सांख्यिकी एमएल और एआई सीखने के लिए मौलिक है। चूंकि इन तकनीकों के लिए पायथन पसंद की भाषा है, हम देखेंगे कि पायथन प्रोग्राम कैसे लिखना है जिसमें सांख्यिकीय विश्लेषण शामिल है। इस लेख में हम देखेंगे कि विभिन्न पायथन मॉड्यूल का उपयोग करके ग्राफ और चार्ट कैसे बनाया जाता है। विभिन्न प्रकार के चार्ट हमें डेटा का शीघ्रता से विश्लेषण करने में मदद करते हैं और इनसाइड प्राप्त करना ग्राफिक रूप से निष्कर्ष हैं।
डेटा तैयार करना
हम डेटा सेट लेते हैं जिसमें विभिन्न बीजों के बारे में डेटा होता है। यह डेटा सेट नीचे दिए गए प्रोग्राम में दिखाए गए लिंक में कागल पर उपलब्ध है। इसमें आठ स्तंभ हैं जिनका उपयोग विभिन्न बीजों की विशेषताओं की तुलना करने के लिए विभिन्न प्रकार के चार्ट बनाने के लिए किया जाएगा। नीचे दिया गया प्रोग्राम स्थानीय परिवेश से सेट किए गए डेटा को लोड करता है और पंक्तियों का एक नमूना प्रदर्शित करता है।
उदाहरण
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
datainput = pd.read_csv('E:\\seeds.csv')
#https://www.kaggle.com/jmcaro/wheat-seedsuci
print(datainput) आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
Area Perimeter Compactness ... Asymmetry.Coeff Kernel.Groove Type 0 15.26 14.84 0.8710 ... 2.221 5.220 1 1 14.88 14.57 0.8811 ... 1.018 4.956 1 2 14.29 14.09 0.9050 ... 2.699 4.825 1 3 13.84 13.94 0.8955 ... 2.259 4.805 1 4 16.14 14.99 0.9034 ... 1.355 5.175 1 .. ... ... ... ... ... ... ... 194 12.19 13.20 0.8783 ... 3.631 4.870 3 195 11.23 12.88 0.8511 ... 4.325 5.003 3 196 13.20 13.66 0.8883 ... 8.315 5.056 3 197 11.84 13.21 0.8521 ... 3.598 5.044 3 198 12.30 13.34 0.8684 ... 5.637 5.063 3 [199 rows x 8 columns]
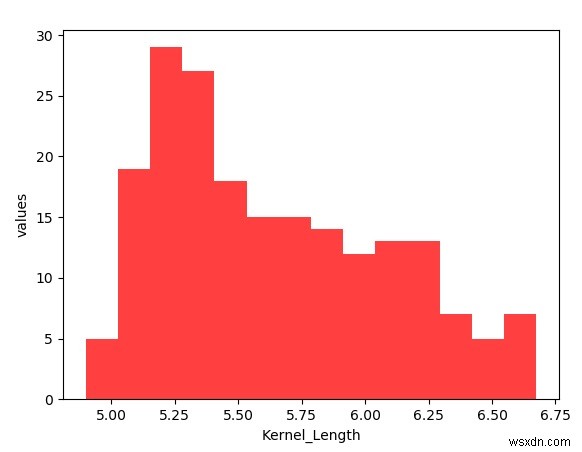
हिस्टोग्राम बनाना
हिस्टोग्राम बनाने के लिए हम csv फ़ाइल से हेडर पंक्ति को हटाते हैं और फ़ाइल को एक numpy array के रूप में पढ़ते हैं। फिर हम फ़ाइल को पढ़ने के लिए genfromtxt मॉड्यूल का उपयोग करते हैं। दायर की गई कर्नेल लंबाई सरणी में कॉलम इंडेक्स 3 के रूप में स्थित है। अंत में हम numpy द्वारा बनाए गए डेटा सेट का उपयोग करके हिस्टोग्राम को प्लॉट करने के लिए matplotlib का उपयोग करते हैं और आवश्यक लेबल भी लागू करते हैं।
उदाहरण
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\\seeds.csv', delimiter=',')
Kernel_Length = seed_data[:, [3]]
x = len(Kernel_Length)
y = np.sqrt(x)
y = int(y)
z = plot.hist(Kernel_Length, bins=y, color='#FF4040')
z = plot.xlabel('Kernel_Length')
z = plot.ylabel('values')
plot.show() आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
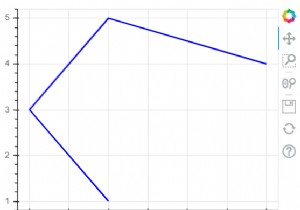
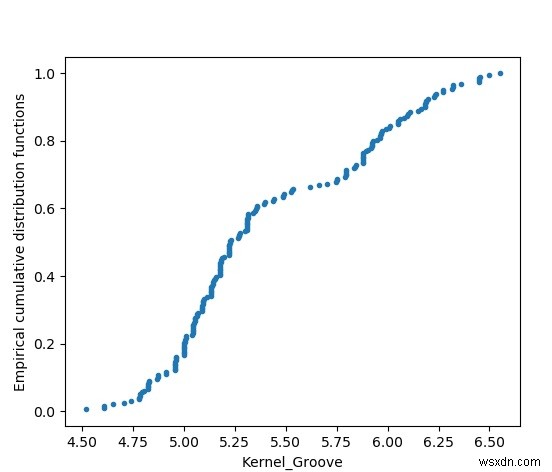
अनुभवजन्य संचयी वितरण कार्य
यह चार्ट डेटा सेट में वितरित कर्नेल ग्रूव आकार का प्लॉट दिखाता है। इसे कम से कम से सबसे बड़े मूल्य पर व्यवस्थित किया जाता है और इसे वितरण के रूप में दिखाया जाता है।
उदाहरण
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\\seeds.csv', delimiter=',')
Kernel_groove = seed_data[:, 6]
def ECDF(seed_data):#Empirical cumulative distribution functions
i = len(seed_data)
m = np.sort(seed_data)
n = np.arange(1, i + 1) / i
return m, n
m, n = ECDF(Kernel_groove)
plot.plot(m, n, marker='.', linestyle='none')
plot.xlabel('Kernel_Groove')
plot.ylabel('Empirical cumulative distribution functions')
plot.show() आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -
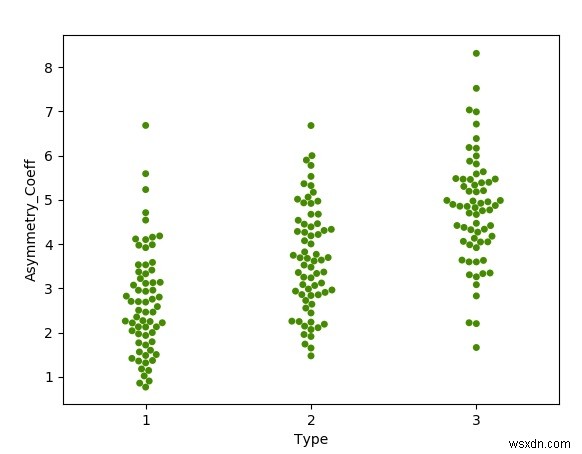
मधुमक्खी के झुंड के प्लॉट
एक मधुमक्खी का प्लॉट प्रत्येक व्यक्तिगत डेटा बिंदु को नेत्रहीन रूप से क्लस्टर करके डेटा बिंदुओं के समूह के आकार को दिखाता है। हम इस ग्राफ को बनाने के लिए सीबॉर्न लाइब्रेरी का उपयोग करते हैं। हम डेटा सेट से टाइप कॉलम का उपयोग समान प्रकार के बीजों को एक साथ क्लस्टर करने के लिए करते हैं।
उदाहरण
import pandas as pd
import matplotlib.pyplot as plot
import seaborn as sns
datainput = pd.read_csv('E:\\seeds.csv')
sns.swarmplot(x='Type', y='Asymmetry.Coeff',data=datainput, color='#458B00')#bee swarm plot
plot.xlabel('Type')
plot.ylabel('Asymmetry_Coeff')
plot.show() आउटपुट
उपरोक्त कोड को चलाने से हमें निम्नलिखित परिणाम मिलते हैं -