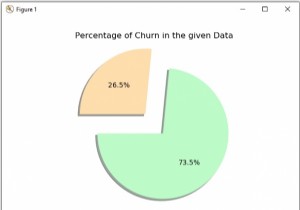
धोखाधड़ी वास्तव में कई लेन-देन में होती है। हम पिछले डेटा को झूठ बोलने के लिए मशीन लर्निंग एल्गोरिदम लागू कर सकते हैं और लेनदेन की धोखाधड़ी लेनदेन होने की संभावना का अनुमान लगा सकते हैं। हमारे उदाहरण में हम क्रेडिट कार्ड लेनदेन लेंगे, डेटा का विश्लेषण करेंगे, सुविधाओं और लेबल बनाएंगे और अंत में लेनदेन की प्रकृति को धोखाधड़ी के रूप में न्याय करने के लिए एमएल एल्गोरिदम में से एक को लागू करेंगे या नहीं। फिर हम अपने द्वारा चुने गए मॉडल की सटीकता, सटीकता और f-स्कोर का पता लगाएंगे।
डेटा तैयार करना
हम इस चरण में स्रोत डेटा को पढ़ते हैं, उसमें मौजूद चर का अध्ययन करते हैं और कुछ नमूना डेटा पर एक नज़र डालते हैं। इससे हमें डेटा सेट में मौजूद विभिन्न कॉलमों को जानने और उनकी विशेषताओं का अध्ययन करने में मदद मिलेगी। हम डेटा फ्रेम बनाने के लिए पंडों की लाइब्रेरी का उपयोग करेंगे जिसका उपयोग बाद के चरणों में किया जाएगा।
उदाहरण
import pandas as pd
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
#https://www.kaggle.com/mlg-ulb/creditcardfraud
# Print the top 5 records
print(datainput[0:5],"\n")
# Print the complete shape of the dataset
print("Shape of Complete Data Set")
print(datainput.shape,"\n") आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
Time V1 V2 V3 ... V27 V28 Amount Class 0 0.0 -1.359807 -0.072781 2.536347 ... 0.133558 -0.021053 149.62 0 1 0.0 1.191857 0.266151 0.166480 ... -0.008983 0.014724 2.69 0 2 1.0 -1.358354 -1.340163 1.773209 ... -0.055353 -0.059752 378.66 0 3 1.0 -0.966272 -0.185226 1.792993 ... 0.062723 0.061458 123.50 0 4 2.0 -1.158233 0.877737 1.548718 ... 0.219422 0.215153 69.99 0 [5 rows x 31 columns] Shape of Complete Data Set (284807, 31)
डेटा में असंतुलन की जांच करना
अब हम जांचते हैं कि धोखाधड़ी और वास्तविक लेनदेन के बीच डेटा कैसे वितरित किया जाता है। इससे हमें अंदाजा हो जाता है कि कितने प्रतिशत डेटा के फर्जी होने की आशंका है। एमएल एल्गोरिथम में इसे डेटा असंतुलन के रूप में जाना जाता है। यदि अधिकांश लेन-देन धोखाधड़ी नहीं है तो कुछ लेन-देन को वास्तविक या नहीं के रूप में आंकना मुश्किल हो जाता है। हम लेन-देन में धोखाधड़ी वाले इंजन की संख्या की गणना करने के लिए क्लास कॉलम का उपयोग करते हैं और फिर धोखाधड़ी वाले लेनदेन के वास्तविक प्रतिशत का पता लगाते हैं।
उदाहरण
import pandas as pd
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
false = datainput[datainput['Class'] == 1]
true = datainput[datainput['Class'] == 0]
n = len(false)/float(len(true))
print(n)
print('False Detection Cases: {}'.format(len(datainput[datainput['Class'] == 1])))
print('True Detection Cases: {}'.format(len(datainput[datainput['Class'] == 0])),"\n") आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
0.0017304750013189597 False Detection Cases: 492 True Detection Cases: 284315
लेन-देन के प्रकार का विवरण
हम धोखाधड़ी और गैर-धोखाधड़ी लेनदेन की प्रत्येक श्रेणी के लिए लेनदेन की प्रकृति की और जांच करते हैं। हम सांख्यिकीय रूप से विभिन्न मानकों का अनुमान लगाने का प्रयास करते हैं जैसे औसत मानक विचलन अधिकतम मूल्य न्यूनतम मूल्य और विभिन्न प्रतिशतक। यह वर्णित विधि का उपयोग करके प्राप्त किया जाता है।
उदाहरण
import pandas as pd
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
#Check for imbalance in data
false = datainput[datainput['Class'] == 1]
true = datainput[datainput['Class'] == 0]
#False Detection Cases
print("False Detection Cases")
print("----------------------")
print(false.Amount.describe(),"\n")
#True Detection Cases
print("True Detection Cases")
print("----------------------")
print(true.Amount.describe(),"\n") आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
False Detection Cases ---------------------- count 492.000000 mean 122.211321 std 256.683288 min 0.000000 25% 1.000000 50% 9.250000 75% 105.890000 max 2125.870000 Name: Amount, dtype: float64 True Detection Cases ---------------------- count 284315.000000 mean 88.291022 std 250.105092 min 0.000000 25% 5.650000 50% 22.000000 75% 77.050000 max 25691.160000 Name: Amount, dtype: float64
सुविधाओं और लेबल को अलग करना
एमएल एल्गोरिथम को लागू करने से पहले, हमें सुविधाओं और लेबल पर निर्णय लेने की आवश्यकता है। जिसका मूल रूप से अर्थ आश्रित चरों और स्वतंत्र चरों को वर्गीकृत करना है। हमारे डेटासेट में क्लास कॉलम बाकी सभी कॉलम पर निर्भर है। इसलिए हम अंतिम कॉलम के लिए एक डेटा फ़्रेम बनाते हैं और साथ ही अन्य सभी कॉलम के लिए एक अन्य डेटाफ़्रेम बनाते हैं। इन डेटाफ़्रेम का उपयोग उस मॉडल को प्रशिक्षित करने के लिए किया जाएगा जिसे हम बनाने जा रहे हैं।
उदाहरण
import pandas as pd
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
#separating features(X) and label(y)
# Select all columns except the last for all rows
X = datainput.iloc[:, :-1].values
# Select the last column of all rows
Y = datainput.iloc[:, -1].values
print(X.shape)
print(Y.shape) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
(284807, 30) (284807,)
मॉडल को प्रशिक्षित करें
अब हम डेटा सेट को दो भागों में विभाजित करते हैं। एक प्रशिक्षण के लिए है और दूसरा परीक्षण के लिए है। test_size पैरामीटर का उपयोग यह तय करने के लिए किया जाता है कि डेटा सेट का कितना प्रतिशत केवल परीक्षण के लिए उपयोग किया जाएगा। यह अभ्यास हमें उस मॉडल पर विश्वास हासिल करने में मदद करेगा जो हम बना रहे हैं।
उदाहरण
import pandas as pd
from sklearn.model_selection import train_test_split
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
#separating features(X) and label(y)
X = datainput.iloc[:, :-1].values
# Select the last column of all rows
Y = datainput.iloc[:, -1].values
#train_test_split method
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2) निर्णय वृक्ष वर्गीकरण लागू करना
इस स्थिति पर लागू होने के लिए कई अलग-अलग प्रकार के एल्गोरिदम उपलब्ध हैं। लेकिन हम वर्गीकरण के लिए अपने एल्गोरिदम के रूप में निर्णय वृक्ष चुनते हैं। जो 4 की अधिकतम वृक्ष गहराई है और मूल्यों की भविष्यवाणी करने के लिए परीक्षण नमूने की आपूर्ति करता है। अंत में, हम यह तय करने के लिए परीक्षण से परिणाम की सटीकता की गणना करते हैं कि इस एल्गोरिथम के साथ आगे बढ़ना है या नहीं।
उदाहरण
import pandas as pd
from sklearn import metrics
from sklearn.model_selection import train_test_split
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
#separating features(X) and label(y)
X = datainput.iloc[:, :-1].values
Y = datainput.iloc[:, -1].values
#train_test_split method
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
classifier=DecisionTreeClassifier(max_depth=4)
classifier.fit(X_train,Y_train)
predicted=classifier.predict(X_test)
print("\npredicted values :\n",predicted)
#Accuracy
DT = metrics.accuracy_score(Y_test, predicted) * 100
print("\nThe accuracy score using the DecisionTreeClassifier : ",DT) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
predicted values : [0 0 0 ... 0 0 0] The accuracy score using the DecisionTreeClassifier : 99.9367999719111
मूल्यांकन पैरामीटर ढूँढना
एक बार जब उपरोक्त चरण में सटीकता का स्तर स्वीकार्य हो जाता है तो हम विभिन्न मापदंडों का पता लगाकर मॉडल के और मूल्यांकन पर जाते हैं। जो हमारे मापदंडों के रूप में प्रेसिजन, रिकॉल वैल्यू और एफ स्कोर का उपयोग करते हैं। सटीक पुनर्प्राप्त किए गए उदाहरणों के बीच प्रासंगिक उदाहरणों का अंश है, जबकि रिकॉल प्रासंगिक उदाहरणों की कुल राशि का अंश है जो वास्तव में पुनर्प्राप्त किए गए थे। एफ स्कोर एक एकल स्कोर प्रदान करता है जो एक ही संख्या में सटीकता और याद करने की चिंताओं दोनों को संतुलित करता है।
उदाहरण
import pandas as pd
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
#Load the creditcard.csv using pandas
datainput = pd.read_csv('E:\\creditcard.csv')
#separating features(X) and label(y)
X = datainput.iloc[:, :-1].values
Y = datainput.iloc[:, -1].values
#train_test_split method
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
#DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
classifier=DecisionTreeClassifier(max_depth=4)
classifier.fit(X_train,Y_train)
predicted=classifier.predict(X_test)
print("\npredicted values :\n",predicted)
#
# #Accuracy
DT = metrics.accuracy_score(Y_test, predicted) * 100
print("\nThe accuracy score using the DecisionTreeClassifier : ",DT)
#
# #Precision
print('precision')
# Precision = TP / (TP + FP) (Where TP = True Positive, TN = True Negative, FP = False Positive, FN = False Negative).
precision = precision_score(Y_test, predicted, pos_label=1)
print(precision_score(Y_test, predicted, pos_label=1))
#Recall
print('recall')
# Recall = TP / (TP + FN)
recall = recall_score(Y_test, predicted, pos_label=1)
print(recall_score(Y_test, predicted, pos_label=1))
#f1-score
print('f-Score')
# F - scores are a statistical method for determining accuracy accounting for both precision and recall.
fscore = f1_score(Y_test, predicted, pos_label=1)
print(f1_score(Y_test, predicted, pos_label=1)) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
The accuracy score using the DecisionTreeClassifier : 99.9403110845827 precision 0.810126582278481 recall 0.7710843373493976 f-Score 0.7901234567901234