“सादगी ही परम परिष्कार है” —लियोनार्डो दा विंची
"अधिकांश जानकारी अप्रासंगिक है और अधिकांश प्रयास बर्बाद हो जाते हैं, लेकिन केवल विशेषज्ञ ही जानता है कि क्या अनदेखा करना है ”—जेम्स क्लियर, एटॉमिक हैबिट्स
आपके पास कई अलग-अलग प्रणालियों के साथ एक फैंसी डेटा पाइपलाइन है। यह सतह पर बहुत परिष्कृत दिखता है, लेकिन यह वास्तव में हुड के नीचे एक जटिल गड़बड़ है। इसे विभिन्न टुकड़ों को जोड़ने के लिए बहुत सारे प्लंबिंग कार्य की आवश्यकता हो सकती है, इसे निरंतर निगरानी की आवश्यकता हो सकती है, इसे चलाने, डीबग करने और इसे प्रबंधित करने के लिए अद्वितीय विशेषज्ञता वाली एक बड़ी टीम की आवश्यकता हो सकती है। उल्लेख नहीं करने के लिए, जितने अधिक सिस्टम आप उपयोग करते हैं, उतने ही अधिक स्थान आप अपने डेटा को डुप्लिकेट कर रहे हैं और इसके आउट-ऑफ-सिंक या बासी होने की अधिक संभावना है। इसके अलावा, चूंकि इनमें से प्रत्येक सबसिस्टम अलग-अलग कंपनियों द्वारा स्वतंत्र रूप से विकसित किया गया है, इसलिए उनके अपग्रेड या बग फिक्स आपकी पाइपलाइन और आपकी डेटा परत को तोड़ सकते हैं।
यदि आप सावधान नहीं हैं, तो आप निम्न स्थिति का सामना कर सकते हैं जैसा कि नीचे दिए गए तीन मिनट के वीडियो में दिखाया गया है। मैं अत्यधिक अनुशंसा करता हूं कि आप आगे बढ़ने से पहले इसे देखें।

जटिलता उत्पन्न होती है क्योंकि भले ही प्रत्येक प्रणाली सतह पर सरल दिखाई दे, वे वास्तव में निम्नलिखित चर को आपकी पाइपलाइन में लाते हैं और एक टन जटिलता जोड़ सकते हैं:
- प्रोटोकॉल—सिस्टम डेटा को कैसे ट्रांसपोर्ट करता है? (HTTP, TCP, REST, GraphQL, FTP, JDBC)
- डेटा प्रारूप—सिस्टम किस प्रारूप का समर्थन करता है? (बाइनरी, सीएसवी, जेएसओएन, एवरो)
- डेटा स्कीमा और विकास—डेटा कैसे संग्रहीत किया जाता है? (टेबल, स्ट्रीम, ग्राफ़, दस्तावेज़)
- SDK और API—क्या सिस्टम आवश्यक SDK और API प्रदान करता है?
- ACID और BASE—क्या यह ACID या BASE संगति प्रदान करता है?
- माइग्रेशन—क्या सिस्टम सभी डेटा को सिस्टम में या उससे दूर माइग्रेट करने का एक आसान तरीका प्रदान करता है?
- टिकाऊपन—सिस्टम के पास टिकाऊपन की क्या गारंटी है?
- ility—सिस्टम की उपलब्धता के आसपास क्या गारंटी है? (99.9%, 99.999%)
- मापनीयता—यह कैसे मापता है?
- सुरक्षा—सिस्टम कितना सुरक्षित है?
- प्रदर्शन—डेटा को संसाधित करने में सिस्टम कितना तेज़ है?
- होस्टिंग विकल्प—क्या यह केवल होस्ट या ऑन-प्रिमाइसेस या मिश्रित है?
- बादल—क्या यह मेरे क्लाउड, क्षेत्र आदि पर काम करता है?
- अतिरिक्त सिस्टम—क्या इसके लिए अतिरिक्त सिस्टम की आवश्यकता है? (जैसे काफ्का के लिए ज़ूकीपर)
डेटा प्रारूप, स्कीमा और प्रोटोकॉल जैसे चर "परिवर्तन ओवरहेड" कहलाते हैं। प्रदर्शन, स्थायित्व और मापनीयता जैसे अन्य चर "पाइपलाइन ओवरहेड" कहलाते हैं। एक साथ रखो, ये वर्गीकरण "प्रतिबाधा बेमेल" के रूप में जाना जाता है। यदि हम इसे माप सकते हैं, तो हम जटिलता की गणना कर सकते हैं और इसका उपयोग हमारे सिस्टम को सरल बनाने के लिए कर सकते हैं। हम उस तक थोड़ी देर में पहुंचेंगे।
अब, आप यह तर्क दे सकते हैं कि आपका सिस्टम, हालांकि यह जटिल लग सकता है, वास्तव में आपकी आवश्यकताओं के लिए सबसे सरल प्रणाली है। लेकिन आप इसे कैसे साबित कर सकते हैं?
दूसरे शब्दों में, आप वास्तव में कैसे मापते हैं और बताते हैं कि आपकी डेटा परत वास्तव में सरल या जटिल है या नहीं? और दूसरी बात, आप कैसे अनुमान लगा सकते हैं कि जब आप और अधिक सुविधाएँ जोड़ते हैं तो आपका सिस्टम सरल बना रहेगा? अर्थात्, यदि आप अपने रोडमैप में और अधिक सुविधाएँ जोड़ते हैं, तो क्या आपको और सिस्टम जोड़ने की भी आवश्यकता है?
यहीं से "प्रतिबाधा बेमेल परीक्षण" आता है। लेकिन आइए पहले देखें कि एक प्रतिबाधा बेमेल क्या है और फिर हम स्वयं परीक्षण में शामिल हो जाएंगे।
प्रतिबाधा बेमेल क्या है?
विद्युत प्रतिबाधा में बेमेल की व्याख्या करने के लिए इलेक्ट्रिकल इंजीनियरिंग में शब्द उत्पन्न हुआ, जिसके परिणामस्वरूप ऊर्जा का नुकसान बिंदु A से बिंदु B पर स्थानांतरित होने पर होता है।
सीधे शब्दों में कहें तो इसका मतलब है कि आपके पास जो है वह आपकी जरूरत से मेल नहीं खाता। इसका उपयोग करने के लिए, आप जो कुछ भी आपके पास वर्तमान में है उसे लेते हैं, इसे अपनी आवश्यकता में परिवर्तित करते हैं, और फिर इसका उपयोग करते हैं। इसलिए बेमेल फिक्सिंग के साथ एक बेमेल और एक ओवरहेड जुड़ा हुआ है।
हमारे मामले में, आपके पास डेटा किसी न किसी रूप में या कुछ मात्रा में है, और इससे पहले कि हम इसका उपयोग कर सकें, आपको इसे बदलने की आवश्यकता है। परिवर्तन कई बार हो सकता है और बीच में कई प्रणालियों का उपयोग भी कर सकता है।
डेटाबेस की दुनिया में, प्रतिबाधा बेमेल दो कारणों से होता है:
- ट्रांसफॉर्मेशनल ओवरहेड:जिस तरह से सिस्टम डेटा को प्रोसेस या स्टोर करता है, वह डेटा वास्तव में कैसा दिखता है, या आप इसके बारे में कैसे सोचते हैं, इससे भिन्न होता है। उदाहरण के लिए:आपके सर्वर में, आपके पास डेटा को कई डेटा संरचनाओं, जैसे कि संग्रह, स्ट्रीम, सूचियाँ, सेट, सरणी, आदि में संग्रहीत करने की सुविधा है। यह आपको अपने डेटा को स्वाभाविक रूप से मॉडल करने में मदद करता है। हालाँकि, आपको इस डेटा को RDBMS या JSON दस्तावेज़ स्टोर में तालिकाओं में मैप करने की आवश्यकता है, ताकि उन्हें संग्रहीत किया जा सके। फिर डेटा पढ़ने के लिए इसके विपरीत करें। ध्यान दें कि ऑब्जेक्ट-ओरिएंटेड भाषा मॉडल और रिलेशनल टेबल मॉडल के बीच विशिष्ट बेमेल को "ऑब्जेक्ट-रिलेशनल इम्पीडेंस मिसमैच" के रूप में जाना जाता है।
- पाइपलाइन ओवरहेड:सर्वर में आपके द्वारा संसाधित किए जाने वाले डेटा की मात्रा और डेटा का प्रकार आपके डेटाबेस द्वारा संभाले जा सकने वाले डेटा की मात्रा से भिन्न होता है। उदाहरण के लिए:यदि आप मोबाइल उपकरणों से आने वाली लाखों घटनाओं को संसाधित कर रहे हैं, तो हो सकता है कि आपका विशिष्ट आरडीबीएमएस या दस्तावेज़ स्टोर इसे संग्रहीत करने में सक्षम न हो, या उन घटनाओं को आसानी से एकत्रित या गणना करने के लिए एपीआई प्रदान न कर सके। इसलिए आपको इसे संसाधित करने के लिए विशेष स्ट्रीम-प्रोसेसिंग सिस्टम, जैसे काफ्का या रेडिस स्ट्रीम की आवश्यकता होती है, और शायद इसे स्टोर करने के लिए एक डेटा वेयरहाउस भी।
प्रतिबाधा बेमेल परीक्षण
परीक्षण का लक्ष्य समग्र प्लेटफ़ॉर्म की जटिलता को मापना है और क्या यह जटिलता बढ़ती है या घटती है क्योंकि आप भविष्य में और अधिक सुविधाएँ जोड़ते हैं।
जिस तरह से परीक्षण काम करता है वह "प्रतिबाधा बेमेल स्कोर" (आईएमएस) का उपयोग करके "परिवर्तनकारी ओवरहेड" और "पाइपलाइन ओवरहेड" की गणना करना है। यह आपको बताएगा कि क्या आपका सिस्टम पहले से ही अन्य सिस्टम की तुलना में जटिल है, और यह भी कि क्या यह जटिलता समय के साथ बढ़ती है क्योंकि आप और अधिक सुविधाएँ जोड़ते हैं।
यहाँ IMS की गणना करने का सूत्र दिया गया है:

सूत्र बस दोनों प्रकार के ओवरहेड्स जोड़ता है और फिर उन्हें सुविधाओं की संख्या से विभाजित करता है। इस तरह, आपको कुल ओवरहेड/फीचर (यानी जटिलता स्कोर) मिल जाएगा।
इसे बेहतर ढंग से समझने के लिए, आइए चार अलग-अलग सरल डेटा पाइपलाइनों की तुलना करें और उनके स्कोर की गणना करें। और दूसरी बात, आइए यह भी कल्पना करें कि हम दो चरणों में एक साधारण ऐप बना रहे हैं, ताकि हम देख सकें कि जैसे-जैसे हम समय के साथ और अधिक सुविधाएँ जोड़ते हैं, IMS स्कोर कैसे बदलता है।
चरण 1:रीयल-टाइम डैशबोर्ड बनाना
मान लें कि आपको मोबाइल उपकरणों से लाखों बटन-क्लिक ईवेंट मिल रहे हैं और यदि कोई गिरावट या स्पाइक है तो आपको अलर्ट की आवश्यकता है। इसके अतिरिक्त, आप इस संपूर्ण चीज़ को अपने बड़े अनुप्रयोग की विशेषता मान रहे हैं।
केस 1:मान लें कि आपने इन घटनाओं को संग्रहीत करने के लिए अभी RDBMS का उपयोग किया है, हालांकि हो सकता है कि तालिकाएँ फ़िट न हों।

- परिवर्तनकारी उपरि =1
- आपको इवेंट स्ट्रीम को टेबल में बदलना होगा।
- पाइपलाइन ओवरहेड =1
- आपकी पाइपलाइन में एक ही DB है।
- सुविधाओं की संख्या =1
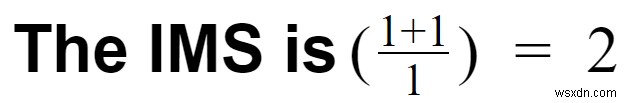
केस 2:मान लें कि आपने इन घटनाओं को संसाधित करने के लिए काफ्का का उपयोग किया और फिर उन्हें RDBMS में संग्रहीत किया।
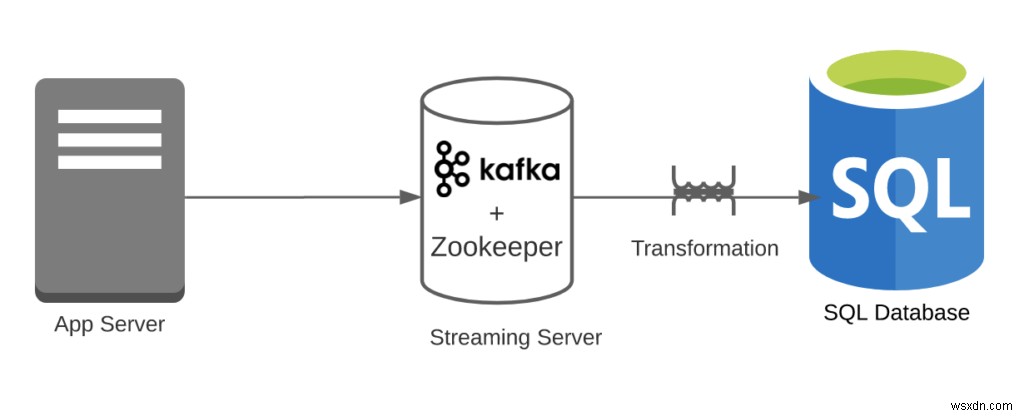
- परिवर्तनकारी उपरि =1
- काफ्का आसानी से क्लिक स्ट्रीम को संभाल सकता है; हालांकि, काफ्का से आरडीबीएमएस एक ओवरहेड है।
- पाइपलाइन ओवरहेड =2
- आपके पास दो प्रणालियां हैं (RDBMS और Kafka)। ध्यान दें कि हम ज़ूकीपर को अनदेखा कर रहे हैं।
- सुविधाओं की संख्या =1
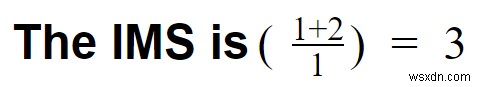
केस 3:मान लें कि आपने इन घटनाओं को संसाधित करने के लिए काफ्का का उपयोग किया और फिर उन्हें KsqlDB में संग्रहीत किया।
- परिवर्तनकारी उपरि =0
- काफ्का आसानी से क्लिक स्ट्रीम को संभाल सकता है
- पाइपलाइन ओवरहेड =1
- आपके पास सिर्फ एक सिस्टम है (काफ्का + केएसक्लडीबी)। ध्यान दें कि हम ज़ूकीपर को नज़रअंदाज़ कर रहे हैं।
- सुविधाओं की संख्या =1
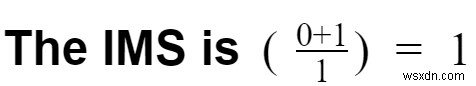
केस 4:मान लें कि आपने इन घटनाओं को संसाधित करने के लिए Redis Streams का उपयोग किया है और फिर उन्हें RedisTimeseries में संग्रहीत किया है (दोनों Redis का हिस्सा हैं और मूल रूप से Redis के साथ काम करते हैं)।

- परिवर्तनकारी उपरि =0
- Redis Streams आसानी से क्लिक स्ट्रीम को संभाल सकती हैं
- पाइपलाइन ओवरहेड =1
- आपके पास केवल एक सिस्टम है (Redis Streams + RedisTimeSeries)
- सुविधाओं की संख्या =1
चरण 1 के बाद निष्कर्ष:
हमने इस उदाहरण में चार प्रणालियों की तुलना की और पाया कि "केस 3" या "केस 4" 1 के आईएमएस के साथ सबसे सरल हैं। इस बिंदु पर, वे दोनों समान हैं, लेकिन क्या वे वही रहेंगे जब हम अधिक सुविधाएँ जोड़ते हैं ?
आइए अपने सिस्टम में और सुविधाएं जोड़ें और देखें कि IMS कैसा प्रदर्शन करता है।
चरण 2:IP-श्वेतसूचीकरण के साथ रीयल-टाइम डैशबोर्ड बनाना
मान लीजिए कि आप एक ही ऐप बना रहे हैं, लेकिन यह सुनिश्चित करना चाहते हैं कि वे केवल सफेद-सूचीबद्ध आईपी पते से आए हैं। अब आप एक नई सुविधा जोड़ रहे हैं।
केस 1:मान लें कि आपने इन घटनाओं को संग्रहीत करने के लिए अभी RDBMS का उपयोग किया है, हालाँकि तालिकाएँ फिट नहीं हो सकती हैं और उन्होंने IP-श्वेतसूची के लिए Redis या MemCached का उपयोग किया है।
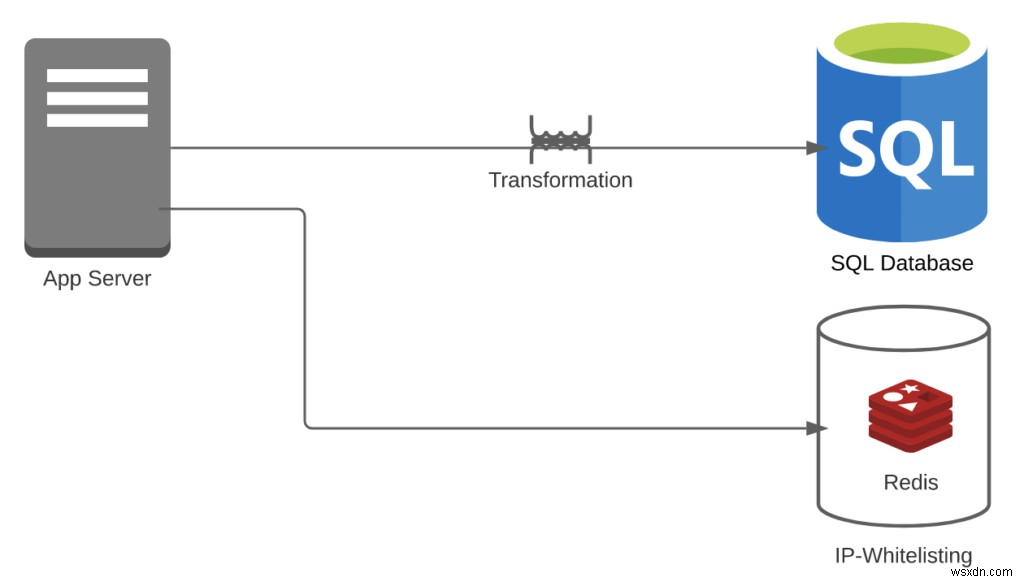
- परिवर्तनकारी उपरि =1
- आईपी-श्वेतसूची में डालने के लिए, आपको किसी परिवर्तन की आवश्यकता नहीं है। हालांकि, आपको इवेंट स्ट्रीम को टेबल में बदलना होगा
- पाइपलाइन ओवरहेड =2
- आपके पास रेडिस + आरडीबीएमएस है
- सुविधाओं की संख्या =2

केस 2:मान लें कि आप रेडिस + काफ्का + आरडीबीएमएस का उपयोग कर रहे हैं।
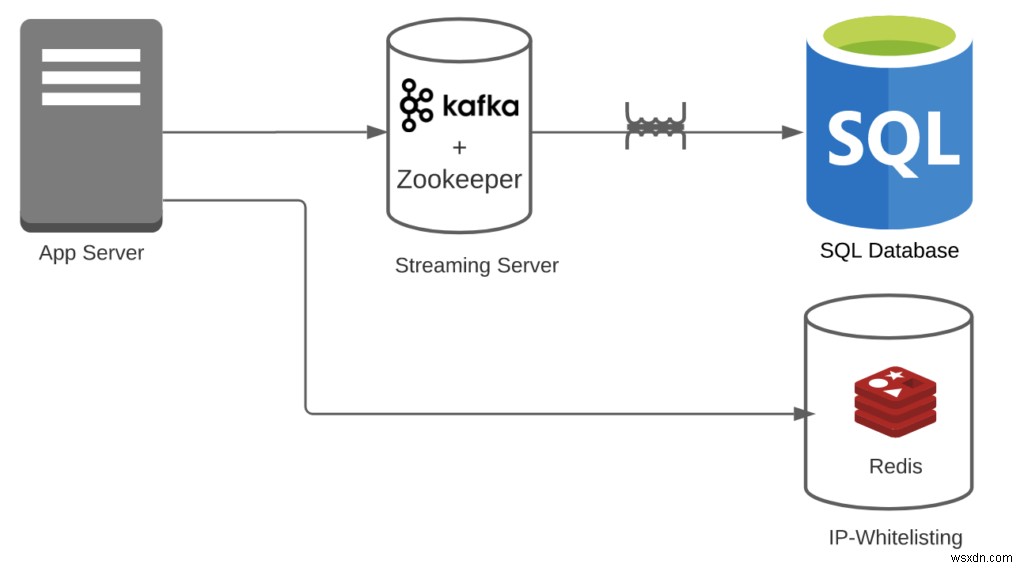
- परिवर्तनकारी उपरि =1
- आईपी-श्वेतसूची में डालने के लिए, आपको किसी परिवर्तन की आवश्यकता नहीं है। साथ ही, काफ्का आसानी से धाराओं को संभाल सकता है।
- पाइपलाइन ओवरहेड =3
- आपके पास रेडिस + काफ्का + आरडीबीएमएस है। नोट:हम इस बात को नजरअंदाज कर रहे हैं कि काफ्का को भी ज़ूकीपर की जरूरत है। अगर आप इसे जोड़ते हैं, तो संख्या और कम हो जाएगी।
- सुविधाओं की संख्या =2

केस 3:मान लें कि आप Redis + Kafka + KsqlDB का उपयोग कर रहे हैं।
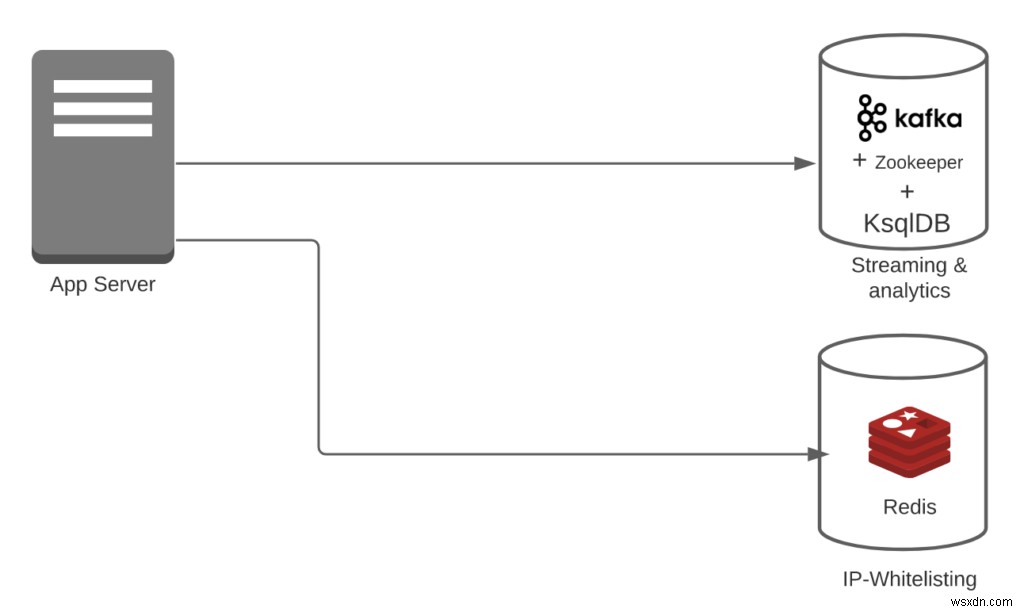
- परिवर्तनकारी उपरि =0
- आईपी-श्वेतसूची में डालने के लिए, आपको किसी परिवर्तन की आवश्यकता नहीं है। इसके अलावा, काफ्का और KsqlDB आसानी से धाराओं को संभाल सकते हैं।
- पाइपलाइन ओवरहेड =2
- आपके पास Redis + (काफ्का + KsqlDB) है। नोट:इस मामले में, हम काफ्का + KsqlDB उसी सिस्टम का हिस्सा मान रहे हैं।
- सुविधाओं की संख्या =2

केस 4:मान लें कि आप Redis + Redis Streams + RedisTimeSeries का उपयोग कर रहे हैं।

- परिवर्तनकारी उपरि =0
- आईपी-श्वेतसूची में डालने के लिए, आपको किसी परिवर्तन की आवश्यकता नहीं है। साथ ही, Redis Streams और RedisTimeseries आसानी से स्ट्रीम और अलर्ट को हैंडल कर सकते हैं।
- पाइपलाइन ओवरहेड =1
- आपके पास Redis + Redis Streams + Redis TimeSeries है। नोट:इस मामले में, तीनों एक ही सिस्टम का हिस्सा हैं।
- सुविधाओं की संख्या =2

चरण 2 के बाद निष्कर्ष:
जब हमने एक अतिरिक्त सुविधा जोड़ी,
- केस 1, फेज-1 में 2 पर था और घटकर 1.5 हो गया।
- केस 2, फेज-1 में 3 पर था और घटकर 2 हो गया
- केस 3 पहले चरण में 1 पर था और 1 पर बना रहा
- केस 4, फेज-1 में 1 पर था और घटकर 0.5 (सर्वश्रेष्ठ) हो गया
तो हमारे उदाहरण में, केस 4, जिसमें सबसे कम IMS स्कोर 1 था, वास्तव में बेहतर होता गया क्योंकि हमने नई सुविधा को जोड़ा और यह 0.5 पर समाप्त हुआ।
कृपया ध्यान दें:यदि आप अधिक या भिन्न सुविधाएँ जोड़ते हैं, तो केस 4 सबसे सरल नहीं रह सकता है। लेकिन यह आईएमएस स्कोर का विचार है। बस सभी सुविधाओं को सूचीबद्ध करें, विभिन्न आर्किटेक्चर की तुलना करें, और देखें कि आपके उपयोग के मामले में कौन सा सबसे अच्छा है।
इसका उपयोग करना और भी आसान बनाने के लिए, हम आपको एक कैलकुलेटर प्रदान कर रहे हैं जिसे आप IMS स्कोर की गणना के लिए एक साधारण स्प्रेडशीट में लागू कर सकते हैं।
IMS कैलकुलेटर
यहां बताया गया है कि आप इसका उपयोग कैसे करते हैं:
- प्रत्येक डेटा स्तर या डेटा पाइपलाइन के लिए, बस सूची बनाएं:
- वर्तमान में आपके पास मौजूद विशेषताएं।
- वे सुविधाएँ जो रोडमैप में हैं। यह महत्वपूर्ण है, क्योंकि आप यह सुनिश्चित करना चाहते हैं कि आपका डेटा स्तर बिना किसी अतिरिक्त खर्च के आगामी सुविधाओं का समर्थन करना जारी रख सके।
- फिर प्रत्येक सुविधा के लिए परिवर्तनकारी ओवरहेड और पाइपलाइन ओवरहेड को मैप करें।
- और अंत में, सभी ओवरहेड्स के योग को सुविधाओं की संख्या से विभाजित करें।
- विभिन्न प्रणालियों वाली पाइपलाइनों की तुलना और उनमें अंतर करने के लिए चरण 2 और 3 को दोहराएं।
डेटा पाइपलाइन 1
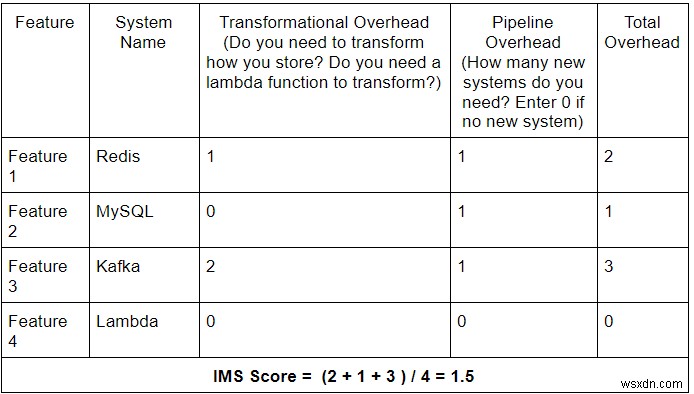
डेटा पाइपलाइन 2

सारांश
परिणामों के बारे में सोचे बिना दूर ले जाना और एक जटिल डेटा परत बनाना बहुत आसान है। IMS स्कोर आपको अपने निर्णय के प्रति सचेत रहने में मदद करने के लिए बनाया गया था।
आप अपने उपयोग के मामले के लिए कई प्रणालियों की आसानी से तुलना और तुलना करने के लिए IMS स्कोर का उपयोग कर सकते हैं और देख सकते हैं कि आपकी सुविधाओं के सेट के लिए कौन सा वास्तव में सबसे अच्छा है। आप यह भी सत्यापित कर सकते हैं कि क्या आपका सिस्टम विस्तार की सुविधा को रोक सकता है और यथासंभव सरल बना रह सकता है।
हमेशा याद रखें:
“सादगी ही परम परिष्कार है” — लियोनार्डो दा विंची
"अधिकांश जानकारी अप्रासंगिक है और अधिकांश प्रयास बर्बाद हो जाते हैं, लेकिन केवल विशेषज्ञ ही जानता है कि क्या अनदेखा करना है ”- जेम्स क्लियर, एटॉमिक हैबिट्स