जनगणना किसी दी गई आबादी के बारे में व्यवस्थित तरीके से जानकारी दर्ज करने के बारे में है। कैप्चर किए गए डेटा में विभिन्न श्रेणी की जानकारी शामिल होती है जैसे - जनसांख्यिकीय, आर्थिक, आवास विवरण आदि। यह अंततः सरकार को वर्तमान परिदृश्य को समझने के साथ-साथ भविष्य के लिए योजना बनाने में मदद करता है। इस लेख में हम देखेंगे कि भारतीय आबादी के लिए जनगणना के आंकड़ों का विश्लेषण करने के लिए अजगर का लाभ कैसे उठाया जाए। हम विभिन्न जनसांख्यिकीय और आर्थिक पहलुओं को देखेंगे। फिर प्लॉट चार्ज जो विश्लेषण को ग्राफिकल तरीके से पेश करेगा। वह स्रोत जो कागल से एकत्र किया जाता है। यह यहाँ स्थित है।
डेटा व्यवस्थित करना
नीचे दिए गए प्रोग्राम में पहले हम एक छोटे पायथन प्रोग्राम का उपयोग करके डेटा प्राप्त करते हैं। यह आगे के विश्लेषण के लिए डेटा को पांडा डेटाफ्रेम में लोड करता है। आउटपुट कुछ क्षेत्रों को सरल प्रतिनिधित्व के लिए दिखाता है।
उदाहरण
import pandas as pd
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
#https://www.kaggle.com/danofer/india-census#india-districts-census-2011.csv
print(datainput) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
District code ... Total_Power_Parity 0 1 ... 1119 1 2 ... 1066 2 3 ... 242 3 4 ... 214 4 5 ... 629 .. ... ... ... 635 636 ... 10027 636 637 ... 4890 637 638 ... 3151 638 639 ... 3151 639 640 ... 5782 [640 rows x 118 columns]
दो राज्यों के बीच समानता का विश्लेषण
अब जब हमने डेटा एकत्र कर लिया है तो हम दो राज्यों के बीच विभिन्न मोर्चों पर समानताओं का विश्लेषण करने के लिए आगे बढ़ सकते हैं। समानताएं आयु समूह, कंप्यूटर स्वामित्व, आवास उपलब्धता, शिक्षा स्तर आदि के आधार पर हो सकती हैं। नीचे के उदाहरण में हम असम और आंध्र प्रदेश नामक दो राज्यों को लेते हैं। फिर हम दो राज्यों की तुलना समानता_मैट्रिक्स का उपयोग करके करते हैं। दोनों राज्यों के जिलों की प्रत्येक संभावित जोड़ी के लिए सभी डेटा फ़ील्ड की तुलना की जाती है। परिणामी हीटमैप इंगित करता है कि ये दोनों कितनी बारीकी से संबंधित हैं। छाया जितनी गहरी होगी, वे उतने ही करीब होंगे।
उदाहरण
import pandas as pd
import matplotlib.pyplot as plot
from matplotlib.colors import Normalize
import seaborn as sns
import math
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
df_ASSAM = datainput.loc[datainput['State name'] == 'ASSAM']
df_ANDHRA_PRADESH = datainput.loc[datainput['State name'] == 'ANDHRA PRADESH']
def segment(x1, x2):
# Set indices for both the data frames
x1.set_index('District code')
x2.set_index('District code')
# The similarity matrix of size len(x1) X len(x2)
similarity_matrix = []
# Iterate through rows of df1
for r1 in x1.iterrows():
# Create list to hold similarity score of row1 with other rows of x2
y = []
# Iterate through rows of x2
for r2 in x2.iterrows():
# Calculate sum of squared differences
n = 0
for c in list(datainput)[3:]:
maximum_c = max(datainput[c])
minimum_c = min(datainput[c])
n += pow((r1[1][c] - r2[1][c]) / (maximum_c - minimum_c), 2)
# Take sqrt and inverse the result
y.append(1 / math.sqrt(n))
# Append similarity scores
similarity_matrix.append(y)
p = 0
q = 0
r = 0
for m in range(len(similarity_matrix)):
for n in range(len(similarity_matrix[m])):
if (similarity_matrix[m][n] > p):
p = similarity_matrix[m][n]
q = m
r = n
print("%s from ASSAM and %s from ANDHRA PRADESH are most similar" % (x1['District name'].iloc[q],x2['District name'].iloc[r]))
return similarity_matrix
m = segment(df_ASSAM, df_ANDHRA_PRADESH)
normalization=Normalize()
s = plot.axes()
sns.heatmap(normalization(m), xticklabels=df_ANDHRA_PRADESH['District name'],yticklabels=df_ASSAM['District name'],linewidths=0.05,cmap='Oranges').set_title("similar districts matrix of assam AND andhra_pradesh")
plot.rcParams['figure.figsize'] = (20,20)
plot.show() आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
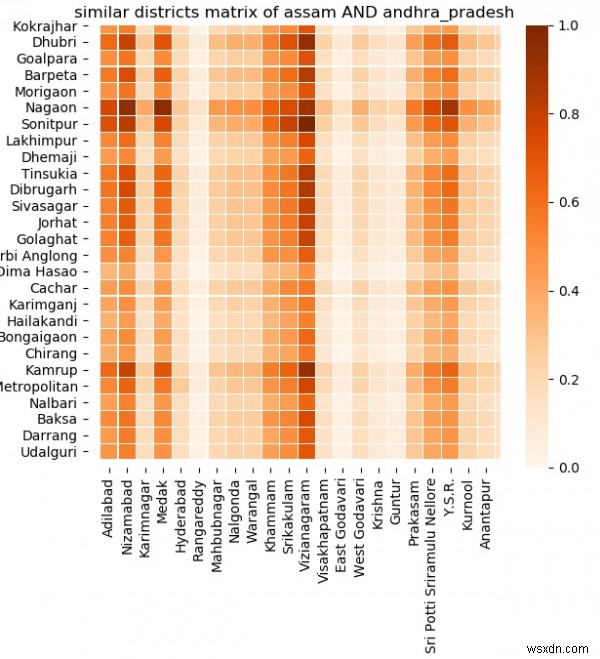
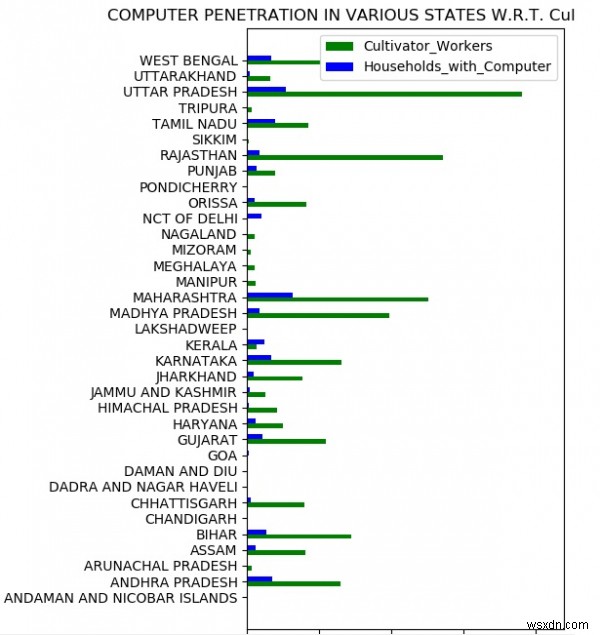
विशिष्ट पैरामीटर की तुलना करना
अब हम विशिष्ट मापदंडों के संबंध में स्थानों की तुलना भी कर सकते हैं। नीचे दिए गए उदाहरण में हम कृषक श्रमिकों के लिए उपलब्ध घरेलू कंप्यूटरों की उपलब्धता की तुलना करते हैं। हम ग्राफ तैयार करते हैं जो प्रत्येक राज्य के लिए इन दो मापदंडों के बीच तुलना को दर्शाता है।
उदाहरण
import pandas as pd
import matplotlib.pyplot as plot
from numpy import *
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
z = datainput.groupby(by="State name")
m = []
w = []
for k, g in z:
t = 0
t1 = 0
for r in g.iterrows():
t += r[1][36]
t1 += r[1][21]
m.append((k, t))
w.append((k, t1))
mp= pd.DataFrame({
'state': [x[0] for x in m],
'Households_with_Computer': [x[1] for x in m],
'Cultivator_Workers': [x[1] for x in w]})
d = arange(35)
wi = 0.3
fig, f = plot.subplots()
plot.xlim(0, 22000000)
r1 = f.barh(d, mp['Cultivator_Workers'], wi, color='g', align='center')
r2 = f.barh(d + wi, mp['Households_with_Computer'], wi, color='b', align='center')
f.set_xlabel('Population')
f.set_title('COMPUTER PENETRATION IN VARIOUS STATES W.R.T. Cultivator_Workers')
f.set_yticks(d + wi / 2)
f.set_yticklabels((x for x in mp['state']))
f.legend((r1[0], r2[0]), ('Cultivator_Workers', 'Households_with_Computer'))
plot.rcParams.update({'font.size': 15})
plot.rcParams['figure.figsize'] = (15, 15)
plot.show() आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -