एआई अनुसंधान एजेंटों का परिचय
<पी> शैक्षणिक अनुसंधान तेजी से आगे बढ़ता है—arXiv और अन्य प्री-प्रिंट सर्वर पर हर दिन नए पेपर दिखाई देते हैं। मैन्युअल रूप से रखना भारी पड़ सकता है। इस गाइड में, हम एक AI अनुसंधान सहायक बनाएंगे वह: - शोधकर्ता के प्राकृतिक-भाषा प्रश्न को समझता है
- arXiv सार के वेक्टर डेटाबेस में सबसे अधिक प्रासंगिक कागजात ढूँढता है
- मुख्य जानकारियों का सारांश देता है और बताता है कि वे प्रश्न का उत्तर कैसे देते हैं
- गहराई से पढ़ने के लिए एक सीधा पीडीएफ लिंक प्रदान करता है
<पी> हम इसेमस्त्रके साथ पूरा करेंगे , एआई एजेंटों के निर्माण के लिए एक ओपन-सोर्स टाइपस्क्रिप्ट ढांचा, और अपस्टैश सर्वर रहित रेडिस और वेक्टर स्टोरेज के लिए। यहां एआई अनुसंधान पर केंद्रित हमारे लेख एजेंट का लाइव डेमो है। इसे आपके आज़माने के लिए वर्सेल पर तैनात किया गया है। <पी> 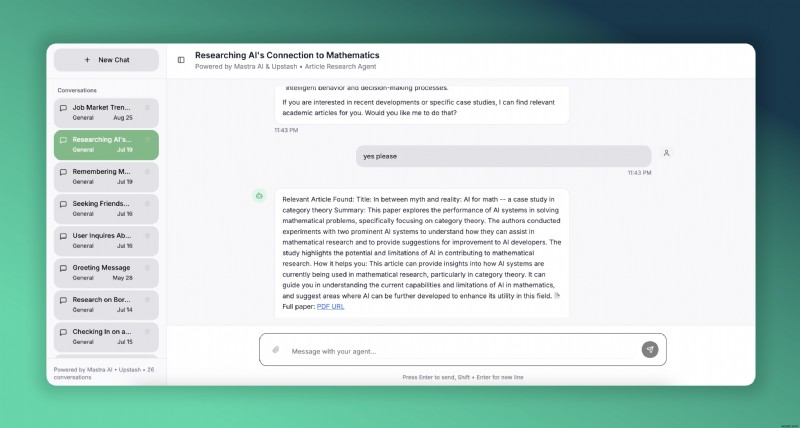
मस्त्रा क्या है?
<पी> मास्ट्रा एक बैटरी-युक्त ढांचा है जो उत्पादन-ग्रेड एआई एजेंटों को बनाना आसान बनाता है। - एजेंट और वर्कफ़्लो - एजेंट, टूल और मल्टी-स्टेप वर्कफ़्लोज़ लिखें
- पुनर्प्राप्ति-संवर्धित पीढ़ी (आरएजी) - अंतर्निहित मेमोरी और वेक्टर स्टोर
- मल्टी-एलएलएम - OpenAI, क्लाउड और अन्य के साथ काम करता है।
<पी> हम एक एजेंट बनाएंगे जो मेमोरी के लिए अपस्टैश रेडिस का उपयोग करेगा। इसमें प्रासंगिक शोध लेख ढूंढने के लिए एक टूल भी होगा, जिसे हमने पहले अपस्टैश वेक्टर डेटाबेस में एम्बेड किया होगा। <पी> अधिक गहराई से जानने के लिए, मास्ट्रा दस्तावेज़ देखें। परियोजना के लिए तकनीकी स्टैक
- मस्ट्रा फ्रेमवर्क एआई एजेंट और टूल बनाने के लिए
- अपस्टैश रेडिस एजेंट को बातचीत की स्मृति देने के लिए
- अपस्टैश वेक्टर अनुसंधान लेख सार के एम्बेडिंग को संग्रहीत करने के लिए
- Next.js और Vercel वेब एप्लिकेशन बनाने और तैनात करने के लिए
<पी> हम अपने डेमो एप्लिकेशन के अनुरोधों को सीमित करने के लिए अपस्टैश रेटलिमिट का भी उपयोग करेंगे। कार्यान्वयन पूर्वाभ्यास
<पी> इस एप्लिकेशन के निर्माण में दो मुख्य घटक बनाना शामिल है:मास्ट्रा सर्वर और वेब एप्लिकेशन। हालाँकि वे एक ही प्रोजेक्ट में हो सकते हैं, लेकिन उन्हें अलग रखना बेहतर है। आइए मास्ट्रा सर्वर से शुरुआत करें। मस्ट्रा प्रोजेक्ट बनाना
<पी> एक नया मास्ट्रा प्रोजेक्ट बनाने के लिए, अपने टर्मिनल में निम्नलिखित कमांड चलाएँ। npm create mastra@latest
<पी> यह कुछ प्रश्न पूछेगा; इस प्रोजेक्ट के लिए, डिफ़ॉल्ट सेटिंग्स ठीक हैं। एजेंट और टूल बनाना
<पी> किसी एजेंट को कॉन्फ़िगर करने में पहला कदम उसका नाम, उद्देश्य और उपकरण परिभाषित करना है। ऐसा भाषा मॉडल चुनना भी महत्वपूर्ण है जो दिए गए कार्यों के लिए अच्छा प्रदर्शन करेगा। इस प्रोजेक्ट में, हमारे पास एक एजेंट और एक टूल होगा। export const articleAgent = new Agent({
name: "articleAgent",
instructions: instruction,
model: openai('gpt-4o'),
tools: { articleQueryTool },
memory: memory
});
<पी> किसी एजेंट को कॉन्फ़िगर करना उतना ही सरल है जितना ऊपर दिखाया गया है। हम अपने आर्टिकलएजेंट को परिभाषित करते हैं instruction के साथ (जो एक सिस्टम प्रॉम्प्ट के रूप में कार्य करता है), यह समर्पित tools है , model , और एक अन्य महत्वपूर्ण घटक:memory . एजेंट की मेमोरी
<पी> मास्ट्रा एजेंटों को चैट इतिहास और सिमेंटिक रिकॉल क्षमताएं दोनों प्रदान करता है। भंडारण में स्मृति बनाए रखकर, एजेंट अधिक वैयक्तिकृत और सटीक उत्तर प्रदान कर सकता है। आइए हमारे एजेंट की मेमोरी कॉन्फ़िगरेशन को देखें। export const memory = new Memory({
storage: myUpstashStore,
options: {
lastMessages: 10,
semanticRecall: false,
threads: {
generateTitle: true
}
}
});
<पी> चैट इतिहास को सक्षम करने के लिए, हम अपने स्टोरेज विकल्प के रूप में अपस्टैश रेडिस का उपयोग करते हैं। हम इसे UpstashStore के रूप में प्रारंभ करते हैं ऑब्जेक्ट, जो MastraStorage का विस्तार करता है , यह सुनिश्चित करते हुए कि यह हमारे मास्ट्रा एजेंट के साथ निर्बाध रूप से काम करता है। export const myUpstashStore = new UpstashStore({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});
<पी> हमने पहले अपने एजेंट में सिमेंटिक रिकॉल फीचर जोड़ने का उल्लेख किया था, जो उसे वर्तमान संदर्भ से संबंधित पिछले संदेशों पर विचार करने की अनुमति देता है। इसके लिए, एजेंट को संदेशों को संसाधित करने के लिए एक वेक्टर डेटाबेस और एक एम्बेडर की आवश्यकता होती है। चूँकि हमारा सार्वजनिक डेमो व्यक्तिगत उपयोग के लिए नहीं है और विभिन्न थ्रेड्स में संदेशों को याद रखने की आवश्यकता नहीं है, हम इस सुविधा का उपयोग नहीं करेंगे, लेकिन इसे निम्नानुसार लागू किया जा सकता है। export const myUpstashVector = new UpstashVector({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
});
export const memory = new Memory({
storage: myUpstashStore,
vector: myUpstashVector,
embedder: openai.embedding("text-embedding-3-small"),
options: {
lastMessages: 10,
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource'
},
threads: {
generateTitle: true
}
}
});
<पी> सिमेंटिक रिकॉल कॉन्फ़िगरेशन में, topK पुनर्प्राप्त करने के लिए समान संदेशों की संख्या निर्दिष्ट करता है, messageRange यह परिभाषित करता है कि प्रत्येक मैच में कितना आसपास का संदर्भ शामिल करना है, और सेटिंग स्कोप 'संसाधन' एजेंट को 'संसाधन' नाम के उपयोगकर्ता से जुड़े सभी थ्रेड्स में खोज करने देता है। यह क्रॉस-थ्रेड मेमोरी अपस्टैश के साथ उपलब्ध एक शक्तिशाली मेमोरी है। उपकरण
<पी> एक टूल बनाना एक एजेंट बनाने जितना ही सरल है। जब एजेंट को टूल की क्षमताओं की आवश्यकता होती है तो हम एक नाम, विवरण, इनपुट और आउटपुट स्कीमा और निष्पादित करने के लिए एक फ़ंक्शन प्रदान करते हैं। export const articleQueryTool = createTool({
id: 'get-relevant-article',
description: 'Get relevant article information',
inputSchema: z.object({
question: z.string().describe('the question about the field'),
}),
outputSchema: z.object({
bestOption: z.object({
abstract: z.string().describe('the abstract of the article'),
title: z.string().describe('the title of the article'),
pdfUrl: z.string().describe('the PDF URL of the article')
})
}),
execute: async ({ context }) => {
return await querySimilar(context.question);
},
});
<पी> हम इनपुट और आउटपुट स्कीमा को मान्य करने के लिए ज़ॉड का उपयोग करते हैं। यह लगातार प्रतिक्रियाएँ बनाए रखने में मदद करता है और एलएलएम से संभावित त्रुटियों को कम करता है। हम उपकरण के उपयोग के लिए एक फ़ंक्शन भी परिभाषित करते हैं। हमारा टूल शोध लेखों के एक बड़े संग्रह को क्वेरी करेगा, जिसे समय-समय पर arXiv एपीआई के माध्यम से अपडेट किया जाता है और हमारे अपस्टैश वेक्टर डेटाबेस में एम्बेड किया जाता है। const querySimilar = async (query: string) => {
const { embedding } = await embed({
value: query,
model: openai.embedding("text-embedding-3-small"),
});
const results = await myMastraUpstashVector.query({
indexName: "arxiv",
queryVector: embedding,
topK: 3,
});
if (results && results.length > 0) {
const bestMatch = results[0];
const metadata = bestMatch.metadata as ArxivPaper;
return {
bestOption: {
abstract: metadata.abstract,
title: metadata.title,
pdfUrl: metadata.pdfUrl
}
};
}
throw new Error("No relevant information found");
}
<पी> हम UpstashVector के माध्यम से अपने वेक्टर डेटाबेस पर सरल ऑपरेशन कर सकते हैं उदाहरण, जो MastraVector तक विस्तारित है . ऊपर, हम ऐसे ही लेख सार के लिए क्वेरी करते हैं जिन्हें हमने पहले से एम्बेड किया है और टूल पर सर्वोत्तम परिणाम लौटाते हैं। ध्यान दें कि हम क्वेरी के लिए उसी एम्बेडिंग मॉडल का उपयोग करते हैं जैसा हमने लेखों के लिए किया था। हम लेख एम्बेडिंग को बाद में और अधिक विस्तार से समझाएंगे। द मस्त्रा इंस्टेंस
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
deployer: new VercelDeployer()
});
<पी> हम बस निर्दिष्ट करते हैं कि किन एजेंटों का उपयोग करना है, और हमारा Mastra वस्तु तैयार है. हम इन-मेमोरी स्टोरेज से परे डेटा को बनाए रखने के लिए स्टोरेज भी प्रदान करते हैं। आप उपलब्ध परिनियोजन कॉन्फ़िगरेशन में से भी चुन सकते हैं; हम वर्सेल का उपयोग करके तैनात करेंगे। <पी> create-mastra-app से डिफ़ॉल्ट विकल्पों के साथ , हमारे पास पहले से ही आवश्यक फ़ाइल संरचना है: .
└── mastra
├── agents
│ └── index.ts
├── tools
│ └── index.ts
└── index.ts
<पी> तैनाती से पहले केवल एक चरण शेष है:हमारे पर्यावरण चर। OPENAI_API_KEY=
UPSTASH_VECTOR_REST_URL=
UPSTASH_VECTOR_REST_TOKEN=
UPSTASH_REDIS_REST_URL=
UPSTASH_REDIS_REST_TOKEN=
<पी> इन्हें अपने .env.local में डालें स्थानीय विकास के लिए फ़ाइल करें और उन्हें अपने परिनियोजन परिवेश में जोड़ें। <पी> अब हम अपना मास्ट्रा सर्वर बनाने और तैनात करने के लिए तैयार हैं। npm run build && vercel --prod
<पी> कैसे तैनात किया जाए यह देखने के लिए आप वर्सेल दस्तावेज़ की जांच कर सकते हैं। <पी> विकास करते समय, हम अपने सर्वर का आउटपुट देखने के लिए मास्ट्रा प्लेग्राउंड का उपयोग कर सकते हैं। निम्न आदेश चलाएँ: npm run dev
<पी> यह एक वेब इंटरफ़ेस के लिए एक लिंक प्रदान करेगा जहां आप हमारे एजेंट के साथ चैट कर सकते हैं, स्पष्ट रूप से टूल चला सकते हैं और हमारे सर्वर की क्षमताओं का पता लगा सकते हैं। <पी> अब एप्लिकेशन के दूसरे भाग के बारे में बात करने का समय आ गया है। Next.js सर्वर
<पी> एक बार मास्ट्रा सर्वर स्थापित हो जाने के बाद, हमें तीन चीजों को संभालने की जरूरत है:यूआई, मास्ट्रा सर्वर के साथ संचार, और एक लेख सेवा जो arXiv एपीआई से बात करती है और अपस्टैश वेक्टर में सार को एम्बेड करती है। सर्वर की कार्यप्रणाली को उजागर करने के लिए मास्ट्रा के पास एक क्लाइंट एसडीके है। इसके माध्यम से, आप एजेंटों, टूल्स, मेमोरी और बहुत कुछ तक पहुंच सकते हैं। इसका उपयोग सीधा है, लेकिन हम कुछ उदाहरण साझा करेंगे। अधिक विवरण के लिए, आप यहां दस्तावेज़ देख सकते हैं। Next.js प्रोजेक्ट में, आप बस क्लाइंट SDK इंस्टॉल और उपयोग कर सकते हैं। npm install @mastra/client-js@latest
<पी> अपने कोड में, MastraClient का एक उदाहरण बनाएं इसे अपने प्रोजेक्ट में उपयोग करने के लिए। import { MastraClient } from "@mastra/client-js";
export const mastra_sdk = new MastraClient({
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API!,
retries: 3,
});
<पी> आपको NEXT_PUBLIC_MASTRA_API सेट करना होगा आपके मास्ट्रा सर्वर के पते पर। यदि आप स्थानीय स्तर पर विकास कर रहे हैं, तो यह localhost होगा पता. चूँकि संभवतः 3000 पर पोर्ट विरोध होगा , आप मास्ट्रा सर्वर को स्थानीय रूप से चलाते समय उसके कॉन्फ़िगरेशन को निम्नानुसार बदल सकते हैं: export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
server: {
port: 4111,
timeout: 10000,
}
});
<पी> अब, जब हम मस्त्रा सर्वर को npm run dev के साथ स्थानीय रूप से चलाते हैं , इसे पोर्ट 4111 पर परोसा जाता है . हम NEXT_PUBLIC_MASTRA_API सेट कर सकते हैं http://localhost:4111 तक जब हम Next.js प्रोजेक्ट को स्थानीय रूप से चलाते हैं। <पी> आइए देखें कि हम मस्त्रा के क्लाइंट एसडीके का उपयोग कैसे कर सकते हैं। export const MASTRA_CONFIG = {
resourceId: process.env.NEXT_PUBLIC_RESOURCE_ID || "articleAgent",
agentId: "articleAgent",
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API || "http://localhost:4111",
retries: 3,
}; // this is exported in another file so that we can use it anywhere in the codebase.
// Get your agent and simply stream your response through your agent object.
const agent = mastra_sdk.getAgent(MASTRA_CONFIG.agentId);
const response = await agent.stream({
messages: [message],
resourceId: MASTRA_CONFIG.resourceId,
threadId: threadId
});
<पी> आप अपने उपकरण और एजेंट प्राप्त कर सकते हैं, और एक बार जब वे आपके पास आ जाएं, तो आप क्लाइंट एसडीके के माध्यम से वास्तविक वस्तुओं के साथ लगभग वह सब कुछ कर सकते हैं जो आप कर सकते हैं। <पी> चूँकि हम इस डेमो प्रोजेक्ट को सार्वजनिक रूप से प्रकाशित करेंगे, इसलिए एजेंट पर भारी भार से बचना महत्वपूर्ण है। यहीं पर अपस्टैश रेटलिमिट आती है। प्रत्येक स्ट्रीम अनुरोध से पहले, हम जांच करेंगे कि उपयोगकर्ता रेट-सीमित है या नहीं। अपने रेट लिमिटर को कॉन्फ़िगर करने के लिए, हमें अपस्टैश रेडिस की आवश्यकता होगी। हम अपने मास्ट्रा एजेंट के लिए उसी रेडिस डेटाबेस का उपयोग कर सकते हैं जो हमारे पास है। import { Ratelimit } from '@upstash/ratelimit';
import { Redis } from '@upstash/redis';
// Using the same Redis DB across the project
export const rateLimit = new Ratelimit({
redis: new Redis({
url: process.env.UPSTASH_REDIS_MEMORY_URL!,
token: process.env.UPSTASH_REDIS_MEMORY_TOKEN!
}),
limiter: Ratelimit.slidingWindow(10, '10s'),
prefix: 'upstash-ratelimit',
});
// Fetch the below function before every stream.
export async function isRateLimited(id: string): Promise<boolean> {
const { success } = await rateLimit.limit(id);
return !success;
}
<पी> इस तरह, हम यह सुनिश्चित करते हैं कि हमारे समापन बिंदु भारी भार के अधीन नहीं होंगे। <पी> मास्ट्रा के साथ चैट एजेंट बनाते समय, मास्ट्रा की थ्रेड जेनरेशन की कुछ विशेषताओं को जानना मददगार हो सकता है। याद रखें कि जब हमने एजेंट के लिए मेमोरी कॉन्फ़िगर की थी, तो हमने generateTitle सेट किया था true पर threads में वस्तु. इससे मास्ट्रा नव निर्मित थ्रेड्स के लिए स्वचालित रूप से शीर्षक उत्पन्न करता है। लेकिन यहाँ एक समस्या है:स्पष्ट रूप से एक थ्रेड बनाना संभव है, लेकिन स्वचालित शीर्षक पीढ़ी इस तरह से ट्रिगर नहीं होती है। आम तौर पर, नया थ्रेड बनाने का तरीका इस प्रकार है: const thread = await mastraClient.createMemoryThread({
title: "New Conversation",
metadata: { category: "support" },
resourceId: "resource-1",
agentId: "agent-1",
});
<पी> हालाँकि, इससे एजेंट की स्वचालित रूप से शीर्षक उत्पन्न करने की क्षमता समाप्त हो जाती है, क्योंकि आप इसे मैन्युअल रूप से सेट कर रहे हैं। title को छोड़कर फ़ील्ड खाली होने से भी काम नहीं होता. इस मामले में, हम देख सकते हैं कि खेल का मैदान क्या करता है। विकास के दौरान आपके सर्वर की क्षमताओं का अनुभव करने के लिए मास्ट्रा द्वारा प्रदान किया गया खेल का मैदान याद है? यदि हम ब्राउज़र के डेवलपर टूल में नेटवर्क टैब का निरीक्षण करते हैं, तो हम देखते हैं कि जब एक नया थ्रेड बनाया जाता है, तो यह वास्तव में इसे बनाने के लिए एपीआई अनुरोध नहीं भेजता है। इसके बजाय, यह आपके द्वारा अपना पहला संदेश सबमिट करने की प्रतीक्षा करता है। उसके बाद, यह एक नई जेनरेट की गई थ्रेड आईडी के साथ एक स्ट्रीम अनुरोध भेजता है। यह मस्तरा को बताता है कि इस आईडी के साथ कोई थ्रेड मौजूद नहीं है, इसलिए उसे एक बनाना चाहिए और, यदि generateTitle सत्य है, पहले संदेश के आधार पर एक शीर्षक बनाएं। <पी> आइए अपने प्रोजेक्ट के अंतिम घटक को जारी रखें:arXiv आलेख। arXiv लेख
<पी> arXiv विभिन्न क्षेत्रों में लगभग 2.4 मिलियन शोध लेखों के लिए एक ओपन-एक्सेस संग्रह है। articleQueryTool अपस्टैश वेक्टर डेटाबेस पर सवाल उठाता है, जिसे arXiv एपीआई के माध्यम से प्राप्त लेखों द्वारा फीड किया जाता है। एपीआई का उपयोग करना आसान है; आप अधिक विवरण यहां पा सकते हैं। <पी> हमारे प्रोजेक्ट में, हम प्रतिदिन लेख लाते हैं और संग्रहीत करते हैं। पहली बार जब सर्वर चलता है, तो यह निर्दिष्ट श्रेणियों से लगभग 30,000 लेख प्राप्त करता है। उसके बाद, यह पिछले दिन प्रकाशित नए लेख लाता है। लेख श्रेणियों को निर्दिष्ट करने और प्रारंभिक बड़े बैच को लाने के लिए, हम संबंधित पर्यावरण चर निर्धारित करते हैं। हमें अल्पविराम द्वारा अलग किए गए arXiv की वर्गीकरण का उपयोग करके वांछित लेख श्रेणियां प्रदान करनी चाहिए। आप यहां श्रेणियां देख सकते हैं। CATEGORIES=cs.AI
RUN_BEGINNING_STACK=false
<पी> यदि आप अधिक व्यापक डेटाबेस चाहते हैं, तो आप arXiv के बल्क डेटा एक्सेस का उपयोग कर सकते हैं। इसके बिना, हम प्रति एपीआई क्वेरी 30,000 लेखों तक सीमित हैं, जो हमारे उद्देश्यों के लिए पर्याप्त है। <पी> arXiv के लिए एक सरल क्वेरी इस तरह दिखती है: const categories = process.env.CATEGORIES?.split(',') || []; // Get the desired categories and split them for the query.
const searchQuery = categories.length === 1 ? `cat:${categories[0]}` : `(${categories.map(c => `cat:${c}`).join(" OR ")})`;
const query = `search_query=${searchQuery}&sortBy=submittedDate&sortOrder=descending`;
const url = `http://export.arxiv.org/api/query?${query}`;
const response = await axios.get(url); // Make the API call with the constructed URL.
<पी> हम हर दिन नवीनतम लेख प्राप्त करने और प्रारंभिक स्टैक लाने के लिए इसी तरह की कॉल करते हैं। <पी> आलेख लाने के बाद, हम उन्हें सामान्यीकृत करते हैं और उन्हें अपस्टैश वेक्टर में भंडारण के लिए एम्बेड करते हैं। यह वही वेक्टर डेटाबेस होना चाहिए जिसका उपयोग हमारा मास्ट्रा टूल करता है। "सामान्यीकृत" से हमारा तात्पर्य प्राप्त लेखों को एक मानक ArxivPaper में पार्स करना है टाइप करें, जिसे हम अपने पूरे कोडबेस में उपयोग करेंगे। export interface ArxivPaper {
id: string;
title: string;
abstract: string;
authors: string[];
published: string;
pdfUrl: string;
category: string;
}// The type for our articles, across our codebase.
async function storeAbstracts(papers: ArxivPaper[]) {
const embeddingModel = openai.embedding("text-embedding-3-small"); // The same model used to query on the Mastra side.
const embeddings = await embedArticles(papers, embeddingModel)
// Put the embeddings into the required form with their metadata.
const vectorsToUpsert = getVectorsToUpsert(embeddings, papers)
for (let j = 0; j < vectorsToUpsert.length; j++) {
await vectorStore.upsert(vectorsToUpsert[j], { namespace: "arxiv" }); // Upsert the embeddings with their metadata to Upstash Vector.
}
}
<पी> यह सुनिश्चित करने के लिए कि हमारा डेटाबेस नवीनतम शोध के साथ अद्यतन रहे, हम निर्धारित कार्य निष्पादन के लिए अपस्टैश QStash लागू करते हैं। वर्सेल पर हमारी तैनाती को देखते हुए, हमें फ़ंक्शन टाइमआउट को रोकने की ज़रूरत है जो विस्तारित प्रसंस्करण अंतराल के साथ हो सकता है। हम अपने सर्वर पर एक सार्वजनिक एपीआई एंडपॉइंट को उजागर करके इसका समाधान करते हैं, जिससे हमारा QStash इंस्टेंस दैनिक डेटाबेस अपडेट फ़ंक्शन को विश्वसनीय रूप से ट्रिगर करने में सक्षम होता है। // src/app/api/arxiv_reneval/route.ts
import { verifySignatureAppRouter } from "@upstash/qstash/nextjs"
import { fetchAndUpsertYesterday} from "@/services/arxiv"
async function handler(request: Request) {
console.log("Fetching and upserting yesterday's papers...")
await fetchAndUpsertYesterday()
console.log("Fetching and upserting yesterday's papers completed")
return Response.json({ success: true })
}
export const POST = verifySignatureAppRouter(handler)
<पी> प्रतिदिन सुबह 6:00 बजे यूटीसी पर इस एंडपॉइंट पर अनुरोधों को स्वचालित रूप से ट्रिगर करने के लिए अपस्टैश कंसोल के माध्यम से एक शेड्यूलर को कॉन्फ़िगर किया जा सकता है। <पी> 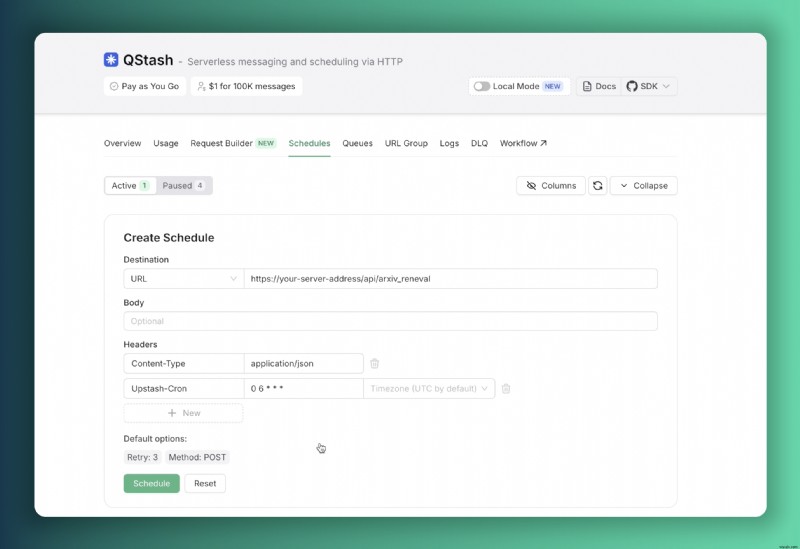 <पी> इस शेड्यूलर कॉन्फ़िगरेशन के साथ, हमारा सर्वर निरंतर डेटा ताज़ाता सुनिश्चित करते हुए, प्रत्येक सुबह स्वचालित डेटाबेस अपडेट करेगा। <पी> हमें अपने QStash उदाहरण के लिए क्रेडेंशियल भी प्रदान करना चाहिए, सभी आवश्यक env चर उदाहरण env फ़ाइल में दिए गए हैं। <पी> बस इतना ही। यदि आप चाहें, तो आप कोड के साथ प्रयास करके खेल सकते हैं। बस रिपॉजिटरी को फोर्क करें और विकास शुरू करें। आप यहां मस्त्रा भाग के भंडार और दूसरे रेपो पर यहां जा सकते हैं। उन्हें फोर्क करने के बाद:
<पी> इस शेड्यूलर कॉन्फ़िगरेशन के साथ, हमारा सर्वर निरंतर डेटा ताज़ाता सुनिश्चित करते हुए, प्रत्येक सुबह स्वचालित डेटाबेस अपडेट करेगा। <पी> हमें अपने QStash उदाहरण के लिए क्रेडेंशियल भी प्रदान करना चाहिए, सभी आवश्यक env चर उदाहरण env फ़ाइल में दिए गए हैं। <पी> बस इतना ही। यदि आप चाहें, तो आप कोड के साथ प्रयास करके खेल सकते हैं। बस रिपॉजिटरी को फोर्क करें और विकास शुरू करें। आप यहां मस्त्रा भाग के भंडार और दूसरे रेपो पर यहां जा सकते हैं। उन्हें फोर्क करने के बाद: - उन्हें अपनी स्थानीय मशीन पर क्लोन करें।
- अपना पर्यावरण चर भरें (उदाहरण
.env)। फ़ाइलें उपलब्ध कराई गई हैं).
- दोनों प्रोजेक्ट के लिए अलग-अलग टर्मिनल में रूट डायरेक्टरी पर जाएं।
- निम्न आदेश चलाएँ:
npm install
npm run dev
<पी> अब आप अपना एप्लिकेशन http://localhost:3000. पर देख सकते हैं <पी> मास्ट्रा के साथ, आप इसके अन्य टेम्पलेट्स जैसे RAG, वर्कफ़्लो और नेटवर्क का उपयोग करके अधिक जटिल चीज़ें बना सकते हैं। ऐसा लगता है कि मेमोरी और स्टोरेज इन सभी उद्देश्यों में महत्वपूर्ण भूमिका निभाते हैं। यहीं पर अपस्टैश चमकता है।