रेडिस एक आधारभूत तकनीक है और, जैसे, हम कभी-कभी लोगों को वैकल्पिक आर्किटेक्चर पर विचार करते हुए देखते हैं। कुछ साल पहले, इसे KeyDB द्वारा लाया गया था, और हाल ही में एक नई परियोजना, Dragonfly, ने सबसे तेज़ रेडिस-संगत इन-मेमोरी डेटास्टोर होने का दावा किया था। हमारा मानना है कि ये परियोजनाएं चर्चा और बहस के लायक कई दिलचस्प तकनीकें और विचार लाती हैं। यहां रेडिस में, हम इस तरह की चुनौती पसंद करते हैं, क्योंकि इसके लिए हमें उन वास्तुशिल्प सिद्धांतों की पुष्टि करने की आवश्यकता होती है जिन्हें रेडिस को शुरू में डिजाइन किया गया था (सल्वाटोर सैनफिलिपो उर्फ एंटीरेज़ के लिए हैट टिप)।
जबकि हम हमेशा रेडिस के प्रदर्शन और क्षमताओं को नया करने और आगे बढ़ाने के अवसरों की तलाश में रहते हैं, हम अपने परिप्रेक्ष्य और कुछ प्रतिबिंब साझा करना चाहते हैं कि क्यों रेडिस का आर्किटेक्चर इन-मेमोरी, रीयल-टाइम डेटास्टोर (कैश) के लिए कक्षा में सर्वश्रेष्ठ रहता है। , डेटाबेस, और बीच में सब कुछ)।
इसलिए अगले खंडों में, हम गति और वास्तु अंतर पर अपने दृष्टिकोण पर प्रकाश डालते हैं क्योंकि यह तुलना की जा रही है। इस पोस्ट के अंत में, हमने बेंचमार्क और प्रदर्शन तुलना बनाम ड्रैगनफ्लाई प्रोजेक्ट का विवरण भी प्रदान किया है, जिसकी हम नीचे चर्चा करते हैं और आपको अपने लिए इनकी समीक्षा और पुन:पेश करने के लिए आमंत्रित करते हैं।
गति
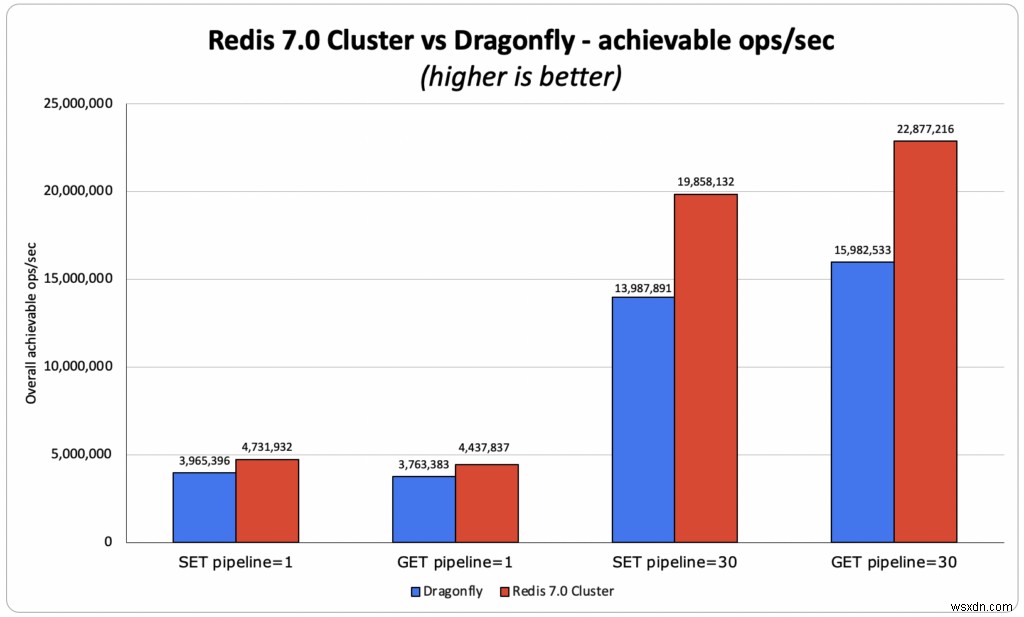
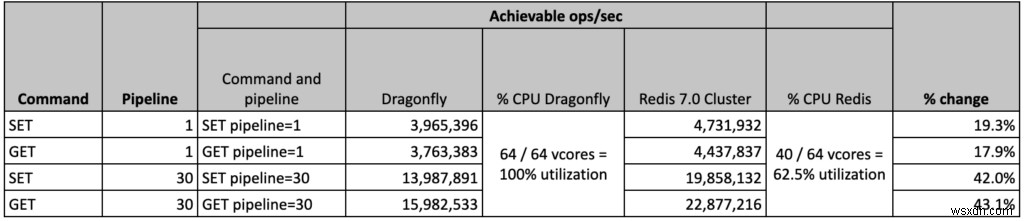
ड्रैगनफ्लाई बेंचमार्क एक स्टैंडअलोन सिंगल प्रोसेस रेडिस इंस्टेंस (जो केवल एक कोर का उपयोग कर सकता है) की तुलना मल्टीथ्रेडेड ड्रैगनफ्लाई इंस्टेंस के साथ करता है (जो वीएम/सर्वर पर सभी उपलब्ध कोर का उपयोग कर सकता है)। दुर्भाग्य से, यह तुलना यह नहीं दर्शाती है कि वास्तविक दुनिया में रेडिस कैसे चलाया जाता है। प्रौद्योगिकी निर्माता के रूप में, हम यह समझने का प्रयास करते हैं कि हमारी प्रौद्योगिकियां दूसरों की तुलना कैसे करती हैं, इसलिए हमने वही किया जो हमें लगता है कि एक उचित तुलना है और 40-शार्ड रेडिस 7.0 क्लस्टर (जो कि अधिकांश इंस्टेंस कोर का उपयोग कर सकता है) की तुलना ड्रैगनफ्लाई के साथ करता है, एक का उपयोग करके ड्रैगनफ्लाई टीम द्वारा अपने बेंचमार्क, एडब्ल्यूएस c6gn.16xlarge में उपयोग किए जाने वाले सबसे बड़े इंस्टेंस प्रकार पर प्रदर्शन परीक्षणों का सेट। अपने परीक्षणों में, हमने देखा कि रेडिस ने ड्रैगनफ्लाई की तुलना में 18% - 40% अधिक थ्रूपुट हासिल किया, तब भी जब 64 vCores में से केवल 40 का उपयोग किया गया था।
वास्तुकला में अंतर
कुछ पृष्ठभूमि
हमारा मानना है कि इन बहु-थ्रेडेड परियोजनाओं के रचनाकारों द्वारा किए गए बहुत से वास्तुशिल्प निर्णय उनके पिछले काम में अनुभव किए गए दर्द बिंदुओं से प्रभावित थे। हम सहमत हैं कि मल्टी-कोर मशीन पर एकल रेडिस प्रक्रिया चलाना, कभी-कभी दर्जनों कोर और सैकड़ों जीबी मेमोरी के साथ, स्पष्ट रूप से उपलब्ध संसाधनों का लाभ नहीं उठाने वाला है। लेकिन ऐसा नहीं है कि रेडिस को इस्तेमाल करने के लिए कैसे डिजाइन किया गया था; यह सिर्फ इतना है कि कितने रेडिस प्रदाताओं ने अपनी सेवाओं को चलाने के लिए चुना है।
एकल क्लाउड इंस्टेंस के संदर्भ में भी बहु-प्रक्रियाओं (रेडिस क्लस्टर का उपयोग करके) चलाकर रेडिस क्षैतिज रूप से स्केल करता है। रेडिस (कंपनी) में हमने इस अवधारणा को और विकसित किया और रेडिस एंटरप्राइज का निर्माण किया जो एक प्रबंधन परत प्रदान करता है जो हमारे उपयोगकर्ताओं को उच्च उपलब्धता, तत्काल विफलता, डेटा दृढ़ता और डिफ़ॉल्ट रूप से बैकअप सक्षम के साथ बड़े पैमाने पर रेडिस चलाने की अनुमति देता है।
हमने उन कुछ सिद्धांतों को साझा करने का निर्णय लिया, जिनका उपयोग हम पर्दे के पीछे करते हैं, ताकि लोगों को यह समझने में मदद मिल सके कि उत्पादन वातावरण में रेडिस को चलाने के लिए हमारे अनुसार अच्छे इंजीनियरिंग अभ्यास क्या हैं।
वास्तुकला के सिद्धांत
प्रति VM में कई Redis इंस्टेंस चलाएँ
प्रति वीएम में कई रेडिस इंस्टेंस चलाना हमें देता है:
- एक पूरी तरह से साझा-कुछ भी नहीं वास्तुकला का उपयोग करते हुए, लंबवत और क्षैतिज रूप से, रैखिक रूप से स्केल करें। यह मल्टीथ्रेडेड आर्किटेक्चर की तुलना में हमेशा अधिक लचीलापन प्रदान करेगा जो केवल लंबवत रूप से स्केल करता है।
- प्रतिकृति की गति बढ़ाएं, क्योंकि प्रतिकृति कई प्रक्रियाओं में समानांतर में की जाती है।
- वीएम की विफलता से तेजी से रिकवरी, इस तथ्य के कारण कि नए वीएम के रेडिस इंस्टेंस एक साथ कई बाहरी रेडिस इंस्टेंस के डेटा से भरे जाएंगे।
प्रत्येक Redis प्रक्रिया को उचित आकार तक सीमित करें
हम किसी एकल रेडिस प्रक्रिया को 25 जीबी आकार (और फ्लैश पर रेडिस चलाते समय 50 जीबी) से आगे बढ़ने की अनुमति नहीं देते हैं। यह हमें अनुमति देता है:
- रेडिस को प्रतिकृति, स्नैपशॉटिंग, और केवल संलग्न फ़ाइल (एओएफ) पुनर्लेखन के लिए फोर्क करते समय बड़ी मेमोरी ओवरहेड के दंड का भुगतान किए बिना कॉपी-ऑन-राइट के लाभों का आनंद लेने के लिए। और 'हाँ' यदि आप ऐसा नहीं करते हैं, तो आप (या आपके उपयोगकर्ता) एक उच्च कीमत का भुगतान करेंगे, जैसा कि यहाँ दिखाया गया है।
- हमारे क्लस्टर को आसानी से प्रबंधित करने के लिए, शार्प, रीशर्ड, स्केल और रीबैलेंस को तेजी से माइग्रेट करें, क्योंकि रेडिस के प्रत्येक इंस्टेंस को छोटा रखा जाता है।
क्षैतिज रूप से स्केलिंग सर्वोपरि है
क्षैतिज स्केलिंग के साथ आपके इन-मेमोरी डेटास्टोर को चलाने का लचीलापन अत्यंत महत्वपूर्ण है। यहां इसके कुछ कारण दिए गए हैं:
- बेहतर लचीलापन - आप अपने क्लस्टर में जितने अधिक नोड्स का उपयोग करेंगे, आपका क्लस्टर उतना ही मजबूत होगा। उदाहरण के लिए, यदि आप अपने डेटासेट को 3-नोड क्लस्टर पर चलाते हैं और एक नोड ख़राब हो जाता है, तो यह आपके क्लस्टर का 1/3 भाग है जो प्रदर्शन नहीं कर रहा है; लेकिन अगर आप अपना डेटासेट 9-नोड्स क्लस्टर पर चलाते हैं और एक नोड ख़राब हो जाता है, तो यह आपके क्लस्टर का सिर्फ 1/9 प्रदर्शन नहीं कर रहा है।
- पैमाने में आसान - अपने क्लस्टर में एक अतिरिक्त नोड जोड़ना और अपने डेटासेट के केवल एक हिस्से को इसमें माइग्रेट करना बहुत आसान है, न कि लंबवत स्केलिंग, जहां आपको एक बड़ा नोड लाने और अपने संपूर्ण डेटासेट पर कॉपी करने की आवश्यकता होती है (और सभी खराब चीजों के बारे में सोचें) जो इस संभावित लंबी प्रक्रिया के बीच में हो सकता है…)
- धीरे-धीरे स्केलिंग अधिक लागत प्रभावी है - लंबवत स्केलिंग, विशेष रूप से क्लाउड में, महंगा है। कई मामलों में, आपको अपने इंस्टेंस आकार को दोगुना करने की आवश्यकता होती है, भले ही आपको अपने डेटासेट में कुछ जीबी जोड़ने की आवश्यकता हो।
- उच्च थ्रूपुट - रेडिस में, हम कई ऐसे ग्राहकों को देखते हैं जो छोटे डेटासेट पर उच्च थ्रूपुट वर्कलोड चला रहे हैं, बहुत उच्च नेटवर्क बैंडविड्थ और/या उच्च पैकेट प्रति सेकेंड (पीपीएस) मांग के साथ। 1M+ ऑप्स/सेकंड उपयोग केस वाले 1GB डेटासेट के बारे में सोचें। क्या इसे सिंगल-नोड c6gn.16xlarge क्लस्टर (64 CPU के साथ 128GB और $2.7684/hr पर 100gbps) पर 3-नोड c6gn.xlarge क्लस्टर (8GB. 4 CPU 25Gbps तक प्रत्येक $0.1786/hr प्रत्येक पर) पर चलाने का कोई मतलब है ) लागत के 20% से कम पर और अधिक मज़बूत तरीके से? लागत-प्रभावशीलता बनाए रखते हुए और लचीलेपन में सुधार करते हुए थ्रूपुट बढ़ाने में सक्षम होने के कारण प्रश्न का आसान उत्तर लगता है।
- NUMA की हकीकत - लंबवत स्केलिंग का अर्थ दो-सॉकेट सर्वर को कई कोर और बड़े DRAM के साथ चलाना भी है; यह NUMA आधारित आर्किटेक्चर रेडिस जैसे मल्टी-प्रोसेसिंग आर्किटेक्चर के लिए बहुत अच्छा है क्योंकि यह छोटे नोड्स के नेटवर्क की तरह व्यवहार करता है। लेकिन मल्टीथ्रेडेड आर्किटेक्चर के लिए NUMA अधिक चुनौतीपूर्ण है, और अन्य मल्टीथ्रेडेड प्रोजेक्ट्स के साथ हमारे अनुभव से, NUMA इन-मेमोरी डेटास्टोर के प्रदर्शन को 80% तक कम कर सकता है।
- भंडारण प्रवाह सीमा - एडब्ल्यूएस ईबीएस जैसे बाहरी डिस्क, मेमोरी और सीपीयू जितनी तेजी से स्केल नहीं करते हैं। वास्तव में, उपयोग किए जा रहे मशीन वर्ग के आधार पर क्लाउड सेवा प्रदाताओं द्वारा लगाई गई स्टोरेज थ्रूपुट सीमाएं हैं। इसलिए, पहले से वर्णित मुद्दों से बचने और उच्च डेटा-दृढ़ता आवश्यकताओं को पूरा करने के लिए क्लस्टर को प्रभावी ढंग से स्केल करने का एकमात्र तरीका क्षैतिज स्केलिंग का उपयोग करना है, यानी, अधिक नोड्स और अधिक नेटवर्क-संलग्न डिस्क जोड़कर।
- क्षणिक डिस्क - एसएसडी पर रेडिस चलाने के लिए एक अल्पकालिक डिस्क एक शानदार तरीका है (जहां एसएसडी का उपयोग डीआरएएम प्रतिस्थापन के रूप में किया जाता है, लेकिन लगातार भंडारण के रूप में नहीं) और रेडिस गति को बनाए रखते हुए डिस्क-आधारित डेटाबेस की लागत का आनंद लें (देखें कि हम इसे कैसे करते हैं) फ्लैश पर रेडिस के साथ)। फिर, जब अल्पकालिक डिस्क अपनी सीमा तक पहुँच जाती है, तो सबसे अच्छा तरीका है, और कई मामलों में, अपने क्लस्टर को स्केल करने का एकमात्र तरीका अधिक नोड्स और अधिक अल्पकालिक डिस्क जोड़ना है।
- कमोडिटी हार्डवेयर - अंत में, हमारे पास कई ऑन-प्रिमाइसेस ग्राहक हैं जो स्थानीय डेटा-सेंटर, प्राइवेट क्लाउड और यहां तक कि छोटे एज डेटा-सेंटर में भी चल रहे हैं; इन वातावरणों में, 64 जीबी से अधिक मेमोरी और 8 सीपीयू वाली मशीनों को ढूंढना मुश्किल हो सकता है, और फिर से स्केल करने का एकमात्र तरीका क्षैतिज है।
सारांश
हम मल्टीथ्रेडेड प्रोजेक्ट्स की नई लहर द्वारा पेश किए गए हमारे समुदाय के नए, दिलचस्प विचारों और प्रौद्योगिकियों की सराहना करते हैं। यह भी संभव है कि इनमें से कुछ अवधारणाएं भविष्य में रेडिस में अपना रास्ता बना लें (जैसे io_uring जिसे हमने पहले ही देखना शुरू कर दिया है, अधिक आधुनिक शब्दकोश, थ्रेड्स का अधिक सामरिक उपयोग, आदि)। लेकिन निकट भविष्य के लिए, हम रेडिस द्वारा प्रदान की जाने वाली साझा-कुछ नहीं, बहु-प्रक्रिया वास्तुकला के मूल सिद्धांत को नहीं छोड़ेंगे। इन-मेमोरी, रीयल-टाइम डेटा प्लेटफ़ॉर्म के लिए आवश्यक विभिन्न परिनियोजन आर्किटेक्चर का समर्थन करते हुए यह डिज़ाइन सर्वोत्तम प्रदर्शन, स्केलिंग और लचीलापन प्रदान करता है।
परिशिष्ट Redis 7.0 बनाम Dragonfly बेंचमार्क विवरण
बेंचमार्क सारांश
संस्करण:
- हमने Redis 7.0.0 का उपयोग किया और इसे स्रोत से बनाया है
- ड्रैगनफ्लाई को स्रोत से 3 जून को बनाया गया था (hash=e806e6ccd8c79e002f721a1a5ecb847bd7a06489) जैसा कि https://github.com/Dragonfly/dragonfly#build-from-source में सुझाया गया है
लक्ष्य:
- सत्यापित करें कि Dragonfly परिणाम पुनरुत्पादित हैं और उन पूर्ण स्थितियों को निर्धारित करें जिनमें उन्हें पुनर्प्राप्त किया गया था (यह देखते हुए कि memtier_benchmark, OS संस्करण, आदि पर कुछ कॉन्फ़िगरेशन गायब थे) और यहां देखें
- एडब्ल्यूएस c6gn.16xबड़ा उदाहरण पर सबसे अच्छा प्राप्त करने योग्य OSS Redis 7.0.0 क्लस्टर प्रदर्शन निर्धारित करें, जो Dragonfly के बेंचमार्क से मेल खाता हो
क्लाइंट कॉन्फ़िगरेशन:
- ओएसएस रेडिस 7.0 समाधान के लिए रेडिस क्लस्टर के लिए बड़ी संख्या में खुले कनेक्शन की आवश्यकता होती है, प्रत्येक को memtier_benchmark दिया जाता है। धागा सभी टुकड़ों से जुड़ा होता है
- ओएसएस रेडिस 7.0 समाधान ने दो memtier_benchmark के साथ सर्वोत्तम परिणाम प्रदान किए बेंचमार्क चलाने वाली प्रक्रियाएं लेकिन उसी क्लाइंट वीएम पर ड्रैगनफ्लाई बेंचमार्क से मेल खाने के लिए)
संसाधन उपयोग और इष्टतम कॉन्फ़िगरेशन:
- ओएसएस रेडिस क्लस्टर ने 40 प्राथमिक शार्क के साथ सबसे अच्छा परिणाम प्राप्त किया, जिसका अर्थ है कि वीएम पर 24 अतिरिक्त वीसीपीयू हैं। हालांकि मशीन का पूरी तरह से उपयोग नहीं किया गया था, हमने पाया कि शार्क की संख्या बढ़ाने से मदद नहीं मिली, बल्कि समग्र प्रदर्शन में कमी आई। हम अभी भी इस व्यवहार की जांच कर रहे हैं।
- दूसरी ओर, ड्रैगनफ्लाई समाधान वीएम में पूरी तरह से शीर्ष पर पहुंच गया है और सभी 64 वीसीपीयू 100% उपयोग तक पहुंच गए हैं।
- दोनों समाधानों के लिए, हम सर्वोत्तम संभव परिणाम प्राप्त करने के लिए क्लाइंट कॉन्फ़िगरेशन में बदलाव करते हैं। जैसा कि नीचे देखा जा सकता है, हम ड्रैगनफ्लाई डेटा के बहुमत को दोहराने में कामयाब रहे और यहां तक कि 30 के बराबर पाइपलाइन के लिए सर्वोत्तम परिणामों को पार कर गए।
- इसका मतलब है कि रेडिस के साथ हमने जो संख्या हासिल की है, उसमें और वृद्धि करने की संभावना है।
अंत में, हमने यह भी पाया कि Redis और Dragonfly दोनों नेटवर्क PPS या बैंडविड्थ द्वारा सीमित नहीं थे, यह देखते हुए कि हमने पुष्टि की है कि 2 उपयोग किए गए VMs (क्लाइंट और सर्वर के लिए, c6gn.16xlarge का उपयोग करने वाले बॉट) के बीच हम> 10M PPS तक पहुंच सकते हैं और> ~300B पेलोड के साथ TCP के लिए 30 Gbps।
परिणामों का विश्लेषण करना
- पाइपलाइन 1 सब-एमएस प्राप्त करें :
- OSS Redis:4.43M ops/sec, जहां avg और p50 दोनों ने सब-मिलीसेकंड लेटेंसी हासिल की। औसत ग्राहक विलंबता 0.383 एमएस . थी
- ड्रैगनफ्लाई ने 4एम ऑप्स/सेकंड का दावा किया:
- हम 0.390 एमएस की औसत क्लाइंट लेटेंसी के साथ 3.8 मिलियन ऑप्स/सेकंड पुन:उत्पन्न करने में कामयाब रहे हैं
- Redis बनाम Dragonfly - Redis थ्रूपुट 10% . से अधिक है बनाम Dragonfly ने दावा किए गए परिणाम और 18% . द्वारा बनाम ड्रैगनफ्लाई परिणाम, जिसे हम पुन:पेश करने में सक्षम थे।
- गेट पाइपलाइन 30:
- ओएसएस रेडिस:2.239 एमएस की औसत क्लाइंट विलंबता के साथ 22.9 मिलियन ऑप्स/सेकंड
- ड्रैगनफ्लाई ने 15एम ऑप्स/सेकंड का दावा किया:
- हम 3.99 एमएस की औसत क्लाइंट लेटेंसी के साथ 15.9 मिलियन ऑप्स/सेकंड पुन:उत्पन्न करने में कामयाब रहे हैं
- Redis बनाम Dragonfly - Redis 43% से बेहतर है (बनाम ड्रैगनफ्लाई पुनरुत्पादित परिणाम) और 52% . द्वारा (बनाम ड्रैगनफ्लाई दावा किए गए परिणाम)
- सेट पाइपलाइन 1 सब-एमएस :
- OSS Redis:4.74M ops/sec, जहां avg और p50 दोनों ने सब-मिलीसेकंड लेटेंसी हासिल की। औसत क्लाइंट लेटेंसी 0.391 ms थी
- ड्रैगनफ्लाई ने 4एम ऑप्स/सेकंड का दावा किया:
- हम 0.500 एमएस की औसत क्लाइंट लेटेंसी के साथ 4 मिलियन ऑप्स/सेकंड को पुन:पेश करने में कामयाब रहे हैं
- Redis vs Dragonfly – Redis 19% से बेहतर है (हमने उन्हीं परिणामों को पुन:प्रस्तुत किया जो ड्रैगनफ्लाई ने होने का दावा किया था)
- सेट पाइपलाइन 30:
- OSS Redis:19.85M ops/sec, औसत ग्राहक विलंबता 2.879 ms के साथ
- ड्रैगनफ्लाई ने 10एम ऑप्स/सेकंड का दावा किया:
- हमने 4.203 एमएस की औसत क्लाइंट लेटेंसी के साथ 14 मिलियन ऑप्स/सेकंड को पुन:पेश करने में कामयाबी हासिल की है)
- Redis बनाम Dragonfly - Redis 42% से बेहतर है (बनाम ड्रैगनफ्लाई पुनरुत्पादित परिणाम) और 99% (बनाम ड्रैगनफ्लाई दावा किए गए परिणाम)
memtier_benchmark प्रत्येक भिन्नता के लिए प्रयुक्त कमांड:
- पाइपलाइन 1 सब-एमएस प्राप्त करें
- रेडिस:
- 2X:memtier_benchmark -अनुपात 0:1 -t 24 -c 1 -test-time 180 -distinct-client-seed -d 256 -cluster-mode -s 10.3.1.88 -port 30001 -key-maximum 1000000 -hide -हिस्टोग्राम
- ड्रैगनफ्लाई:
- memtier_benchmark -अनुपात 0:1 -t 55 -c 30 -n 200000 -distinct-client-seed -d 256 -s 10.3.1.6 -key-maximum 1000000 -hide-histogram
- रेडिस:
- पाइपलाइन 30 प्राप्त करें
- रेडिस:
- 2X:memtier_benchmark -अनुपात 0:1 -t 24 -c 1 -test-time 180 -distinct-client-seed -d 256 -cluster-mode -s 10.3.1.88 -port 30001 -key-maximum 1000000 -hide -हिस्टोग्राम-पाइपलाइन 30
- ड्रैगनफ्लाई:
- memtier_benchmark -अनुपात 0:1 -t 55 -c 30 -n 200000 -distinct-client-seed -d 256 -s 10.3.1.6 -key-maximum 1000000 -hide-histogram -pipeline 30
- memtier_benchmark -अनुपात 0:1 -t 55 -c 30 -n 200000 -distinct-client-seed -d 256 -s 10.3.1.6 -key-maximum 1000000 -hide-histogram -pipeline 30
- रेडिस:
- सेट पाइपलाइन 1 सब-एमएस
- रेडिस:
- 2X:memtier_benchmark -अनुपात 1:0 -t 24 -c 1 -test-time 180 -distinct-client-seed -d 256 -cluster-mode -s 10.3.1.88 -port 30001 -key-maximum 1000000 -hide -हिस्टोग्राम
- ड्रैगनफ्लाई:
- memtier_benchmark -अनुपात 1:0 -t 55 -c 30 -n 200000 -distinct-client-seed -d 256 -s 10.3.1.6 -key-maximum 1000000 -hide-histogram
- memtier_benchmark -अनुपात 1:0 -t 55 -c 30 -n 200000 -distinct-client-seed -d 256 -s 10.3.1.6 -key-maximum 1000000 -hide-histogram
- रेडिस:
- सेट पाइपलाइन 30
- रेडिस:
- 2X:memtier_benchmark -अनुपात 1:0 -t 24 -c 1 -test-time 180 -distinct-client-seed -d 256 -cluster-mode -s 10.3.1.88 -port 30001 -key-maximum 1000000 -hide -हिस्टोग्राम-पाइपलाइन 30
- ड्रैगनफ्लाई:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- रेडिस:
Infrastructure details
We used the same VM type for both client (for running memtier_benchmark) and the server (for running Redis and Dragonfly), here is the spec:
- VM :
- AWS c6gn.16xlarge
- aarch64
- ARM Neoverse-N1
- Core(s) per socket:64
- Thread(s) per core:1
- NUMA node(s):1
- AWS c6gn.16xlarge
- Kernel:Arm64 Kernel 5.10
- Installed Memory: 126GB