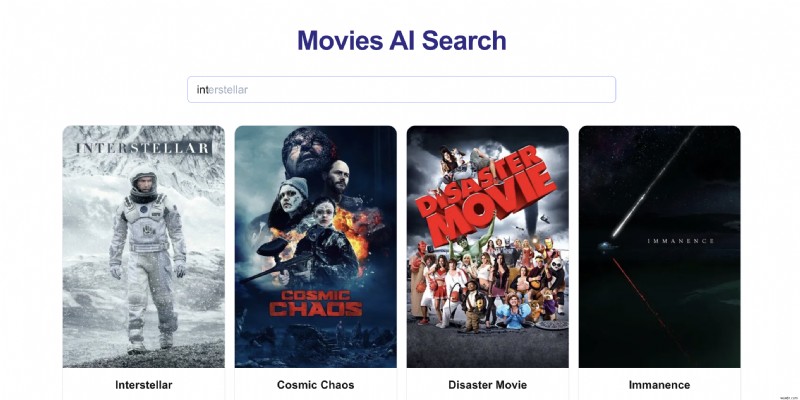 <पी> यह स्मार्ट रैंकिंग प्रणाली इसके लिए वास्तव में अच्छी तरह से काम करती है:
<पी> यह स्मार्ट रैंकिंग प्रणाली इसके लिए वास्तव में अच्छी तरह से काम करती है: - स्ट्रीमिंग सेवाएं नेटफ्लिक्स या यूट्यूब की तरह यह दिखाने के लिए कि लोग सबसे ज्यादा क्या देख रहे हैं
- ऑनलाइन स्टोर खोजते समय सबसे पहले लोकप्रिय उत्पाद दिखाएं
- सहायता केंद्र लोगों द्वारा पूछे जाने वाले सबसे सामान्य प्रश्न दिखाने के लिए
- खोज वाली कोई भी वेबसाइट यह दिखाने के लिए कि अधिकांश लोग पहले किस पर क्लिक करते हैं
रेडिस सॉर्टेड सेट को समझना
<पी> आइए समझें कि रेडिस सॉर्टेड सेट स्वत:पूर्ण सिस्टम बनाने के लिए क्यों अच्छे हैं। <पी> रेडिस सॉर्टेड सेट एक स्मार्ट सूची की तरह है जहां: - प्रत्येक आइटम अद्वितीय है (एक सेट की तरह)
- प्रत्येक आइटम का एक स्कोर होता है (ऑर्डर करने के लिए)
- आइटम को उनके स्कोर के आधार पर तुरंत क्रमबद्ध किया जा सकता है
<पी> अपने स्वत:पूर्ण सिस्टम के लिए, हम दो क्रमबद्ध सेट का उपयोग करेंगे: - पाठ उपसर्गों के मिलान के लिए एक (उदाहरण के लिए "int" "इंटरस्टेलर" से मेल खाता है)
- प्रत्येक सुझाव कितना लोकप्रिय है, इस पर नज़र रखने के लिए एक और
<पी> ये दोनों सेट उपयोगकर्ताओं के टाइप करते ही सबसे प्रासंगिक परिणाम सुझाने के लिए एक साथ काम करते हैं। आधार:वर्णमाला क्रम
<पी> जब सभी सदस्यों का स्कोर समान होता है तो रेडिस सॉर्टेड सेट वर्णानुक्रमिक क्रम बनाए रखते हैं। यह खोज सुझाव बनाने के लिए एकदम सही है क्योंकि यह हमें इसकी सुविधा देता है: - सभी उपसर्गों को संग्रहीत करें एकल डेटा संरचना में खोजने योग्य शब्द
ZRANK का उपयोग करें O(log N) समय में किसी भी उपसर्ग की प्रारंभिक स्थिति ज्ञात करने के लिएZSCAN का उपयोग करें उस स्थिति से शुरू होने वाले सभी मैचों को कुशलतापूर्वक पुनः प्राप्त करने के लिएZMSCORE का उपयोग करें प्रत्येक मैच का लोकप्रियता स्कोर प्राप्त करने के लिएZINCRBY का उपयोग करें प्रत्येक मैच का लोकप्रियता स्कोर बढ़ाने के लिए
<पी> आइए एक सरल उदाहरण देखें. जब हम फिल्म "इंटरस्टेलर" को अपने खोज सिस्टम में जोड़ते हैं, तो हम इसे इस प्रकार विभाजित करते हैं: - स्कोर:0, सदस्य:"मैं"
- स्कोर:0, सदस्य:"IN"
- स्कोर:0, सदस्य:"INT"
- स्कोर:0, सदस्य:"INTE"
- स्कोर:0, सदस्य:"इंटर"
- स्कोर:0, सदस्य:"इंटरस्टेलर$इंटरस्टेलर" (प्रदर्शन प्रारूप के साथ पूर्ण प्रविष्टि)
<पी> देखें कि हम $ का उपयोग कैसे करते हैं खोज संस्करण को प्रदर्शन संस्करण से विभाजित करने के लिए? इस तरह, उपयोगकर्ता अपरकेस या लोअरकेस अक्षरों के बारे में चिंता किए बिना खोज सकते हैं, लेकिन हम अभी भी फिल्म का शीर्षक बिल्कुल वैसा ही दिखाते हैं जैसा उसे दिखना चाहिए। हम डेटा कैसे संग्रहीत करते हैं
<पी> हम अपना स्वत:पूर्ण कार्य करने के लिए दो रेडिस सॉर्ट किए गए सेट का उपयोग करते हैं: 1. मूवी शीर्षक सूची
<पी> आइए movies नामक क्रमबद्ध सेट का ट्रैक रखें . इसे एक शब्दकोश की तरह समझें जो हमें फिल्में तुरंत ढूंढने में मदद करता है। जब कोई "int" टाइप करता है, तो हम तुरंत उन सभी फिल्मों को ढूंढ सकते हैं जो उन अक्षरों से शुरू होती हैं। <पी> "int" की पहली घटना ZRANK द्वारा पाई जाएगी और फिर उस स्थिति से शुरू करके वाइल्ड कार्ड INT*$* के साथ पूरी फिल्म के नाम लाया जाएगा. 2. लोकप्रिय फ़िल्मों की सूची
<पी> आइए movie-popularity नामक क्रमबद्ध सेट पर भी नज़र रखें . यह हमारी "ट्रेंडिंग फ़िल्में" सूची है। <पी> जब भी कोई खोज परिणामों में किसी फिल्म पर क्लिक करता है, तो वह फिल्म ZINCRBY का उपयोग करके अपना स्कोर बढ़ाकर अधिक लोकप्रिय हो जाती है। . सर्वाधिक क्लिक की गई फिल्में भविष्य की खोजों में सबसे पहले दिखाई देती हैं। <पी> यह वैसा ही है जैसे नेटफ्लिक्स आपको ट्रेंडिंग फिल्में दिखाता है - जितने अधिक लोग किसी चीज़ को देखते हैं, वह अनुशंसाओं में उतनी ही अधिक दिखाई देती है। <पी> हमारे मामले में, INT*$* के सटीक मिलान का पता लगाने के बाद , हम जाते हैं और movie-popularity पर उनके स्कोर की जांच करते हैं सर्वाधिक लोकप्रिय प्राप्त करने के लिए। एल्गोरिदमिक प्रवाह
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> A
<पी> जैसे ही उपयोगकर्ता खोजते हैं और सुझावों पर क्लिक करते हैं, सिस्टम सीखता है और सुधार करता है। जितने अधिक लोग इसका उपयोग करेंगे, यह सबसे प्रासंगिक सुझावों को पहले दिखाने में उतना ही बेहतर हो जाएगा। आइए स्वत:पूर्ण सिस्टम बनाएं
<पी> आइए देखें कि हम चरण दर चरण इस स्वत:पूर्ण प्रणाली का निर्माण कैसे करते हैं। हम इसे अत्यंत सरल रखेंगे! चरण 1:Redis में मूवी शीर्षक जोड़ना
<पी> सबसे पहले, हमें अपनी मूवी के शीर्षक Redis में जोड़ने होंगे ताकि हम उन्हें बाद में खोज सकें। आप कहीं से भी फिल्मों की एक सरल सूची से शुरुआत कर सकते हैं - शायद आपका डेटाबेस या सिर्फ एक टेक्स्ट फ़ाइल। यहां बताया गया है कि हम उन्हें कैसे जोड़ते हैं: import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();
<पी> आइए देखें कि उपरोक्त कोड क्या करता है: - <पी> प्रत्येक फिल्म के शीर्षक के लिए, हम संग्रहित करते हैं:
- सभी संभावित आंशिक मिलान (जैसे "INT", "INTE", "इंटर" के लिए "इंटरस्टेलर")
- पूरा शीर्षक ही
- प्रदर्शन के लिए एक स्वरूपित संस्करण
- <पी> हम एक अलग सूची भी बनाते हैं जो ट्रैक करती है कि प्रत्येक फिल्म कितनी लोकप्रिय है, शून्य दृश्य से शुरू होकर
<पी> यह हमें वह सब कुछ देता है जो हमें उपयोगकर्ताओं के टाइप करते समय स्मार्ट सुझाव दिखाने और उनके द्वारा क्लिक किए जाने पर सीखने के लिए चाहिए। चरण 2:सर्वोत्तम मिलान ढूँढना
<पी> इसके बाद, हम देखेंगे कि हम इन मूवी शीर्षकों के माध्यम से मिलान कैसे खोजते हैं। हमारा matchQuery फ़ंक्शन सभी भारी सामान उठाता है: export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};
उपयोगकर्ता की पसंद से सीखना
<पी> जब कोई फिल्म का शीर्षक चुनता है, तो हम उसके स्कोर में 1 अंक जोड़ते हैं। अधिक अंक वाली फिल्में सुझाव सूची में ऊपर दिखाई देती हैं। यह इतना आसान है! <पी> लोग वास्तव में क्या चुनते हैं, इस पर नज़र रखते हुए सिस्टम समय के साथ स्मार्ट होता जाता है। const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};
यह कितना तेज़ है?
<पी> आइए देखें कि प्रत्येक ऑपरेशन में लगने वाले समय को तोड़कर यह समाधान कितना तेज़ है: - ZRANK :O(लॉग एन) - लॉगरिदमिक लुकअप समय
- ZSCAN :O(लॉग एन + एम) - जहां एम लौटाए गए तत्वों की संख्या है
- ZMSCORE :O(N) - जहां N मिलान किए गए परिणामों की संख्या है, न कि कुल डेटासेट आकार
- ZINCRBY :O(लॉग एन) - लघुगणकीय जटिलता के साथ परमाणु वृद्धि
<पी> जैसे-जैसे हम अधिक मूवी शीर्षक जोड़ते हैं, प्रदर्शन सुसंगत रहता है। निष्कर्ष:हमने मिलकर क्या बनाया
<पी> आपने अभी-अभी सीखा है कि एक स्मार्ट खोज बॉक्स कैसे बनाया जाता है जो बिना किसी AI के समय के साथ बेहतर होता जाता है! <पी> हमारा स्वत:पूर्ण लोग जो चुनते हैं उससे सीखता है और बेहतर सुझाव दिखाने के लिए उस जानकारी का उपयोग करता है। <पी> यह तेज़, सरल है और जैसे-जैसे अधिक लोग इसका उपयोग करते हैं, यह और अधिक उपयोगी होता जाता है। <पी> क्या आप रेडिस अनुकूलन रणनीतियों के बारे में बात करना चाहते हैं या अपने स्वयं के कार्यान्वयन साझा करना चाहते हैं? डिस्कोर्ड पर हमसे जुड़ें!

![[समीक्षा] अंतरिक्ष आक्रमणकारियों को वैनिला जावास्क्रिप्ट में कोडित किया गया (एंड्रिया मेल द्वारा)](/article/uploadfiles/202203/2022033109362589_S.jpg)