Redis SQL क्वेरी चलाना मुश्किल नहीं है। मैंने वास्तव में कुछ साल पहले एक खुदरा कंपनी में डेटा वेयरहाउसिंग समाधान का प्रबंधन करने वाले मित्र से बात करते हुए इस बिंदु को उठाया था। रेडिस ने जिस समस्या का सामना किया, उसके बारे में बताने के बाद हमने उसके बारे में बात करना शुरू किया।
"हमारे डेटा वेयरहाउसिंग समाधानों के साथ हमारे पास एक दर्द बिंदु है। हमारे पास ऐसे मामलों का उपयोग होता है जहां हमें डेटा रिकॉर्ड करने और वास्तविक समय में विश्लेषणात्मक संचालन करने की आवश्यकता होती है। हालांकि, कभी-कभी परिणाम प्राप्त करने में कुछ मिनट लगते हैं। क्या रेडिस यहां मदद कर सकता है? ध्यान रखें कि हम अपने SQL-आधारित समाधान को एक ही बार में रिप और रिप्लेस नहीं कर सकते हैं। हम एक बार में केवल एक छोटा कदम उठा सकते हैं। "
अब, यदि आप मेरे मित्र के समान स्थिति में हैं, तो हमारे पास आपके लिए अच्छी खबर है। ऐसे कई तरीके हैं जिनसे आप एक Redis क्वेरी चला सकते हैं और Redis को अपने आर्किटेक्चर में पेश कर सकते हैं बिना आपके वर्तमान SQL-आधारित समाधान को बाधित कर रहा है।
आइए जानें कि आप यह कैसे कर सकते हैं। लेकिन इससे पहले कि हम आगे बढ़ें, हमारे पास एक रेडिस हैकाथॉन प्रतियोगी है जिसने अपना ऐप बनाया है जो आपको SQL के साथ रेडिस में डेटा क्वेरी करने की अनुमति देता है।
नीचे दिया गया वीडियो देखें।
अपनी तालिकाओं को Redis डेटा संरचनाओं के रूप में फिर से तैयार करें
अपनी तालिका को रेडिस डेटा संरचनाओं में मैप करना काफी सरल है। अनुसरण करने के लिए सबसे उपयोगी डेटा संरचनाएं हैं:
- हैश
- सॉर्ट किए गए सेट
- सेट
ऐसा करने का एक तरीका यह है कि प्रत्येक पंक्ति को हैश के रूप में एक कुंजी के साथ संग्रहीत किया जाता है जो तालिका की प्राथमिक कुंजी पर आधारित होती है और कुंजी को सेट या सॉर्ट किए गए सेट में संग्रहीत किया जाता है।
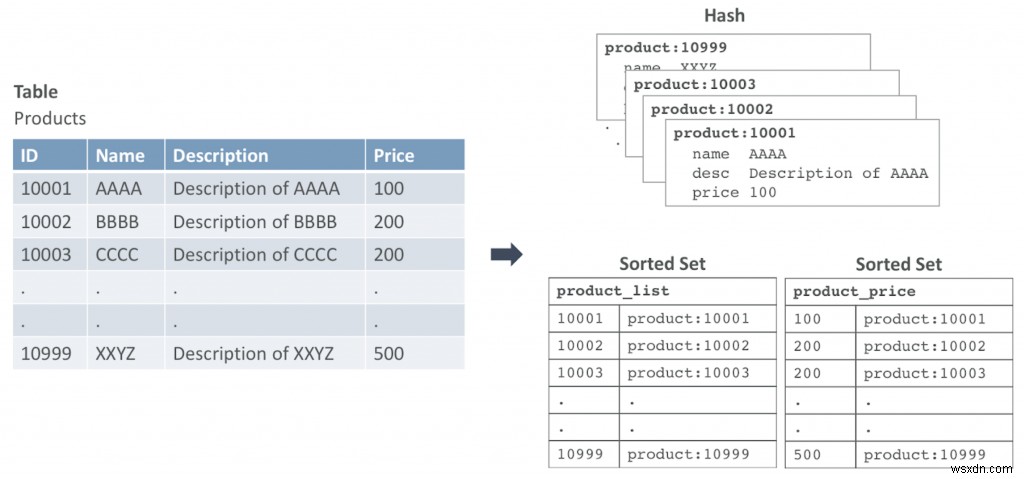
चित्र 1 एक उदाहरण दिखाता है कि आप तालिका को रेडिस डेटा संरचनाओं में कैसे मैप कर सकते हैं। इस उदाहरण में, हमारे पास उत्पाद नामक एक तालिका है। प्रत्येक पंक्ति को हैश डेटा संरचना में मैप किया जाता है।
प्राथमिक आईडी के साथ पंक्ति, 10001 कुंजी के साथ हैश के रूप में जाएगी:उत्पाद:10001। इस उदाहरण में हमारे पास दो सॉर्ट किए गए सेट हैं:पहला प्राथमिक कुंजी द्वारा सेट किए गए डेटा के माध्यम से पुनरावृति करने के लिए और दूसरा मूल्य के आधार पर क्वेरी करने के लिए।
इस विकल्प के साथ, आपको SQL कमांड के बजाय Redis क्वेरी का उपयोग करने के लिए अपने कोड में परिवर्तन करने की आवश्यकता है। नीचे SQL और Redis समकक्ष कमांड के कुछ उदाहरण दिए गए हैं:
<मजबूत>ए. डेटा डालें
SQL: insert into Products (id, name, description, price) values = (10200, “ZXYW”,“Description for ZXYW”, 300);
Redis: MULTI HMSET product:10200 name ZXYW desc “Description for ZXYW” price 300 ZADD product_list 10200 product:10200 ZADD product_price 300 product:10200 EXEC
<मजबूत>बी. उत्पाद आईडी के आधार पर क्वेरी
SQL: select * from Products where id = 10200
Redis: HGETALL product:10200
<मजबूत>सी. कीमत के हिसाब से पूछें
SQL: select * from Product where price < 300. है
Redis: ZRANGEBYSCORE product_price 0 300
यह कुंजियाँ लौटाता है:उत्पाद:10001, उत्पाद:10002, उत्पाद:10003। अब प्रत्येक कुंजी के लिए HGETALL चलाएँ।
HGETALL product:10001 HGETALL product:10002 HGETALL product:10003
Redis डेटा संरचनाओं में अपनी तालिकाओं को स्वचालित रूप से मैप करने के लिए DataFrames का उपयोग करें
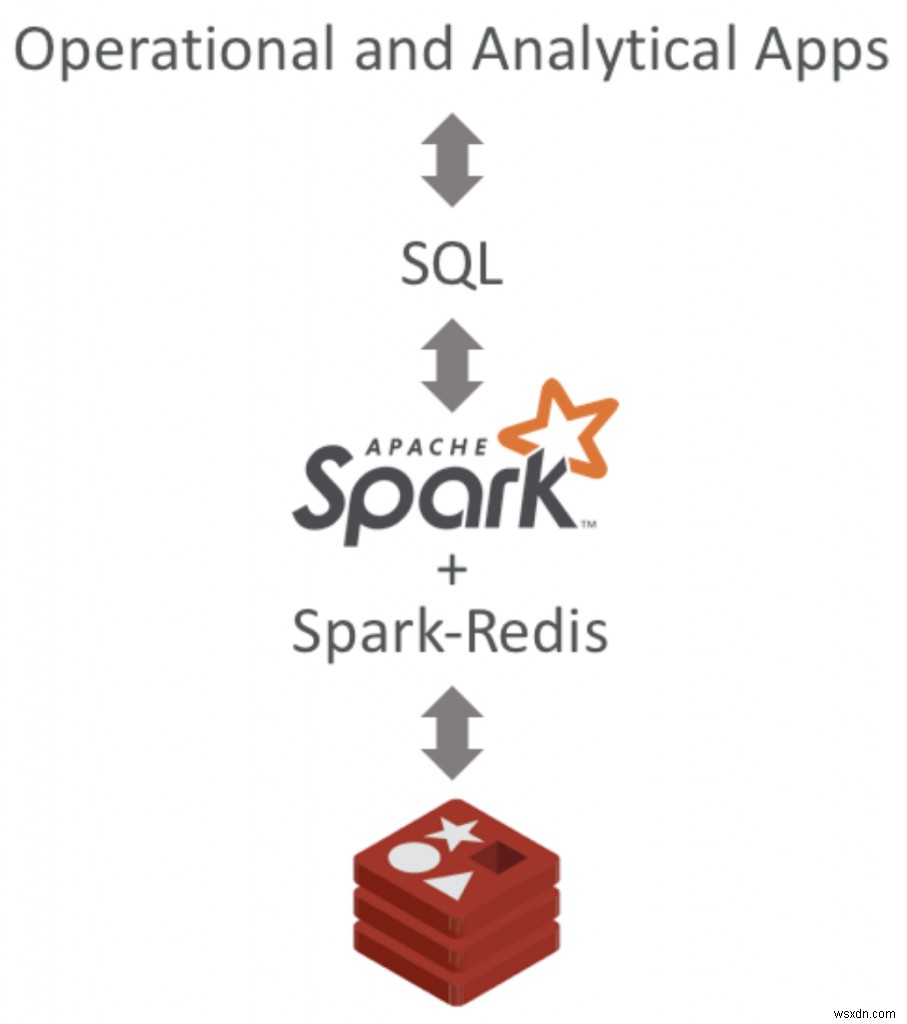
अब, यदि आप अपने समाधानों में SQL इंटरफ़ेस को बनाए रखना चाहते हैं और इसे तेज़ बनाने के लिए केवल अंतर्निहित डेटा स्टोर को Redis में बदलना चाहते हैं, तो आप Apache Spark और Spark-Redis लाइब्रेरी का उपयोग करके ऐसा कर सकते हैं।
स्पार्क-रेडिस लाइब्रेरी आपको रेडिस डेटा को स्टोर और एक्सेस करने के लिए डेटाफ्रेम एपीआई का उपयोग करने की अनुमति देती है। दूसरे शब्दों में, आप SQL कमांड का उपयोग करके डेटा सम्मिलित, अद्यतन और क्वेरी कर सकते हैं, लेकिन डेटा को आंतरिक रूप से Redis डेटा संरचनाओं में मैप किया जाता है।
सबसे पहले, आपको स्पार्क-रेडिस डाउनलोड करने और जार फ़ाइल प्राप्त करने के लिए लाइब्रेरी बनाने की आवश्यकता है। उदाहरण के लिए, स्पार्क-रेडिस 2.3.1 के साथ, आपको स्पार्क-रेडिस-2.3.1-स्नैपशॉट-जार-साथ-निर्भरता.जर मिलता है।
फिर आपको यह सुनिश्चित करना होगा कि आपके पास रेडिस इंस्टेंस चल रहा है। हमारे उदाहरण में, हम रेडिस को लोकलहोस्ट और डिफ़ॉल्ट पोर्ट 6379 पर चलाएंगे।
आप अपने प्रश्नों को अपाचे स्पार्क इंजन पर भी चला सकते हैं। आप यह कैसे कर सकते हैं इसका एक उदाहरण यहां दिया गया है:
$ spark-shell --jars spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession
.builder()
.appName("redis-sql")
.master("local[*]")
.config("spark.redis.host","localhost")
.config("spark.redis.port","6379").getOrCreate()
scala> import spark.sql
scala> import spark.implicits._
scala> sql("create table if not exists products(id string, name string, description string, price int) using org.apache.spark.sql.redis options (table 'product')")
scala> sql("insert into products values = ('10200','ZXYW','Description of ZXYW', 300)")
scala> val results = sql("select * from products")
scala> results.show()
+-----+----+-------------------+-----+
| id|name| description|price|
+-----+----+-------------------+-----+
|10200|ZXYW|Description of ZXYW| 300|
+-----+----+-------------------+-----+ अब आप इस डेटा को Redis डेटा संरचनाओं के रूप में एक्सेस करने के लिए अपने Redis क्लाइंट का भी उपयोग कर सकते हैं:
127.0.0.1:6379> keys product* 1) "product:2e3f8611dbe94a588706a2aaea547caa"
स्कैन कमांड का उपयोग करने के लिए एक अधिक प्रभावी तरीका होगा क्योंकि यह आपको डेटा के माध्यम से नेविगेट करने की अनुमति देता है।
127.0.0.1:6379> scan 0 match product* 1) "3" 2) 1) "product:2e3f8611dbe94a588706a2aaea547caa" 127.0.0.1:6379> hgetall product:2e3f8611dbe94a588706a2aaea547caa 1) "name" 2) "ZXYW" 3) "price" 4) "300" 5) "description" 6) "Description of ZXYW" 7) "id" 8) "10200"
और वहां हमारे पास है - दो सरल तरीके जिनसे आप बिना किसी व्यवधान के Redis SQL क्वेरी चला सकते हैं। एक कदम और आगे बढ़ते हुए, आप शायद यह जानना चाहें कि आपके SQL सर्वर को Redis की आवश्यकता क्यों है हमारे नए श्वेतपत्र में।
लेकिन रेडिस के साथ रीयल-टाइम डेटा के संबंध में, यह रीयल-टाइम अनुभव प्रदान करने के लिए इसका उपयोग करने के कई तरीकों में से केवल एक है।
यदि आप यह जानना चाहते हैं कि रेडिस आपको रीयल-टाइम डेटा ट्रांसमिशन की गारंटी कैसे दे सकता है, तो हमसे संपर्क करना सुनिश्चित करें।