यह पोस्ट मेरी राय में, दुनिया की दो सबसे रोमांचक चीजों के बारे में है:संभाव्य डेटा संरचनाएं और रेडिस मॉड्यूल। यदि आपने एक या दूसरे के बारे में सुना है तो आप निश्चित रूप से मेरे उत्साह से संबंधित हो सकते हैं, लेकिन यदि आप पृथ्वी पर सबसे अच्छे सामान को पकड़ना चाहते हैं तो बस पढ़ना जारी रखें।
मैं इस कथन के साथ शुरू करूँगा:बड़े पैमाने पर निम्न-विलंबता डेटा प्रोसेसिंग चुनौतीपूर्ण है। शामिल डेटा की मात्रा और वेग वास्तविक समय के विश्लेषण को अत्यधिक मांग वाला बना सकते हैं। अपने उच्च प्रदर्शन और बहुमुखी प्रतिभा के कारण, रेडिस का उपयोग आमतौर पर ऐसी चुनौतियों को हल करने के लिए किया जाता है। उप-मिलीसेकंड विलंबता में डेटा के कई रूपों को संग्रहीत, हेरफेर और सेवा करने की इसकी क्षमता इसे कई मामलों में आदर्श डेटा कंटेनर बनाती है जहां ऑनलाइन गणना की आवश्यकता होती है।
लेकिन सब कुछ सापेक्ष है, और तराजू इतने चरम हैं कि वे सटीक वास्तविक समय विश्लेषण को व्यावहारिक असंभव बना देते हैं। जटिल समस्याएं जितनी बड़ी होती जाती हैं, उतनी ही कठिन होती जाती हैं, लेकिन हम यह भूल जाते हैं कि साधारण समस्याएं उसी नियम का पालन करती हैं। यहां तक कि जब डेटा बहुत बड़ा, बहुत तेज़ होता है या जब हमारे पास इसे संसाधित करने के लिए पर्याप्त संसाधन नहीं होते हैं, तो संक्षेप में संख्याओं के रूप में कुछ भी एक महत्वपूर्ण कार्य बन सकता है। और जबकि संसाधन हमेशा सीमित और महंगे होते हैं, डेटा लगातार बढ़ रहा है जैसे किसी का व्यवसाय नहीं है।
काउंट-मिनट स्केच क्या है?
काउंट-मिन स्केच (जिसे सीएम स्केच भी कहा जाता है) एक संभाव्य डेटा संरचना है जो यह समझने के बाद बेहद उपयोगी है कि यह कैसे काम करता है और इससे भी महत्वपूर्ण बात यह है कि इसका उपयोग कैसे किया जाता है।
सौभाग्य से, सीएम स्केच की सरल विशेषताएं नौसिखियों के लिए समझने में अपेक्षाकृत आसान बनाती हैं (पता चला कि मेरे कई दोस्त इस टॉप-के ब्लॉग के साथ अनुसरण करने में असमर्थ थे)।
सीएम स्केच कई वर्षों से रेडिस मॉड्यूल रहा है और हाल ही में रेडिसब्लूम मॉड्यूल v2.0 के हिस्से के रूप में फिर से लिखा गया था। लेकिन इससे पहले कि हम सीएम स्केच में उतरें, यह समझना महत्वपूर्ण है कि आप कोई भी . का उपयोग क्यों करेंगे संभाव्य डेटा संरचना गति, स्थान और सटीकता के त्रिकोण में, संभाव्य डेटा संरचनाएं स्थान हासिल करने के लिए कुछ सटीकता का त्याग करती हैं—संभावित रूप से बहुत अधिक स्थान ! गति पर प्रभाव एल्गोरिदम और सेट आकारों के आधार पर भिन्न होता है।
- सटीकता :परिभाषा के अनुसार, अपने डेटा का केवल एक हिस्सा रखने और भंडारण में टकराव की अनुमति देने से सटीकता कम हो जाती है। फिर भी आप अपने उपयोग के मामले के आधार पर अधिकतम त्रुटि दर निर्धारित कर सकते हैं।
- स्मृति स्थान :बड़े डेटा की दुनिया में जहां अरबों ईवेंट रिकॉर्ड किए जाते हैं, केवल आंशिक डेटा संग्रहीत करने से संग्रहण स्थान की आवश्यकताओं और लागतों को काफी कम किया जा सकता है।
- गति :कुछ पारंपरिक डेटा संरचनाएं अपेक्षाकृत अक्षम रूप से संचालित होती हैं, प्रतिक्रिया समय धीमा करती हैं। (उदाहरण के लिए, एक सॉर्ट किया गया सेट इसमें सभी तत्वों के क्रम को बनाए रखता है, लेकिन आपको केवल शीर्ष तत्वों में रुचि हो सकती है। क्योंकि संभाव्य एल्गोरिदम केवल आंशिक सूची बनाए रखते हैं, वे अधिक कुशल होते हैं और अक्सर प्रश्नों का उत्तर बहुत तेजी से दे सकते हैं।
सही संभाव्य डेटा संरचना आपको कम सटीकता के बदले में अपने डेटासेट में जानकारी का केवल एक हिस्सा रखने की अनुमति देती है। बेशक, कई मामलों में (उदाहरण के लिए बैंक खाते), कम सटीकता अस्वीकार्य है। लेकिन वेबसाइट उपयोगकर्ताओं को मूवी की सिफारिश करने या विज्ञापन दिखाने के लिए, अपेक्षाकृत दुर्लभ गलती की लागत कम होती है और स्थान की बचत पर्याप्त हो सकती है।
मूल रूप से, CM स्केच आपके डेटासेट में सभी आइटमों की गिनती को कई काउंटर सरणियों में एकत्रित करके काम करता है। एक प्रश्न पर, यह आइटम की सभी सरणियों की न्यूनतम गणना देता है, जो टकराव के कारण होने वाली गिनती मुद्रास्फीति को कम करने का वादा करता है। कम उपस्थिति दर या स्कोर ("माउस प्रवाह") वाले आइटम की गिनती त्रुटि दर से कम होती है , इसलिए आप उनकी वास्तविक गणना के बारे में कोई भी डेटा खो देते हैं और उन्हें शोर के रूप में माना जाता है। उच्च उपस्थिति दर या स्कोर ("हाथी प्रवाह") वाले आइटम के लिए, बस प्राप्त संख्या का उपयोग करें। यह देखते हुए कि सीएम स्केच का आकार स्थिर है और इसका उपयोग अनंत संख्या में वस्तुओं के लिए किया जा सकता है, आप भंडारण स्थान में भारी बचत की संभावना देख सकते हैं।
पृष्ठभूमि के लिए, रेखाचित्र डेटा संरचनाओं और उनके साथ आने वाले एल्गोरिदम का एक वर्ग है। वे स्थिर या सबलाइनियर स्पेस का उपयोग करते हुए इसके बारे में सवालों के जवाब देने के लिए आपके डेटा की प्रकृति को कैप्चर करते हैं। सीएम स्केच का वर्णन ग्राहम कॉर्मोड और एस. मुथु मुथुकृष्णन ने 2005 के एक पेपर " में किया था। एक बेहतर डेटा स्ट्रीम सारांश:काउंट-मिन स्केच और उसके अनुप्रयोग।"
काउंट-मिनट स्केच:क्या और कैसे
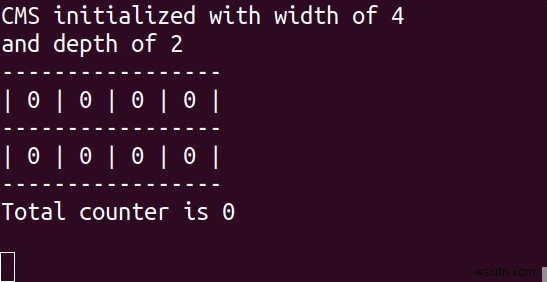
सीएम स्केच अपने प्राथमिक उपयोग के मामलों का समर्थन करने के लिए काउंटरों के कई सरणियों का उपयोग करता है। आइए सरणियों की संख्या को "गहराई" और प्रत्येक सरणी में काउंटरों की संख्या को "चौड़ाई" कहते हैं।
जब भी हमें कोई आइटम प्राप्त होता है, तो हम गणना करने के लिए एक हैश फ़ंक्शन का उपयोग करते हैं (जो एक तत्व-एक शब्द, वाक्य, संख्या, या बाइनरी- को एक संख्या में बदल देता है जिसे सेट/सरणी में स्थान के रूप में या फ़िंगरप्रिंट के रूप में उपयोग किया जा सकता है) आइटम का स्थान और प्रत्येक सरणी के लिए उस काउंटर को बढ़ाएं। प्रत्येक संबद्ध काउंटर का मूल्य वस्तु के वास्तविक मूल्य के बराबर या उससे अधिक होता है। जब हम कोई पूछताछ करते हैं, तो हम समान हैश फ़ंक्शन के साथ सभी सरणियों से गुजरते हैं और हमारे आइटम से जुड़े काउंटर को प्राप्त करते हैं। हम तब न्यूनतम मान लौटाते हैं जिसका हमें सामना करना पड़ा क्योंकि हम जानते हैं कि हमारे मूल्य फुलाए गए (या बराबर) हैं।
भले ही हम जानते हैं कि प्राकृतिक टकराव (जब अलग-अलग आइटम एक ही स्थान प्राप्त करते हैं) के कारण कई आइटम अधिकांश काउंटरों में योगदान करते हैं, हम 'शोर' को तब तक स्वीकार करते हैं जब तक यह हमारी वांछित त्रुटि दर के भीतर रहता है।
गिनती-मिनट स्केच उदाहरण
गणित बताता है कि 10 की गहराई और 2,000 की चौड़ाई के साथ, त्रुटि न होने की संभावना 99.9% है और त्रुटि दर 0.1% है। (यह कुल वेतन वृद्धि का प्रतिशत है, अद्वितीय वस्तुओं का नहीं)।
वास्तविक संख्या में, इसका मतलब है कि यदि आप औसतन 1 मिलियन अद्वितीय आइटम जोड़ते हैं, तो प्रत्येक आइटम को 500 (1M/2K) का मान प्राप्त होगा। हालांकि यह अनुपातहीन लगता है, यह 0.1% की हमारी त्रुटि दर के भीतर अच्छी तरह से आता है, जो कि 1 मिलियन वस्तुओं पर 1,000 है।
इसी तरह, यदि 10 हाथी 10,000 बार दिखाई देते हैं, तो सभी सेटों पर उनका मूल्य 10,000 या उससे अधिक होगा। जब भी हम भविष्य में उनकी गिनती करते हैं, तो हमें अपने सामने एक हाथी दिखाई देता है। अन्य सभी संख्याओं के लिए (अर्थात, सभी चूहे जिनकी वास्तविक संख्या 1 है), उनके सभी सेटों पर एक हाथी से टकराने की संभावना नहीं है (चूंकि सीएम स्केच केवल न्यूनतम गणना पर विचार करता है) क्योंकि ऐसा होने की संभावना कम है और यदि आप सीएम स्केच को इनिशियलाइज़ करते ही गहराई बढ़ाएं।
काउंट-मिन स्केच किसके लिए अच्छा है?
अब जब हम सीएम स्केच के व्यवहार को समझ गए हैं, तो हम इस छोटे से जानवर के साथ क्या कर सकते हैं? यहां कुछ सामान्य उपयोग के मामले दिए गए हैं:
- दो संख्याओं को क्वेरी करें और उनकी संख्या की तुलना करें।
- आने वाली वस्तुओं का प्रतिशत सेट करें, मान लें कि 1%। जब भी किसी आइटम की न्यूनतम संख्या कुल गणना के 1% से अधिक होती है, तो हम सही लौटते हैं। इसका उपयोग ऑनलाइन गेम के शीर्ष खिलाड़ी को निर्धारित करने के लिए किया जा सकता है, उदाहरण के लिए।
- CM स्केच में एक मिन-हीप जोड़ें और एक टॉप-के डेटा संरचना बनाएं। जब भी हम किसी आइटम को बढ़ाते हैं, तो हम जांचते हैं कि नई न्यूनतम-गिनती ढेर में न्यूनतम से अधिक है या नहीं और उसके अनुसार इसे अपडेट करें। रेडिसब्लूम में टॉप-के मॉड्यूल के विपरीत, जो समय के साथ धीरे-धीरे कम हो जाता है, सीएम स्केच कभी नहीं भूलता है और इसलिए इसका व्यवहार हेवीकीपर से थोड़ा अलग है। -आधारित टॉप-के.
रेडिसब्लूम में, सीएम स्केच के लिए एपीआई सरल और आसान है:
- CM स्केच डेटा संरचना को इनिशियलाइज़ करने के लिए:INITBYDIM {कुंजी } {चौड़ाई } {गहराई } या CMS.INITBYPROB {कुंजी } {त्रुटि } {संभावना }
- किसी वस्तु के काउंटर बढ़ाने के लिए:CMS.INCBY {कुंजी } {आइटम } {वृद्धि }
- आइटम के काउंटरों में न्यूनतम संख्या प्राप्त करने के लिए:CMS.QUERY {कुंजी } {आइटम }
इस पोस्ट के शीर्ष पर एनिमेटेड उदाहरण बनाने के लिए निम्नलिखित कमांड का उपयोग किया गया था:
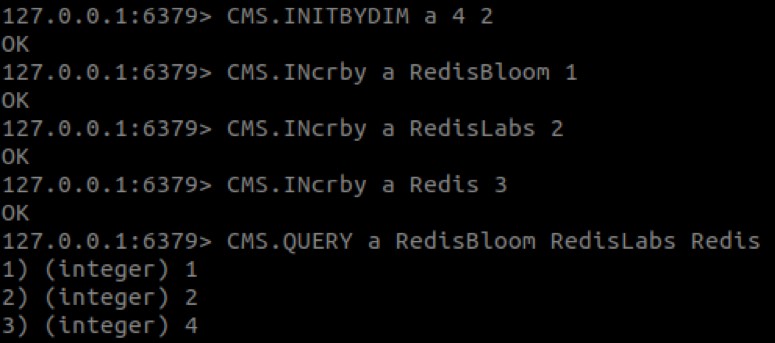
जैसा कि आप देख सकते हैं, 'रेडिस' का मान 3 के बजाय 4 है। यह व्यवहार अपेक्षित है, क्योंकि सीएम स्केच में, किसी आइटम की गिनती बढ़ने की संभावना है।
एक बनावटी व्यवसाय
सॉफ्टवेयर इंजीनियरिंग व्यापार-बंद करने के बारे में है, और इस तरह की चुनौतियों को लागत प्रभावी तरीके से संबोधित करने के लिए एक लोकप्रिय दृष्टिकोण दक्षता के पक्ष में सटीकता को त्यागना है। हाइपरलॉगलॉग के रेडिस के कार्यान्वयन द्वारा इस दृष्टिकोण का उदाहरण दिया गया है, एक डेटा संरचना जिसे सेट कार्डिनैलिटी के बारे में प्रश्नों के उत्तर कुशलतापूर्वक प्रदान करने के लिए डिज़ाइन किया गया है। हाइपरलॉगलॉग "स्केच" नामक डेटा संरचनाओं के एक परिवार का सदस्य है, जो अपने वास्तविक दुनिया के कलात्मक समकक्षों की तरह, अपने विषयों के अनुमान के माध्यम से जानकारी देते हैं।
व्यापक स्ट्रोक में, स्केच डेटा संरचनाएं (और उनके साथ आने वाले एल्गोरिदम) होते हैं जो आपके डेटा की प्रकृति को कैप्चर करते हैं - डेटा के बारे में आपके प्रश्नों के उत्तर, वास्तव में डेटा को संग्रहीत किए बिना। औपचारिक रूप से कहा गया है, स्केच उपयोगी होते हैं क्योंकि उनके पास सबलाइनियर एसिम्प्टोटिक कम्प्यूटेशनल जटिलता होती है, इस प्रकार कम कंप्यूटिंग शक्ति और/या भंडारण की आवश्यकता होती है। लेकिन कोई मुफ्त लंच नहीं है और दक्षता में लाभ उत्तरों की सटीकता से ऑफसेट होता है। हालांकि, कई मामलों में, त्रुटियां तब तक स्वीकार्य होती हैं, जब तक उन्हें एक सीमा के नीचे रखा जा सकता है। एक अच्छा डेटा स्केच वह होता है जो अपनी त्रुटियों को आसानी से स्वीकार कर लेता है, और वास्तव में, कई स्केच अपनी त्रुटियों (या उक्त त्रुटियों की संभावना) को मापते हैं ताकि उन्हें उपयोगकर्ता द्वारा परिभाषित किया जा सके।
अच्छे रेखाचित्र कुशल होते हैं और उनमें त्रुटि की संभावना होती है, लेकिन उत्कृष्ट रेखाचित्र वे होते हैं जिनकी गणना समानांतर में की जा सकती है। एक समानांतर स्केच वह है जिसे डेटा के कुछ हिस्सों पर स्वतंत्र रूप से तैयार किया जा सकता है और जो इसके भागों को एक सार्थक और सुसंगत समुच्चय में संयोजित करने की अनुमति देता है। क्योंकि एक उत्कृष्ट स्केच के प्रत्येक टुकड़े की गणना एक अलग स्थान और/या समय पर की जा सकती है, समानांतरवाद स्केलिंग चुनौतियों को हल करने के लिए एक सीधा विभाजित और जीत के दृष्टिकोण को लागू करना संभव बनाता है।
एक बार-बार होने वाली समस्या
उपरोक्त हाइपरलॉग लॉग एक उत्कृष्ट स्केच है लेकिन यह केवल एक विशिष्ट प्रकार के प्रश्न का उत्तर देने के लिए उपयुक्त है। एक अन्य अमूल्य उपकरण काउंट मिन स्केच (सीएमएस) है, जैसा कि जी. कॉर्मोड और एस. मुथुकृष्णन द्वारा "एन इम्प्रूव्ड डेटा स्ट्रीम समरी:द काउंट-मिन स्केच एंड इट्स एप्लीकेशन्स" पेपर में वर्णित है। यह सरल कोंटरापशन नमूनों की आवृत्ति के बारे में उत्तर प्रदान करने के लिए तैयार किया गया था, विश्लेषणात्मक प्रक्रियाओं के एक बड़े प्रतिशत में एक सामान्य बिल्डिंग ब्लॉक।
पर्याप्त समय और संसाधनों को देखते हुए, नमूनों की आवृत्ति की गणना करना एक सरल प्रक्रिया है - बस प्रत्येक नमूने (देखी गई चीज़) के लिए टिप्पणियों (देखे गए समय) की गिनती रखें और फिर उस नमूने की आवृत्ति प्राप्त करने के लिए अवलोकनों की कुल संख्या से विभाजित करें। हालाँकि, उच्च-स्तरीय निम्न-विलंबता डेटा प्रोसेसिंग के संदर्भ में, कभी भी पर्याप्त समय या संसाधन नहीं होते हैं। जवाबों की आपूर्ति तुरंत की जानी चाहिए क्योंकि डेटा इसके पैमाने की परवाह किए बिना प्रवाहित होता है, और नमूना स्थान का विशाल आकार प्रत्येक नमूने के लिए एक काउंटर रखना असंभव बनाता है।
इसलिए प्रत्येक नमूने का सटीक रूप से ट्रैक रखने के बजाय, हम आवृत्ति का अनुमान लगाने का प्रयास कर सकते हैं। इसके बारे में जाने का एक तरीका यादृच्छिक रूप से अवलोकनों का नमूना लेना है और उम्मीद है कि नमूना आम तौर पर पूरे के गुणों को दर्शाता है। इस दृष्टिकोण के साथ समस्या यह है कि वास्तविक यादृच्छिकता सुनिश्चित करना एक कठिन कार्य है, इसलिए यादृच्छिक नमूने की सफलता हमारी चयन प्रक्रिया और/या डेटा के गुणों द्वारा ही सीमित हो सकती है। यही वह जगह है जहां सीएमएस एक दृष्टिकोण के साथ इतना मौलिक रूप से भिन्न होता है, कि पहली बार में, यह एक उत्कृष्ट स्केच के विपरीत लग सकता है:सीएमएस न केवल प्रत्येक अवलोकन को रिकॉर्ड करता है, प्रत्येक को कई काउंटरों में दर्ज किया जाता है!
बेशक, एक मोड़ है, और यह उतना ही चतुर है जितना सरल है। मूल पेपर (और इसका हल्का संस्करण जिसे "काउंट-मिन डेटा स्ट्रक्चर के साथ डेटा का अनुमान लगाना" कहा जाता है) इसे समझाने का एक बड़ा काम करता है, लेकिन मैं इसे वैसे भी सारांशित करने का प्रयास करूंगा। सीएमएस की चतुराई इस तरह से है कि यह नमूने संग्रहीत करता है:प्रत्येक अद्वितीय नमूने को स्वतंत्र रूप से ट्रैक करने के बजाय, यह इसके हैश मान का उपयोग करता है। एक नमूने के हैश मान का उपयोग सूचकांक के रूप में एक स्थिर आकार (कागज में d के रूप में पैरामीटर के रूप में) काउंटरों की सरणी में किया जाता है। कई (पैरामीटर w) विभिन्न हैश फ़ंक्शंस और उनके संबंधित सरणियों को नियोजित करके, स्केच नमूने के लिए सभी प्रासंगिक काउंटरों में से न्यूनतम मान चुनकर संरचना को क्वेरी करते समय पाए जाने वाले हैश टकराव को संभालता है।
एक उदाहरण के लिए कहा जाता है, तो आइए डेटा संरचना के आंतरिक कामकाज को स्पष्ट करने के लिए एक सरल स्केच बनाएं। स्केच को सरल रखने के लिए, हम छोटे पैरामीटर मानों का उपयोग करेंगे। हम w को 3 पर सेट करेंगे, जिसका अर्थ है कि हम तीन हैश फ़ंक्शंस का उपयोग करेंगे - क्रमशः h1, h2, और h3 निरूपित, और d से 4। स्केच के काउंटरों को संग्रहीत करने के लिए हम कुल 12 के साथ 3×4 सरणी का उपयोग करेंगे। तत्वों को 0 से प्रारंभ किया गया।
अब हम जांच कर सकते हैं कि क्या होता है जब नमूने स्केच में जोड़े जाते हैं। आइए मान लें कि नमूने एक-एक करके आते हैं और पहले नमूने के लिए हैश, जिसे s1 के रूप में दर्शाया गया है, हैं:h1(s1) =1, h2(s1) =2 और h3(s1) =3. स्केच में s1 रिकॉर्ड करने के लिए हम प्रासंगिक सूचकांक पर प्रत्येक हैश फ़ंक्शन के काउंटर को 1 से बढ़ा देगा। निम्न तालिका सरणी की प्रारंभिक और वर्तमान स्थिति दिखाती है:

हालाँकि स्केच में केवल एक नमूना है, हम पहले से ही इसे प्रभावी ढंग से क्वेरी कर सकते हैं। याद रखें कि एक नमूने के लिए प्रेक्षणों की संख्या उसके सभी काउंटरों में से न्यूनतम है, इसलिए s1 के लिए इसे निम्न द्वारा प्राप्त किया जाता है:
min(array[1][h1(s1)], array[2][h2(s1)], array[3][h3(s1)]) = स्केच अभी तक जोड़े नहीं गए नमूनों के बारे में प्रश्नों के उत्तर भी देता है। मान लें कि h1 (स<उप>2 ) =4, एच<उप>2 (स<उप>2 ) =4, एच<उप>3 (स<उप>2 ) =4, ध्यान दें कि s2 . के लिए क्वेरी करना परिणाम 0 लौटाएगा। आइए s2 . जोड़ना जारी रखें और एस<उप>3 (ज<उप>1 (स<उप>3 ) =1, एच<उप>2 (स<उप>3 ) =1, एच<उप>3 (स<उप>3 ) =1) स्केच के लिए, निम्नलिखित उपज:
min(array[1][1], array[2][2], array[3][3]) =
min(1,1,1) = 1

हमारे आकस्मिक उदाहरण में, लगभग सभी नमूनों के हैश अद्वितीय काउंटरों पर मैप करते हैं, एक अपवाद h1(s1) और h1(s3) की टक्कर है। क्योंकि दोनों हैश समान हैं, h1 का पहला काउंटर अब मान 2 रखता है। चूंकि स्केच सभी काउंटरों में से न्यूनतम को चुनता है, s1 और s3 के लिए क्वेरी अभी भी 1 का सही परिणाम लौटाती है। आखिरकार, हालांकि, एक बार पर्याप्त टकराव हो गया है हुआ, तो प्रश्नों के परिणाम कम सटीक हो जाएंगे।
सीएमएस के दो पैरामीटर - डब्ल्यू और डी - इसके स्थान / समय की आवश्यकताओं के साथ-साथ इसकी त्रुटि की संभावना और अधिकतम मूल्य निर्धारित करते हैं। स्केच को इनिशियलाइज़ करने का एक अधिक सहज तरीका त्रुटि की संभावना और कैप प्रदान करना है, जिससे इसे w और d के लिए आवश्यक मान प्राप्त करने की अनुमति मिलती है। समानांतरीकरण संभव है क्योंकि किसी भी संख्या में उप-रेखाचित्रों को सरणियों के योग के रूप में तुच्छ रूप से विलय किया जा सकता है, जब तक कि समान पैरामीटर और हैश फ़ंक्शन का उपयोग उनके निर्माण में किया जाता है।
काउंट-मिन स्केच के बारे में कुछ अवलोकन
काउंट मिन स्केच की दक्षता को इसकी आवश्यकताओं की समीक्षा करके प्रदर्शित किया जा सकता है। CMS की अंतरिक्ष जटिलता w, d और इसके द्वारा उपयोग किए जाने वाले काउंटरों की चौड़ाई का गुणनफल है। उदाहरण के लिए, एक स्केच जिसमें 0.01% की प्रायिकता पर 0.01% त्रुटि दर है, 10 हैश फ़ंक्शन और 2000-काउंटर सरणियों का उपयोग करके बनाया गया है। 16-बिट काउंटरों के उपयोग को मानते हुए, परिणामी स्केच की डेटा संरचना की कुल मेमोरी आवश्यकता 40KB पर होती है (अवलोकन की कुल संख्या और कुछ पॉइंटर्स को संग्रहीत करने के लिए कुछ अतिरिक्त बाइट्स की आवश्यकता होती है)। स्केच का अन्य कम्प्यूटेशनल पहलू समान रूप से प्रसन्न होता है- क्योंकि हैश फ़ंक्शन उत्पादन और गणना करने के लिए सस्ते होते हैं, डेटा संरचना तक पहुंच, चाहे पढ़ने या लिखने के लिए, निरंतर समय में भी किया जाता है।
सीएमएस के लिए और भी बहुत कुछ है; स्केच के लेखकों ने यह भी दिखाया है कि इसका उपयोग अन्य समान प्रश्नों के उत्तर देने के लिए कैसे किया जा सकता है। इनमें पर्सेंटाइल का अनुमान लगाना और भारी हिटर (लगातार आइटम) की पहचान करना शामिल है, लेकिन इस पोस्ट के दायरे से बाहर हैं।
सीएमएस निश्चित रूप से एक उत्कृष्ट स्केच है, लेकिन कम से कम दो चीजें हैं जो इसे पूर्णता प्राप्त करने से रोकती हैं। सीएमएस के बारे में मेरा पहला आरक्षण यह है कि यह पक्षपाती हो सकता है, और इस प्रकार कम संख्या में टिप्पणियों के साथ नमूनों की आवृत्तियों को कम करके आंका जा सकता है। सीएमएस का पूर्वाग्रह सर्वविदित है और कई सुधारों का सुझाव दिया गया है। सबसे हाल ही में काउंट मिन लॉग स्केच (जी. पिटेल और जी. फौक्वियर से "अनुमानित काउंटरों के साथ लगभग गिनती") है, जो अनिवार्य रूप से सीएमएस के रैखिक रजिस्टरों को लॉगरिदमिक के साथ बदल देता है ताकि सापेक्ष त्रुटि को कम किया जा सके और चौड़ाई को बढ़ाए बिना उच्च गणना की अनुमति दी जा सके। काउंटर रजिस्टरों की।
जबकि उपरोक्त आरक्षण सभी के द्वारा साझा किया जाता है (यद्यपि केवल वे जो डेटा संरचनाओं को टटोलते हैं), मेरा दूसरा आरक्षण रेडिस समुदाय के लिए अनन्य है। समझाने के लिए, मुझे रेडिस मॉड्यूल पेश करना होगा।
एक रेडिस मॉड्यूल
रेडिस मॉड्यूल का अनावरण इस साल की शुरुआत में रेडिसकॉन्फ़ में एंटीरेज़ द्वारा किया गया था और सचमुच हमारी दुनिया को उल्टा कर दिया है। सर्वर-लोड करने योग्य गतिशील पुस्तकालयों से अधिक या कम कुछ भी नहीं, मॉड्यूल रेडिस उपयोगकर्ताओं को रेडिस की तुलना में तेजी से आगे बढ़ने की अनुमति देता है और उन स्थानों पर जाता है जो पहले कभी सपने में भी नहीं देखे थे। और जबकि यह पोस्ट इस बात का परिचय नहीं है कि मॉड्यूल क्या हैं या उन्हें कैसे बनाया जाए, यह एक है (साथ ही यह पोस्ट, और यह वेबिनार)।
काउंट मिन स्केच रेडिस मॉड्यूल को लिखने के कई कारण हैं, इसकी अत्यधिक उपयोगिता के अलावा। इसका एक हिस्सा सीखने का अनुभव था और इसका एक हिस्सा मॉड्यूल एपीआई का मूल्यांकन था, लेकिन ज्यादातर रेडिस में एक नई डेटा संरचना को मॉडल करने में बहुत मज़ा आया। यह मॉड्यूल स्केच में अवलोकन जोड़ने, इसे क्वेरी करने और कई स्केच को एक में मिलाने के लिए एक रेडिस इंटरफ़ेस प्रदान करता है।
मॉड्यूल स्केच के डेटा को रेडिस स्ट्रिंग में संग्रहीत करता है और इसकी आंतरिक डेटा संरचना की कुंजी की सामग्री को मैप करने के लिए डायरेक्ट मेमोरी एक्सेस (डीएमए) का उपयोग करता है। मैंने अभी तक इस पर संपूर्ण प्रदर्शन बेंचमार्क का संचालन नहीं किया है, लेकिन स्थानीय स्तर पर इसका परीक्षण करने से मेरी प्रारंभिक धारणा यह है कि यह किसी भी कोर रेडिस कमांड के समान ही प्रदर्शनकारी है। हमारे अन्य मॉड्यूल की तरह, काउंटमिनस्केच खुला स्रोत है और मैं आपको इसे आज़माने और इसे हैक करने के लिए प्रोत्साहित करता हूँ।
साइन ऑफ करने से पहले, मैं अपना वादा निभाना चाहता हूं और सीएमएस के बारे में अपने रेडिस-विशिष्ट आरक्षण को साझा करना चाहता हूं। मुद्दा, जो अन्य रेखाचित्रों और डेटा संरचनाओं पर भी लागू होता है, यह है कि CMS के लिए आपको इसे उपयोग करने से पहले इसे सेट अप/आरंभ करने/इसे बनाने की आवश्यकता होती है। अनिवार्य प्रारंभिक चरण की आवश्यकता होती है, जैसे कि सीएमएस पैरामीटर सेटअप, रेडिस के मौलिक पैटर्न में से एक को तोड़ता है-डेटा संरचनाओं को उपयोग से पहले स्पष्ट रूप से घोषित करने की आवश्यकता नहीं है क्योंकि उन्हें ऑन-डिमांड बनाया जा सकता है। मॉड्यूल को अधिक रेडिस-ईश प्रतीत करने और उस विरोधी पैटर्न के आसपास काम करने के लिए, मॉड्यूल डिफ़ॉल्ट पैरामीटर मानों का उपयोग करता है जब एक नया स्केच निहित रूप से निहित होता है (यानी गैर-मौजूदा कुंजी पर CMS.ADD कमांड का उपयोग करना) लेकिन नए बनाने की भी अनुमति देता है दिए गए मापदंडों के साथ खाली रेखाचित्र।
संभाव्य डेटा संरचनाएं, या स्केच, अद्भुत उपकरण हैं जो हमें बड़े डेटा के विकास और विलंबता बजट के सिकुड़न को एक कुशल और पर्याप्त रूप से सटीक तरीके से बनाए रखने देते हैं। इस पोस्ट में उल्लिखित दो रेखाचित्र, और ब्लूम फ़िल्टर और टी-डाइजेस्ट जैसे अन्य, आधुनिक डेटा मोंगर के शस्त्रागार में तेजी से अपरिहार्य उपकरण बन रहे हैं। मॉड्यूल आपको कस्टम डेटा प्रकारों और कमांड के साथ रेडिस का विस्तार करने की अनुमति देता है जो मूल गति से संचालित होते हैं और डेटा तक स्थानीय पहुंच रखते हैं। संभावनाएं अनंत हैं और कुछ भी असंभव नहीं है।
Redis मॉड्यूल के बारे में अधिक जानना चाहते हैं और उन्हें कैसे विकसित करना चाहते हैं? क्या कोई डेटा संरचना है, चाहे वह संभाव्य हो या नहीं, जिस पर आप चर्चा करना चाहते हैं या रेडिस में जोड़ना चाहते हैं? बेझिझक मेरे ट्विटर अकाउंट पर या ईमेल के माध्यम से मुझसे कुछ भी संपर्क करें - मैं अत्यधिक उपलब्ध हूं 🙂


