हर व्यवसाय ग्राहक की वफादारी पर निर्भर करता है। ग्राहक से दोहराना व्यवसाय व्यावसायिक लाभप्रदता के लिए आधारशिला में से एक है। इसलिए ग्राहकों के व्यवसाय छोड़ने का कारण जानना महत्वपूर्ण है। दूर जाने वाले ग्राहकों को ग्राहक मंथन के रूप में जाना जाता है। पिछले रुझानों को देखकर हम यह आंक सकते हैं कि ग्राहक मंथन को कौन से कारक प्रभावित करते हैं और यह कैसे अनुमान लगाया जाए कि कोई विशेष ग्राहक व्यवसाय से दूर चला जाएगा। इस लेख में हम ग्राहक मंथन में पिछले रुझानों का अध्ययन करने के लिए एमएल एल्गोरिदम का उपयोग करेंगे और फिर निर्णय लेंगे कि कौन से ग्राहक मंथन कर सकते हैं।
डेटा तैयार करना
एक उदाहरण के रूप में इस लेख के लिए टेलीकॉम ग्राहक मंथन पर विचार करेंगे। स्रोत डेटा कागेल पर उपलब्ध है। डेटा डाउनलोड करने के लिए URL का उल्लेख नीचे दिए गए प्रोग्राम में किया गया है। हम csv फ़ाइल को Python प्रोग्राम में लोड करने और कुछ नमूना पंक्तियों को देखने के लिए पांडा लाइब्रेरी का उपयोग करते हैं।
उदाहरण
import pandas as pd
#Loading the Telco-Customer-Churn.csv dataset
#https://www.kaggle.com/blastchar/telco-customer-churn
datainput = pd.read_csv('E:\\Telecom_customers.csv')
print("Given input data :\n",datainput) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
Given input data : customerID gender SeniorCitizen ... MonthlyCharges TotalCharges Churn 0 7590-VHVEG Female 0 ... 29.85 29.85 No 1 5575-GNVDE Male 0 ... 56.95 1889.5 No 2 3668-QPYBK Male 0 ... 53.85 108.15 Yes 3 7795-CFOCW Male 0 ... 42.30 1840.75 No 4 9237-HQITU Female 0 ... 70.70 151.65 Yes ... ... ... ... ... ... ... ... 7038 6840-RESVB Male 0 ... 84.80 1990.5 No 7039 2234-XADUH Female 0 ... 103.20 7362.9 No 7040 4801-JZAZL Female 0 ... 29.60 346.45 No 7041 8361-LTMKD Male 1 ... 74.40 306.6 Yes 7042 3186-AJIEK Male 0 ... 105.65 6844.5 No [7043 rows x 21 columns]
मौजूदा पैटर्न का अध्ययन करें
अगला हम श्रृंखला के होने के मौजूदा पैटर्न को खोजने के लिए डेटा सेट का अध्ययन करते हैं। हम डेटा मित्र से कुछ कॉलम भी छोड़ते हैं जो स्थिति को प्रभावित नहीं करता है। उदाहरण के लिए, ग्राहक आईडी कॉलम का ग्राहक पर कोई प्रभाव नहीं पड़ेगा, इसलिए हम ड्रॉप ऑल पॉप पद्धति का उपयोग करके ऐसे कॉलम को छोड़ देते हैं। फिर हम दिए गए डेटा सेट में संभावना का प्रतिशत दिखाते हुए एक चार्ट बनाते हैं।
उदाहरण 2
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
#Loading the Telco-Customer-Churn.csv dataset
#https://www.kaggle.com/blastchar/telco-customer-churn
datainput = pd.read_csv('E:\\Telecom_customers.csv')
print("Given input data :\n",datainput)
#Dropping columns
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
data = datainput['Churn'].value_counts(sort = True)
chroma = ["#BDFCC9","#FFDEAD"]
rcParams['figure.figsize'] = 9,9
explode = [0.2,0.2]
plt.pie(data, explode=explode, colors=chroma, autopct='%1.1f%%', shadow=True, startangle=180,)
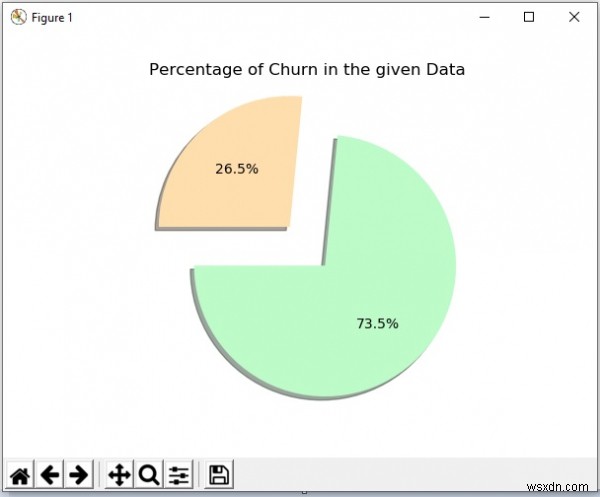
plt.title('Percentage of Churn in the given Data')
plt.show() आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
डेटा प्रीप्रोसेसिंग
डेटा को एमएल एल्गोरिदम द्वारा उपयोग के लिए तैयार करने के लिए, हम सभी क्षेत्रों को लेबल करते हैं। हम टेक्स्ट वैल्यू को न्यूमेरिक फ्लैग में भी बदलते हैं। उदाहरण के लिए, लिंग कॉलम में मान पुरुष और महिला के बजाय 0 और 1 में बदल जाते हैं। यह गणना और एल्गोरिदम में उन क्षेत्रों का उपयोग करने में मदद करता है जो मंथन मूल्य पर इन क्षेत्रों के प्रभाव का मूल्यांकन करेंगे। हम sklearn से LabelEncoder विधि का उपयोग करते हैं।
उदाहरण 3
import pandas as pd
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
print("\nseparated X and y :")
print("y -",y)
print("X -",X) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
input data after label encoder customerID gender SeniorCitizen ... MonthlyCharges TotalCharges Churn 0 7590-VHVEG 0 0 ... 29.85 29.85 0 1 5575-GNVDE 1 0 ... 56.95 1889.5 0 2 3668-QPYBK 1 0 ... 53.85 108.15 1 3 7795-CFOCW 1 0 ... 42.30 1840.75 0 4 9237-HQITU 0 0 ... 70.70 151.65 1 ... ... ... ... ... ... ... ... 7038 6840-RESVB 1 0 ... 84.80 1990.5 0 7039 2234-XADUH 0 0 ... 103.20 7362.9 0 7040 4801-JZAZL 0 0 ... 29.60 346.45 0 7041 8361-LTMKD 1 1 ... 74.40 306.6 1 7042 3186-AJIEK 1 0 ... 105.65 6844.5 0 [7043 rows x 21 columns] separated X and y : y - [0 0 1 ... 0 1 0] X - customerID gender ... MonthlyCharges TotalCharges 0 7590-VHVEG 0 ... 29.85 29.85 1 5575-GNVDE 1 ... 56.95 1889.5 2 3668-QPYBK 1 ... 53.85 108.15 3 7795-CFOCW 1 ... 42.30 1840.75 4 9237-HQITU 0 ... 70.70 151.65 ... ... ... ... ... ... 7038 6840-RESVB 1 ... 84.80 1990.5 7039 2234-XADUH 0 ... 103.20 7362.9 7040 4801-JZAZL 0 ... 29.60 346.45 7041 8361-LTMKD 1 ... 74.40 306.6 7042 3186-AJIEK 1 ... 105.65 6844.5 [7043 rows x 20 columns]
डेटा का प्रशिक्षण और परीक्षण
अब हम डेटा सेट को दो भागों में विभाजित करते हैं। एक प्रशिक्षण के लिए है और दूसरा परीक्षण के लिए है। test_size पैरामीटर का उपयोग यह तय करने के लिए किया जाता है कि डेटा सेट का कितना प्रतिशत केवल परीक्षण के लिए उपयोग किया जाएगा। यह अभ्यास हमें उस मॉडल पर विश्वास हासिल करने में मदद करेगा जो हम बना रहे हैं। फिर हम लॉजिस्टिक रिग्रेशन एल्गोरिथम लागू करते हैं और अनुमानित मूल्यों का पता लगाते हैं।
उदाहरण
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
#Loading the Telco-Customer-Churn.csv dataset with pandas
datainput = pd.read_csv('E:\\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
print("\npredicted values :\n",Y_pred) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
predicted values : [0 0 1 ... 0 1 0]
मूल्यांकन पैरामीटर ढूँढना
एक बार जब उपरोक्त चरण में सटीकता का स्तर स्वीकार्य हो जाता है तो हम विभिन्न मापदंडों का पता लगाकर मॉडल के और मूल्यांकन पर जाते हैं। हम अपने मापदंडों के रूप में सटीकता और भ्रम मैट्रिक्स का उपयोग यह निर्धारित करने के लिए करते हैं कि यह मॉडल कितना सही व्यवहार कर रहा है। सटीकता मूल्य का एक उच्च प्रतिशत मॉडल को बेहतर फिट के रूप में सुझाता है। इसी तरह भ्रम मैट्रिक्स सच्चे सकारात्मक, सच्चे नकारात्मक, झूठी सकारात्मक और झूठी नकारात्मक का एक मैट्रिक्स दिखाता है। झूठे मूल्यों की तुलना में वास्तविक मूल्यों का उच्च प्रतिशत बेहतर मॉडल का संकेत है।
उदाहरण
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.metrics import confusion_matrix
#Loading the Telco-Customer-Churn.csv dataset with pandas
datainput = pd.read_csv('E:\\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
#Accuracy
LR = metrics.accuracy_score(Y_test, Y_pred) * 100
print("\nThe accuracy score using the LR is -> ",LR)
#confusion matrix
cm=confusion_matrix(Y_test,Y_pred)
print("\nconfusion matrix : \n",cm) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
The accuracy score using the LR is -> 80.8374733853797 confusion matrix : [[928 109] [161 211]]
चर का वजन
इसके बाद हम निर्णय लेते हैं कि प्रत्येक क्षेत्र या चर मंथन मूल्य को कैसे प्रभावित करता है। यह हमें उन विशिष्ट चरों को लक्षित करने में मदद करेगा जो मंथन पर अधिक प्रभाव डालेंगे और ग्राहक मंथन को रोकने में उन चरों को संभालने का प्रयास करेंगे। इसके लिए हम अपने क्लासिफायरियर में गुणांक को शून्य पर सेट करते हैं और प्रत्येक चर का भार प्राप्त करते हैं।
उदाहरण
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LogisticRegression
#Loading the dataset with pandas
datainput = pd.read_csv('E:\\Telecom_customers.csv')
datainput.drop(['customerID'], axis=1, inplace=True)
datainput.pop('TotalCharges')
datainput['OnlineBackup'].unique()
#LabelEncoder()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
datainput['gender'] = label_encoder.fit_transform(datainput['gender'])
datainput['Partner'] = label_encoder.fit_transform(datainput['Partner'])
datainput['Dependents'] = label_encoder.fit_transform(datainput['Dependents'])
datainput['PhoneService'] = label_encoder.fit_transform(datainput['PhoneService'])
datainput['MultipleLines'] = label_encoder.fit_transform(datainput['MultipleLines'])
datainput['InternetService'] = label_encoder.fit_transform(datainput['InternetService'])
datainput['OnlineSecurity'] = label_encoder.fit_transform(datainput['OnlineSecurity'])
datainput['OnlineBackup'] = label_encoder.fit_transform(datainput['OnlineBackup'])
datainput['DeviceProtection'] = label_encoder.fit_transform(datainput['DeviceProtection'])
datainput['TechSupport'] = label_encoder.fit_transform(datainput['TechSupport'])
datainput['StreamingTV'] = label_encoder.fit_transform(datainput['StreamingTV'])
datainput['StreamingMovies'] = label_encoder.fit_transform(datainput['StreamingMovies'])
datainput['Contract'] = label_encoder.fit_transform(datainput['Contract'])
datainput['PaperlessBilling'] = label_encoder.fit_transform(datainput['PaperlessBilling'])
datainput['PaymentMethod'] = label_encoder.fit_transform(datainput['PaymentMethod'])
datainput['Churn'] = label_encoder.fit_transform(datainput['Churn'])
#print("input data after label encoder :\n",datainput)
#separating features(X) and label(y)
datainput["Churn"] = datainput["Churn"].astype(int)
Y = datainput["Churn"].values
X = datainput.drop(labels = ["Churn"],axis = 1)
#
#train_test_split method
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#
#LogisticRegression
classifier=LogisticRegression()
classifier.fit(X_train,Y_train)
Y_pred=classifier.predict(X_test)
#weights of all the variables
wt = pd.Series(classifier.coef_[0], index=X.columns.values)
print("\nweight of all the variables :")
print(wt.sort_values(ascending=False)) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
weight of all the variables : PaperlessBilling 0.389379 SeniorCitizen 0.246504 InternetService 0.209283 Partner 0.067855 StreamingMovies 0.054309 MultipleLines 0.042330 PaymentMethod 0.039134 MonthlyCharges 0.027180 StreamingTV -0.008606 gender -0.029547 tenure -0.034668 DeviceProtection -0.052690 OnlineBackup -0.143625 Dependents -0.209667 OnlineSecurity -0.245952 TechSupport -0.254740 Contract -0.729557 PhoneService -0.950555 dtype: float64