एक पदानुक्रमित मॉडल एक पेड़ जैसी संरचना में डेटा का प्रतिनिधित्व करता है जिसमें प्रत्येक रिकॉर्ड के लिए एक एकल अभिभावक होता है। आदेश बनाए रखने के लिए एक सॉर्ट फ़ील्ड है जो सिबलिंग नोड्स को रिकॉर्ड तरीके से रखता है। इस प्रकार के मॉडल मूल रूप से प्रारंभिक मेनफ्रेम डेटाबेस प्रबंधन प्रणालियों के लिए डिज़ाइन किए गए हैं, जैसे IBM द्वारा सूचना प्रबंधन प्रणाली (IMS)।
यह मॉडल संरचना दो/विभिन्न प्रकार के डेटा के बीच एक-से-एक और एक-से-अनेक संबंध की अनुमति देती है। वास्तविक दुनिया में कई रिश्तों का वर्णन करने में यह संरचना बहुत मददगार है; सामग्री की तालिका, कोई नेस्टेड और सॉर्ट की गई जानकारी।
श्रेणीबद्ध संरचना का उपयोग भंडारण में अभिलेखों के भौतिक क्रम के रूप में किया जाता है। अनुक्रमिक एक्सेसिंग के साथ संयुक्त पॉइंटर्स का उपयोग करके डेटा संरचना के माध्यम से नीचे नेविगेट करके रिकॉर्ड्स तक पहुंच सकते हैं। इसलिए, जब प्रत्येक रिकॉर्ड के लिए एक पूर्ण पथ भी शामिल नहीं होता है, तो पदानुक्रमित संरचना कुछ डेटाबेस संचालन के लिए उपयुक्त नहीं होती है।
इस प्रकार के डेटाबेस में डेटा को पदानुक्रम से संरचित किया जाता है और इसे आमतौर पर एक उल्टे पेड़ के रूप में विकसित किया जाता है। संरचना में "रूट" डेटाबेस में एक एकल तालिका है और अन्य तालिकाएं रूट से बहने वाली शाखाओं के रूप में कार्य करती हैं। नीचे दिया गया चित्र एक विशिष्ट श्रेणीबद्ध डेटाबेस संरचना दिखाता है।
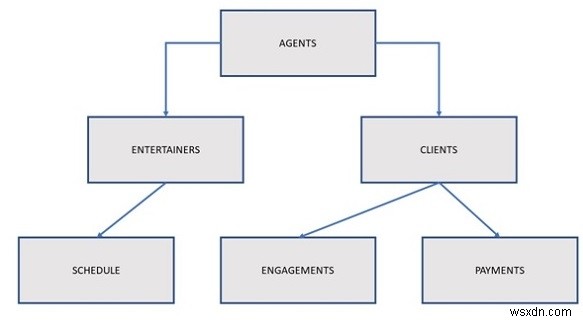
एजेंट डेटाबेस
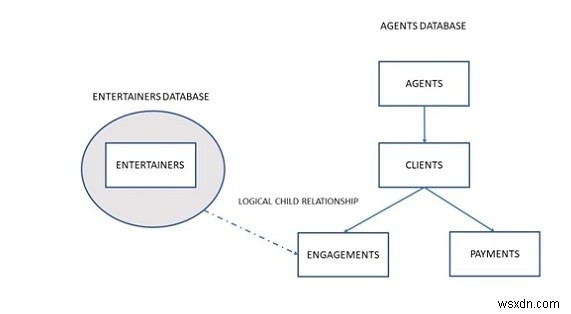
उपरोक्त आरेख में, एक एजेंट कई मनोरंजनकर्ताओं को बुक करता है, और बदले में प्रत्येक मनोरंजनकर्ता का अपना शेड्यूल होता है। एक एजेंट का यह कर्तव्य है कि वह कई ग्राहकों को बनाए रखे जिनकी मनोरंजन की जरूरतें पूरी की जानी हैं। एक ग्राहक एजेंट के माध्यम से सगाई बुक करता है और एजेंट को उसकी सेवाओं के लिए भुगतान करता है।
इस डेटाबेस मॉडल में एक संबंध माता-पिता/बच्चे शब्द द्वारा दर्शाया गया है। इस प्रकार के संबंध में एक पैरेंट टेबल को एक या एक से अधिक चाइल्ड टेबल के साथ जोड़ा जा सकता है, लेकिन एक सिंगल चाइल्ड टेबल को केवल एक पैरेंट टेबल से जोड़ा जा सकता है। तालिकाओं को एक सूचक/सूचकांक के माध्यम से या तालिकाओं के भीतर अभिलेखों की भौतिक व्यवस्था द्वारा स्पष्ट रूप से जोड़ा जाता है।
एक उपयोगकर्ता रूट टेबल से शुरू करके और ट्री के माध्यम से लक्ष्य डेटा तक काम करके डेटा तक पहुंच सकता है। उपयोगकर्ता को बिना किसी जटिलता के डेटा तक पहुंचने के लिए डेटाबेस की संरचना से परिचित होना चाहिए।
फायदे
- तालिका संरचनाओं के बीच स्पष्ट लिंक की उपस्थिति के कारण एक उपयोगकर्ता बहुत जल्दी डेटा पुनर्प्राप्त कर सकता है।
- संदर्भात्मक अखंडता अंतर्निहित है और स्वचालित रूप से लागू की गई है जिसके कारण चाइल्ड टेबल में रिकॉर्ड को पैरेंट टेबल में मौजूदा रिकॉर्ड से जोड़ा जाना चाहिए, इसके साथ ही अगर पैरेंट टेबल में कोई रिकॉर्ड हटा दिया जाता है तो इससे सभी संबद्ध चाइल्ड टेबल के रिकॉर्ड भी मिटाए जाने हैं।
नुकसान
- जब किसी उपयोगकर्ता को चाइल्ड टेबल में एक रिकॉर्ड स्टोर करने की आवश्यकता होती है जो वर्तमान में पैरेंट टेबल में किसी भी रिकॉर्ड से असंबंधित है, तो उसे रिकॉर्डिंग में कठिनाई होती है और उपयोगकर्ता को पैरेंट टेबल में एक अतिरिक्त प्रविष्टि रिकॉर्ड करनी होगी।
- इस प्रकार का डेटाबेस जटिल संबंधों का समर्थन नहीं कर सकता है, और अतिरेक की समस्या भी है, जिसके परिणामस्वरूप विभिन्न साइटों पर डेटा की असंगत रिकॉर्डिंग के कारण गलत जानकारी उत्पन्न हो सकती है।
पिछले आरेख में दिखाए गए डेटाबेस आरेख का उपयोग करके एक उदाहरण पर विचार करें। एक उपयोगकर्ता एंटरटेनर टेबल में एंटरटेनर के लिए एक नया रिकॉर्ड तब तक दर्ज नहीं कर सकता जब तक कि एंटरटेनर को एजेंट्स टेबल में एक विशिष्ट एजेंट को असाइन नहीं किया जाता है क्योंकि चाइल्ड टेबल (एंटरटेनर्स) में एक रिकॉर्ड पैरेंट टेबल (एजेंट) में एक रिकॉर्ड से संबंधित होना चाहिए। . इसलिए, इस प्रकार का डेटाबेस निरर्थक डेटा की समस्या से ग्रस्त है। उदाहरण के लिए, यदि क्लाइंट और मनोरंजन करने वालों के बीच कई-से-अनेक संबंध हैं; एक मनोरंजनकर्ता कई ग्राहकों के लिए प्रदर्शन करेगा, और एक ग्राहक कई मनोरंजनकर्ताओं को काम पर रखेगा। पदानुक्रमित डेटाबेस में इस प्रकार का संबंध आसानी से मॉडल नहीं हो सकता है, इसलिए डेवलपर्स को शेड्यूल और एंगेजमेंट टेबल दोनों में अनावश्यक डेटा पेश करना चाहिए।
- शेड्यूल टेबल में अब क्लाइंट डेटा होगा जिसमें क्लाइंट का नाम, पता और फोन नंबर जैसी जानकारी शामिल होगी, ताकि यह दिखाया जा सके कि प्रत्येक एंटरटेनर किसके लिए और कहां परफॉर्म कर रहा है। यह डेटा अनावश्यक है क्योंकि यह वर्तमान में क्लाइंट तालिका में भी संग्रहीत है।
- एंगेजमेंट टेबल में अब एंटरटेनर्स का डेटा होगा जिसमें एंटरटेनर का नाम, फोन नंबर और एंटरटेनर के प्रकार जैसी जानकारी होती है, जो यह दर्शाता है कि किसी दिए गए क्लाइंट के लिए कौन से एंटरटेनर परफॉर्म कर रहे हैं। यह डेटा भी बेमानी है क्योंकि यह वर्तमान में एंटरटेनर्स टेबल में संग्रहीत है।
इस अतिरेक के साथ समस्या यह है कि इसके परिणामस्वरूप गलत जानकारी उत्पन्न हो सकती है क्योंकि यह उपयोगकर्ता को डेटा के एक टुकड़े को असंगत रूप से दर्ज करने की अनुमति देने की संभावना को खोलता है।
इस समस्या को विशेष रूप से मनोरंजन करने वालों के लिए एक पदानुक्रमित डेटाबेस और विशेष रूप से एजेंटों के लिए एक अन्य डेटाबेस बनाकर हल किया जा सकता है। एंटरटेनर्स डेटाबेस में केवल एंटरटेनर्स टेबल में रिकॉर्ड किया गया डेटा होगा, और संशोधित एजेंट्स डेटाबेस में एजेंट्स, क्लाइंट्स, पेमेंट्स और एंगेजमेंट टेबल में रिकॉर्ड किया गया डेटा होगा। इसकी कोई आवश्यकता नहीं है क्योंकि आप एजेंट्स डेटाबेस में एंगेजमेंट टेबल और एंटरटेनर्स डेटाबेस में एंटरटेनर्स टेबल के बीच तार्किक चाइल्ड रिलेशनशिप को परिभाषित कर सकते हैं। इस संबंध के साथ, आप विभिन्न प्रकार की जानकारी प्राप्त कर सकते हैं, जैसे किसी दिए गए ग्राहक के लिए बुक किए गए मनोरंजनकर्ताओं की सूची या किसी मनोरंजनकर्ता के लिए प्रदर्शन कार्यक्रम। नीचे दिया गया चित्र पूरी तस्वीर का वर्णन करता है।
पदानुक्रमित डेटाबेस टेप स्टोरेज सिस्टम के लिए अच्छी तरह से अनुकूल है जो 1970 के दशक में मेनफ्रेम द्वारा उपयोग किया जाता है और उन संगठनों में बहुत लोकप्रिय था जिनका डेटाबेस उन सिस्टम पर आधारित है। लेकिन, भले ही पदानुक्रमित डेटाबेस ने डेटा तक तेज़ और सीधी पहुंच प्रदान की और कई परिस्थितियों में उपयोगी था, यह स्पष्ट था कि डेटा अतिरेक और डेटा के बीच जटिल संबंधों की बढ़ती समस्याओं को दूर करने के लिए एक नए डेटाबेस मॉडल की आवश्यकता थी।
इस डेटाबेस मॉडल के पीछे का विचार एक निश्चित प्रकार के डेटा संग्रहण के लिए उपयोगी है, लेकिन यह अत्यंत बहुमुखी नहीं है और कुछ विशिष्ट उपयोगों तक ही सीमित है।
उदाहरण के लिए, जहां किसी कंपनी में प्रत्येक व्यक्ति किसी दिए गए विभाग को रिपोर्ट कर सकता है, विभाग का उपयोग मूल रिकॉर्ड के रूप में किया जा सकता है और व्यक्तिगत कर्मचारी द्वितीयक रिकॉर्ड का प्रतिनिधित्व करेंगे, जिनमें से प्रत्येक उस एक से वापस लिंक करता है एक पदानुक्रमित संरचना में मूल रिकॉर्ड।